本文主要是介绍【论文解读】Uncertainty Quantification of Collaborative Detection for Self-Driving,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Uncertainty Quantification of Collaborative Detection for Self-Driving
- 摘要
- 引言
- 方法
- 问题定义
- 方法概览
- Double-M
- 实验
- 结论
摘要
在联网和自动驾驶汽车(CAVs)之间共享信息从根本上提高了自动驾驶协同目标检测的性能。然而,由于实际挑战,CAV 在目标检测方面仍然存在不确定性,这将影响自动驾驶中的后续模块,例如规划和控制。因此,不确定性量化对于 CAV 等安全关键系统至关重要。我们的工作是第一个估计协作目标检测的不确定性的工作。我们提出了一种新的不确定性量化方法,称为双 M 量化,它通过直接建模边界框每个角的多变量高斯分布来调整移动块引导 (MBB) 算法。我们的方法通过基于离线双 M 训练过程的一次推理传递来捕获认知不确定性和任意不确定性。它可以用于不同的协作对象检测器。通过对综合协同感知数据集进行了实验,我们表明与最先进的不确定性量化方法相比,我们的 Double-M 方法在不确定性得分上提高了 4× 以上,准确率提高了 3% 以上。我们的代码在 https://coperception.github.io/double-m-quantification/
引言
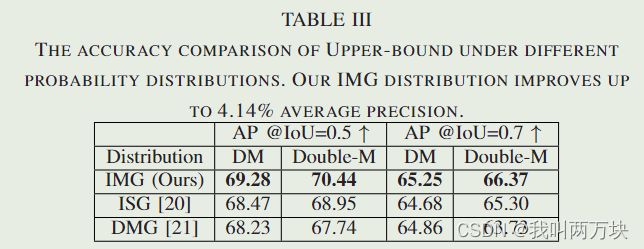
在本文中,我们提出了一种新的用于协同目标检测的不确定性量化方法,称为DoubleM量化(直接建模移动块自举量化),它只需要一个推理通道即可捕获认知和任意不确定性。我们的方法为每个检测到的目标构建的不确定性集有助于后续模块完成自动驾驶任务,如不确定性传播的轨迹预测[25]和鲁棒规划与控制[26],[27]。从图1可以看出,采用我们的不确定性量化方法,检测精度低的目标往往具有较大的不确定性,构建的不确定性集在大多数情况下覆盖了ground-truth bounding box。与目前的现状[20],[21]相比,我们的Double-M Quantification方法在综合协同感知数据集V2X-SIM上的不确定性评分提高了4倍,准确率提高了3.04%[1]。
