本文主要是介绍第T5周:运动鞋品牌识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
训练过程心得
这次加入了早停和指数变化学习率,确实是很有用的方法,但是最开始自己设置参数时,总感觉教案设置的学习率太大(虽然后面公布答案就是改的学习率)。但最开始我没有改学习率,而是把decay_rate调的很小(后来发现不太合适……)。然后一直在改参数,果然使用Adam优化器还是不能把学习率弄高了。当然还有本身数据集就很小的原因在……突然又想起来batch_size好像挺大的,又改成了16。嗯,感觉好多了。然后就是最后那里看到图像尺寸不对后倒回去改图像尺寸。?!改了图像尺寸过后的训练正确率从第二个开始一直卡在50%连续十几个,这是怎么回事?赶紧回去查查。然后把decay_steps调大了,学习率还是旋0.001吧,再将decay_rate改为0.8又不断的调参,这次还行。
一、前期工作
1.设置GPU
from tensorflow import keras
from tensorflow.keras import layers,models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")gpus
2.导入数据
data_dir = "./P5/"data_dir = pathlib.Path(data_dir)
3. 查看数据
image_count = len(list(data_dir.glob('*/*/*.jpg')))print("图片总数为:",image_count)
输出
图片总数为: 578
roses = list(data_dir.glob('train/nike/*.jpg'))
PIL.Image.open(str(roses[6]))
输出

二、数据预处理
1.加载数据
batch_size = 16
img_height = 240
img_width = 240
train_ds = tf.keras.preprocessing.image_dataset_from_directory("./P5/train/",seed=123,shuffle=True,image_size=(img_height, img_width),batch_size=batch_size)
输出
Found 502 files belonging to 2 classes.
val_ds = tf.keras.preprocessing.image_dataset_from_directory("./P5/test/",seed=123,shuffle=True,image_size=(img_height, img_width),batch_size=batch_size)
输出
Found 76 files belonging to 2 classes.
class_names = train_ds.class_names
print(class_names)
输出
[‘adidas’, ‘nike’]
2.可视化数据
plt.figure(figsize=(20, 10))for images, labels in train_ds.take(1):for i in range(20):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")
输出

3.再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
输出
(16, 240, 240, 3)
(16,)
4.配置数据集
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、构建CNN网络
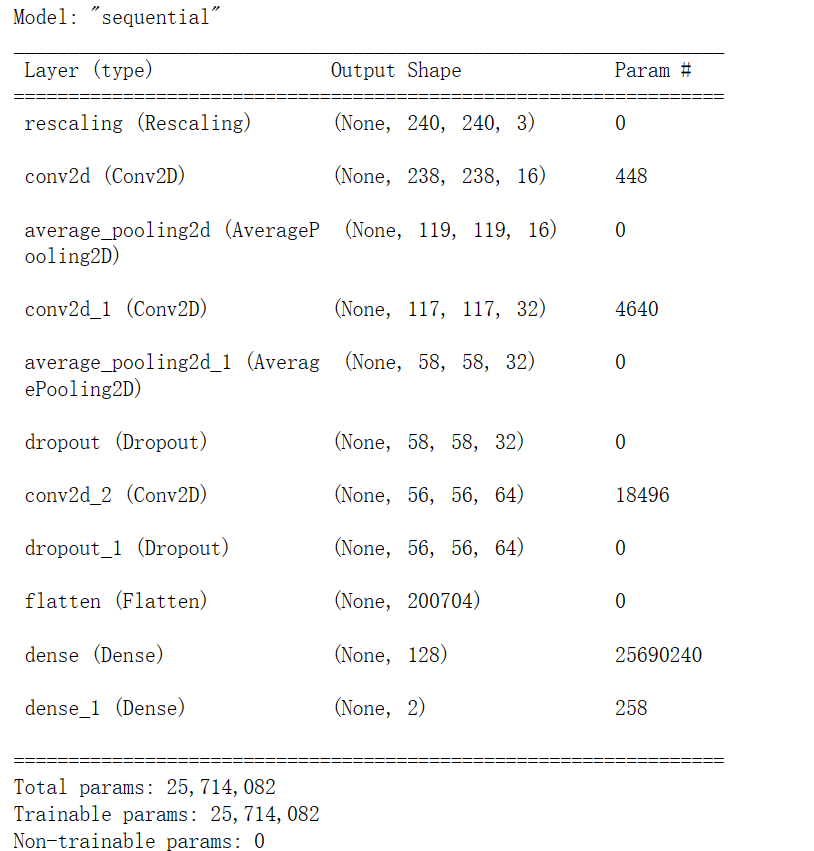
model = models.Sequential([layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), layers.AveragePooling2D((2, 2)), layers.Conv2D(32, (3, 3), activation='relu'), layers.AveragePooling2D((2, 2)), layers.Dropout(0.3), layers.Conv2D(64, (3, 3), activation='relu'), layers.Dropout(0.3), layers.Flatten(), layers.Dense(128, activation='relu'), layers.Dense(len(class_names))
])model.summary()
输出
四、训练模型
1.设置动态学习率
代码知识点
在深度学习训练模型中,steps和epochs是两个经常被提及的概念,它们具有不同的含义和作用。
Epoch(时期): 一个epoch表示数据集通过了神经网络一次并且返回了一次。具体来说,当所有训练样本在神经网络中都进行了一次正向传播和一次反向传播后,这个过程被称为一次epoch。换句话说,一个epoch表示过了1遍训练集中的所有样本。
Iteration(迭代/训练步): 表示1次迭代,也称为training step。每次迭代都会更新网络结构的参数。在深度学习中,通常采用随机梯度下降(SGD)训练,即每次训练在训练集中取batch
