本文主要是介绍图像检索:Where to Buy It: Matching Street Clothing Photos in Online Shops,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
intro: ICCV 2015
hmepage: http://www.tamaraberg.com/street2shop/
paper: http://www.tamaraberg.com/papers/street2shop.pdf
paper: http://www.cv-foundation.org/openaccess/content_iccv_2015/html/Kiapour_Where_to_Buy_ICCV_2015_paper.html
这篇论文的目标就是要根据街拍图准确找出卖家图。
该论文的主要贡献有:
1. 开源了一个street2shop数据集;
2. 根据深度学习提取到的服装特征,又训练了一个计算相似度的小网络;
3. 不仅用算法检索评估测试,还组织了人类检索评估测试;
A. 数据集street2shop
总共收集了11类商品的图片,包含(bags,belts,dresses,eyewear,footwear,hats,leggings,outerwear,pants,skirts,和tops);
从25个网上零售店收集了404,683张shop photos,和20,358street photos, 39,479对street shop matches;
根据给的图片url将dresses,outerwear,tops下载下来看了看,很不理想,很多item只有一张图片,有多张图片的item,服饰搭配,角度,光线遮挡等问题也很严重,有些甚至人都不好区分。
B. 算法模型
算法的输入的street photo就是一张标记好类别和bbox的照片, 而shop photo是没有类别和bbox标注的。
一个baseline是基于shop photo的整图做检索,也就是用了ImageNet效果还不错的模型作为特征提取器,提取shop的整图特征,提取street的bbox里图的特征,然后用cosine距离计算相似度,相似度从大到小排序,得检索结果。感觉这种方式脚趾头想效果也不能好了。。。
另一个baseline是采用selective search method在shop中提取候选框,特征计算和比对同baseline 1
后面本文提出的呢,就是用三个FC层的network来代替consine相似度的计算。
训练数据的positive pairs主要就是选取street和shop指向同一商品的图片里,shop图片上使用baseline2比对结果topN的区域图提取的特征与street bbox图提取的特征组成pair,negative pairs就是street和shop指向不同款的图片
先训练了一个适用于所有类别的通用相似度计算模型,然后针对不同类别,分别finetuning出各类别的相似度计算模型。
敲黑板:作者使用了几种检索方法: 作者首先训练了一个广义的相似度模型,然后对每类衣物微调,得到类别独立的模型: |
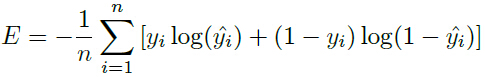

C. 实验结果
算法实验结果,实在是不怎么理想,参照下图


人类检索结果,任务与算法的稍有不同,给出一张图和10个比较相似的候选,从中选出与那张图相同的。不过做同样任务的时候,人的准确度还是比算法的高很多,还有很高的提升空间。
Consider dresses,where our algorithm does relatively well, picking the correct item in the top 10 in 33.5% of trials and getting the first item correct in 15.6%. In our human experiments, people pick the correct item out of 10 choices 87% of the time for dresses, which is significantly better.

这篇关于图像检索:Where to Buy It: Matching Street Clothing Photos in Online Shops的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