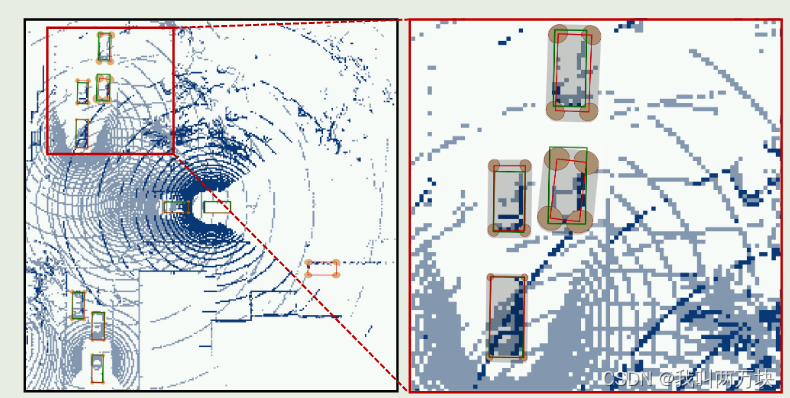
图1:左图为鸟瞰图(BEV)中间协同的检测结果,右图对特定部分进行放大,显示两种检测的鲁棒范围。红框代表预测,绿框代表事实。橙色椭圆表示每个角的协方差。阴影凸包表示被检测对象的不确定性集。在大多数情况下,阴影凸包覆盖绿色边界框,这有助于后续模块完成自动驾驶任务,如不确定性传播的轨迹预测[25]和鲁棒规划与控制[26],[27]。采用我们的Double-M量化方法,检测精度低的目标往往具有较大的不确定性。
我们的贡献:
1)据我们所知,我们提出的Double-M量化是第一次尝试估计协同目标检测的不确定性。我们的方法定制了一种移动块自举算法来估计。在一个推理过程中,认知不确定性和任意不确定性同时存在。
2)设计了一种新的直接建模分量中边界盒不确定性的表示格式,以估计任意不确定性。我们将边界框的每个角视为一个独立的多变高斯分布,每个角的协方差矩阵由一个输出头估计,而现有文献主要假设每个角的每个维度都是单变高斯分布或所有角都是高维高斯分布。
3)我们验证了基于V2X-SIM[1]的方法的优势,并表明我们的双m量化方法减少了不确定性,提高了精度。结果还验证了在自动驾驶汽车之间共享中间特征信息有利于系统提高准确性和减少不确定性。
方法
在本节中,我们首先定义了协作目标检测的不确定性量化问题。然后,我们描述了我们的新型DoubleM量化(直接建模移动块自举量化)方法的总体结构,如图2所示,然后是详细的算法过程。最后,我们定义了神经网络模型的损失函数。一个主要的新颖之处是首次定制了移动块引导34算法,以解决协作对象检测的不确定性量化挑战,并在离线训练过程中通过一次推理来估计认知和任意不确定性。该算法不依赖于特定的神经网络模型或结构,可以与不同的协作对象检测器(如DiscoNet[1])一起使用。相应的损失函数同时考虑预测精度和协方差作为度量
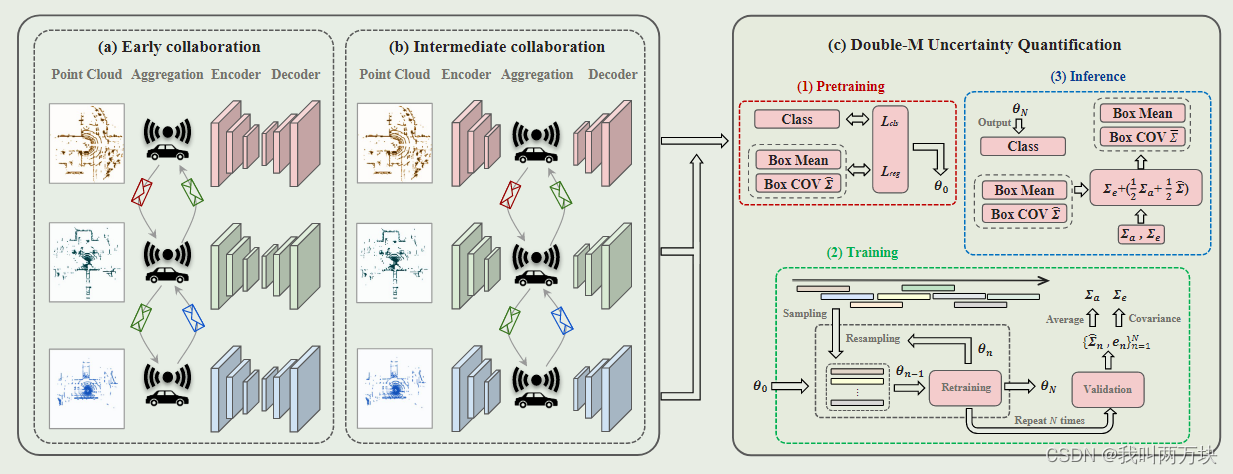
图2所示:协同目标检测的双m量化方法。(a)早期协作与其他代理共享原始点云,(b)中间协作与其他代理共享中间特征表示。©双m量化方法估计每个角的多变量高斯分布。我们的双m量化方法可用于不同的协同目标检测。在训练阶段,Double-M Quantification定制了一种移动块自举算法来获得最终的模型参数,Σa作为验证数据集的平均任意不确定性,Σe作为所有残差向量的协方差,用于认知不确定性。在推理阶段,将Σa、Σe与目标检测器预测的协方差矩阵↓Σ结合,计算出分布的协方差矩阵↓Σ = Σe + (1 2 Σa + 1 2↑Σ)