size个样本进行训练。因此,iteration的数量通常会比epoch的数量要多得多。
tf.keras.optimizers.schedules.ExponentialDecay是一个用于设置学习率衰减的函数。在深度学习训练过程中,随着训练的进行,模型参数需要不断更新以最小化损失函数。然而,随着训练的深入,模型参数的变化速度可能会变得非常快,导致学习率过高,从而影响模型的训练效果。因此,为了解决这个问题,可以使用学习率衰减策略来逐渐降低学习率。ExponentialDecay函数的参数如下:
1. initial_learning_rate:浮点数,表示初始学习率。 decay_steps:整数,表示每隔多少步进行一次衰减。
2. decay_rate:浮点数,表示衰减率。
3. staircase:布尔值,默认为False。如果为True,则学习率将在离散的时间步上衰减;如果为False,则学习率将在连续的时间步上衰减。
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule):这行代码创建了一个Adam优化器,并将之前创建的指数衰减学习率调度器作为学习率传入。
model.compile(optimizer=optimizer,:这行代码将之前创建的Adam优化器编译到模型中。
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),:这是编译模型时的损失函数,使用了稀疏分类交叉熵损失函数。from_logits=True表示模型输出的是未经过softmax处理的概率值。
metrics=['accuracy']):这是编译模型时的评估指标,这里选择了准确率(accuracy)。
# 设置初始学习率
initial_learning_rate = 0.001lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate, decay_steps=16, decay_rate=0.8, # lr经过一次衰减就会变成 decay_rate*lrstaircase=True)# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)model.compile(optimizer=optimizer,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
2.早停与保存最佳模型参数
代码知识点
这行代码创建了一个EarlyStopping对象,用于在验证集上的准确性不再提高时提前终止训练。具体来说,它设置了以下参数:
monitor:监控指标,这里设置为’val_accuracy’,表示在验证集上的准确性作为监控指标。
min_delta:最小变化量,这里设置为0.003,表示当验证集上的准确性变化小于这个值时,认为已经达到了停止训练的条件。
patience:容忍度,这里设置为5,表示如果在连续5个训练周期内验证集上的准确性没有提高,就触发提前终止训练。
verbose:日志级别,这里设置为1,表示输出详细的日志信息。
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStoppingepochs = 35checkpointer = ModelCheckpoint('best_model.h5',monitor='val_accuracy',verbose=1,save_best_only=True,save_weights_only=True)earlystopper = EarlyStopping(monitor='val_accuracy', min_delta=0.003,patience=5, verbose=1)
3.模型训练
代码知识点
model.fit():这是Keras中用于训练模型的函数。它接受以下参数:
train_ds:训练数据集,通常是一个包含输入数据和标签的TensorFlow数据集对象。validation_data:验证数据集,用于在训练过程中评估模型的性能。通常也是一个TensorFlow数据集对象。
epochs:训练的轮数,即在整个训练集上迭代的次数。
callbacks:回调函数列表,用于在训练过程中执行特定的操作,如保存模型、调整学习率等。
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[checkpointer, earlystopper])
输出
Epoch 1/35
32/32 [] - ETA: 0s - loss: 0.6932 - accuracy: 0.5319
Epoch 1: val_accuracy improved from -inf to 0.50000, saving model to best_model.h5
32/32 [] - 10s 277ms/step - loss: 0.6932 - accuracy: 0.5319 - val_loss: 0.6596 - val_accuracy: 0.5000
Epoch 2/35
32/32 [] - ETA: 0s - loss: 0.6712 - accuracy: 0.5339