问题定义
在每个点云数据X中,有J个对象。对于每个对象j∈{1,…, J},我们建议预测边界框的I个角。每个角i∈{1,…, I}由BEV映射中的d维向量表示。真实的边界框集合Y表示为Y ={cj, {yij}I I =1}J J =1,其中c是分类标签,而yij∈RD,∀(I, J)。预测边界框集合y表示为y ={pj, {yj, {Σij}I I =1}J J =1,其中p是预测分类概率,将边界框的每个角建模为多元高斯分布。这里,我们假设边界框的每个角的概率分布是独立的。在训练过程中,通过最小化检测损失Ldet(Y, Y^)来共同学习编码器E、聚合器和解码器D的神经网络参数,Ldet(Y, Y^)包括分类损失和考虑预测准确性和不确定性的回归损失。
方法概览
我们设计了一种新的不确定性量化方法,称为直接建模移动块自举量化(Double-M量化),通过将MBB算法与DM方法相结合来估计认知和任意不确定性。双m量化在协同目标检测上的概述如图2所示。在训练阶段,我们在重采样的运动块上训练目标检测器。经过N次bootstrap,我们得到目标检测器f θ(其中,θ为最终模型参数),计算验证数据集的平均任意不确定性Σa,计算所有残差向量的认知不确定性协方差Σe。在推理阶段,我们以输入点云X为例,结合Σa、Σe和f θ (X)的预测协方差矩阵- Σij,计算多元高斯分布的协方差矩阵- Σij = Σe +(1 2 Σa + 1 2 Σij)。
【bootstrap】Bootstrap 是一种统计方法,通过从原始数据集中抽取多个样本并对这些样本进行重新采样,以生成多个训练集。这些训练集会用于训练多个模型,从而生成多个预测结果。这种方法可以用于评估模型的稳定性和鲁棒性,以及估算预测误差。
Double-M
Monte-Carlo dropout[23]和deep ensembles[24]被用来估计认知不确定性。然而,它们都没有考虑数据集中的时间序列特征,而时间特征对cav来说很重要。我们设计了一种新的不确定性量化方法,称为Double-M量化,用于在考虑数据集中的时间特征时估计认知和任意不确定性。特别是,我们的设计在时间序列数据上定制了一个移动块引导[34]过程,该过程通过在训练过程中从构建的数据块中采样数据来捕获数据内的自相关性。