Epoch 2: val_accuracy improved from 0.50000 to 0.51316, saving model to best_model.h5
32/32 [] - 9s 296ms/step - loss: 0.6712 - accuracy: 0.5339 - val_loss: 0.6544 - val_accuracy: 0.5132
Epoch 3/35
32/32 [] - ETA: 0s - loss: 0.6540 - accuracy: 0.5837
Epoch 3: val_accuracy improved from 0.51316 to 0.57895, saving model to best_model.h5
32/32 [] - 8s 258ms/step - loss: 0.6540 - accuracy: 0.5837 - val_loss: 0.6392 - val_accuracy: 0.5789
Epoch 4/35
32/32 [] - ETA: 0s - loss: 0.6233 - accuracy: 0.6394
Epoch 4: val_accuracy improved from 0.57895 to 0.67105, saving model to best_model.h5
32/32 [] - 8s 257ms/step - loss: 0.6233 - accuracy: 0.6394 - val_loss: 0.6183 - val_accuracy: 0.6711
Epoch 5/35
32/32 [] - ETA: 0s - loss: 0.6034 - accuracy: 0.6514
Epoch 5: val_accuracy did not improve from 0.67105
32/32 [] - 9s 273ms/step - loss: 0.6034 - accuracy: 0.6514 - val_loss: 0.6201 - val_accuracy: 0.6579
Epoch 6/35
32/32 [] - ETA: 0s - loss: 0.5845 - accuracy: 0.6733
Epoch 6: val_accuracy did not improve from 0.67105
32/32 [] - 8s 246ms/step - loss: 0.5845 - accuracy: 0.6733 - val_loss: 0.6040 - val_accuracy: 0.6711
Epoch 7/35
32/32 [] - ETA: 0s - loss: 0.5720 - accuracy: 0.7072
Epoch 7: val_accuracy did not improve from 0.67105
32/32 [] - 8s 264ms/step - loss: 0.5720 - accuracy: 0.7072 - val_loss: 0.6109 - val_accuracy: 0.6316
Epoch 8/35
32/32 [] - ETA: 0s - loss: 0.5672 - accuracy: 0.7251
Epoch 8: val_accuracy did not improve from 0.67105
32/32 [] - 10s 299ms/step - loss: 0.5672 - accuracy: 0.7251 - val_loss: 0.6035 - val_accuracy: 0.6579
Epoch 9/35
32/32 [] - ETA: 0s - loss: 0.5590 - accuracy: 0.7291
Epoch 9: val_accuracy did not improve from 0.67105
32/32 [] - 8s 253ms/step - loss: 0.5590 - accuracy: 0.7291 - val_loss: 0.6046 - val_accuracy: 0.6711
Epoch 10/35
32/32 [] - ETA: 0s - loss: 0.5562 - accuracy: 0.7410
Epoch 10: val_accuracy did not improve from 0.67105
32/32 [] - 8s 254ms/step - loss: 0.5562 - accuracy: 0.7410 - val_loss: 0.6041 - val_accuracy: 0.6711
Epoch 11/35
32/32 [] - ETA: 0s - loss: 0.5531 - accuracy: 0.7410
Epoch 11: val_accuracy did not improve from 0.67105
32/32 [] - 8s 249ms/step - loss: 0.5531 - accuracy: 0.7410 - val_loss: 0.6034 - val_accuracy: 0.6711
Epoch 12/35
32/32 [] - ETA: 0s - loss: 0.5498 - accuracy: 0.7311
Epoch 12: val_accuracy did not improve from 0.67105
32/32 [] - 9s 270ms/step - loss: 0.5498 - accuracy: 0.7311 - val_loss: 0.6043 - val_accuracy: 0.6579
Epoch 13/35
32/32 [] - ETA: 0s - loss: 0.5504 - accuracy: 0.7450
Epoch 13: val_accuracy did not improve from 0.67105
32/32 [] - 8s 253ms/step - loss: 0.5504 - accuracy: 0.7450 - val_loss: 0.6024 - val_accuracy: 0.6711
Epoch 14/35
32/32 [] - ETA: 0s - loss: 0.5494 - accuracy: 0.7470
Epoch 14: val_accuracy did not improve from 0.67105
32/32 [] - 8s 244ms/step - loss: 0.5494 - accuracy: 0.7470 - val_loss: 0.6028 - val_accuracy: 0.6711
Epoch 15/35
32/32 [] - ETA: 0s - loss: 0.5490 - accuracy: 0.7450
Epoch 15: val_accuracy did not improve from 0.67105
32/32 [] - 8s 235ms/step - loss: 0.5490 - accuracy: 0.7450 - val_loss: 0.6029 - val_accuracy: 0.6711
Epoch 16/35
32/32 [] - ETA: 0s - loss: 0.5489 - accuracy: 0.7410
Epoch 16: val_accuracy did not improve from 0.67105
32/32 [] - 8s 257ms/step - loss: 0.5489 - accuracy: 0.7410 - val_loss: 0.6031 - val_accuracy: 0.6711
Epoch 17/35
32/32 [] - ETA: 0s - loss: 0.5489 - accuracy: 0.7390
Epoch 17: val_accuracy did not improve from 0.67105
32/32 [] - 8s 247ms/step - loss: 0.5489 - accuracy: 0.7390 - val_loss: 0.6031 - val_accuracy: 0.6711
Epoch 18/35
32/32 [] - ETA: 0s - loss: 0.5481 - accuracy: 0.7450
Epoch 18: val_accuracy did not improve from 0.67105
32/32 [] - 8s 236ms/step - loss: 0.5481 - accuracy: 0.7450 - val_loss: 0.6031 - val_accuracy: 0.6711
Epoch 19/35
32/32 [] - ETA: 0s - loss: 0.5478 - accuracy: 0.7450
Epoch 19: val_accuracy did not improve from 0.67105
32/32 [] - 7s 233ms/step - loss: 0.5478 - accuracy: 0.7450 - val_loss: 0.6031 - val_accuracy: 0.6711
Epoch 19: early stopping
五、模型评估
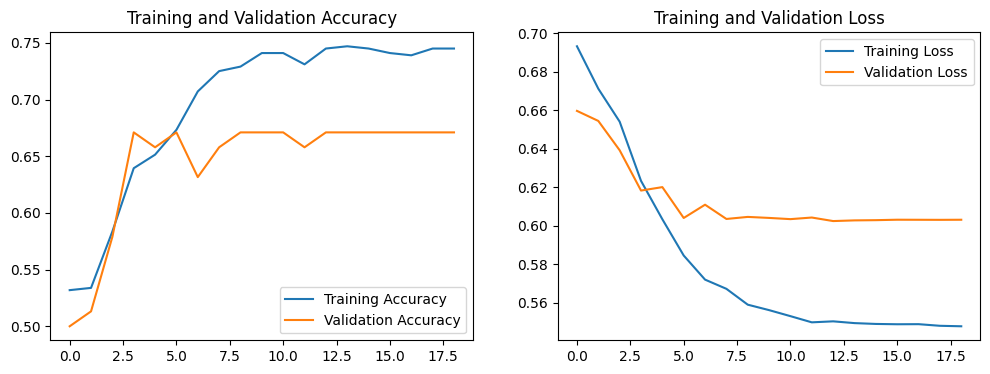
1.Loss与Acurracy图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(len(loss))plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
输出
2.指定图片进行预测
model.load_weights('best_model.h5')
from PIL import Image
import numpy as npimage = Image.open("./P5/test/nike/0.jpg").convert("RGB")numpy_image = np.array(image)tensor_image = tf.convert_to_tensor(numpy_image, dtype=tf.float32) img_array = tf.expand_dims(tensor_image, 0)/255.0 predictions = model.predict(img_array)
print("预测结果为:",class_names[np.argmax(predictions)])
输出
1/1 [==============================] - 0s 143ms/step
预测结果为: nike
这篇关于第T5周:运动鞋品牌识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