在算法1中给出了双m量化方法的训练阶段。

- 我们首先初始化协同目标检测器的参数θ,并使用训练数据集对模型进行预训练。然后,我们从包含K帧的时间序列训练数据etdk中构造定长时间序列块集B,注意,块集b通过保持同一块内帧的顺序来保持时间特性 (参见第2行)
- 然后,在每次迭代中,我们使用采样数据集重新训练模型,该数据集包含M个从块集B中以替换和均匀随机概率采样的块 (参见第4-5行)。
- 在每个训练迭代n的最后一步,我们在验证数据集VK′上测试保留的模型fθn (见第6行),并将残差向量计算为地面实况向量yijk和预测的平均向量vx yijk之间的差,∀i∈[1,i],j∈[1],j],k∈[1、k′](见第7行)
经过N次迭代后,我们得到了最终的模型参数θ,以通过模型f θ来预测协方差。除了最终训练的模型之外,我们还通过使用验证数据集的残差和预测协方差矩阵来估计算术和认知的不确定性。我们首先通过计算∑a来估计算术不确定性,∑a是所有预测协方差矩阵的平均值。为了估计认知不确定性,我们计算所有残差向量的协方差矩阵,用∑e表示。
一方面,我们的双M量化方法通过对验证数据集上N次迭代的多个模型进行聚合,提供了袋装算术不确定性估计。另一方面,它近似残差的误差分布,以便我们可以量化认识上的不确定性。
我们的双m量化方法的推理阶段如算法2所示

实验
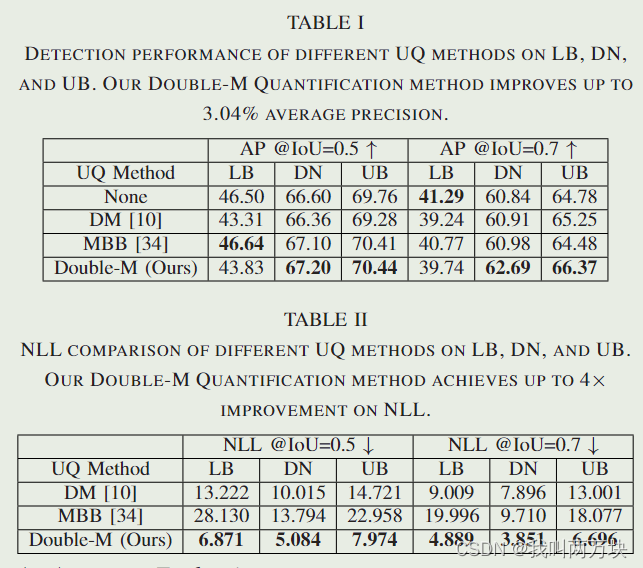
1)下限(LB)[1]:不需要协作的单个目标探测器,只使用单个激光雷达的点云数据。
2) DiscoNet (DN)[2]:中间协同目标检测器,利用边缘权值为矩阵值的有向图,通过抑制噪声空间区域,增强信息区域,自适应聚合不同agent的特征。它通过共享紧凑和上下文感知的场景表示,显示了良好的性能-带宽权衡。
3)上界(UB)[1]:早期协同目标检测器使用来自所有联网车辆的原始点云数据,如图2(a)所示。它通常具有良好的信息无损性能,但占用较高的通信带宽。
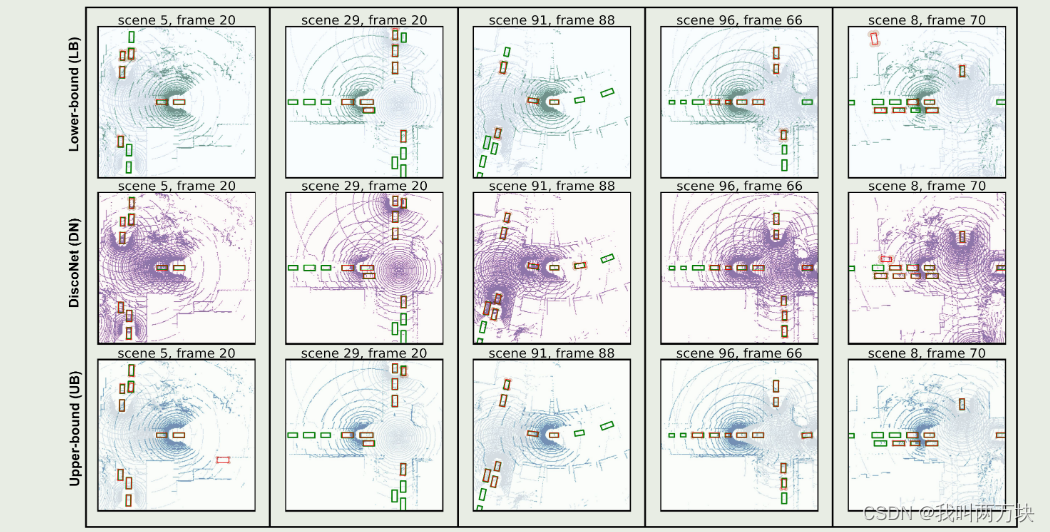
图3所示。我们的双m量化结果在V2X-Sim不同场景下的可视化[1]。LB、DN和UB的结果分别显示在第一行、第二行和第三行。红框代表预测,绿框代表事实。橙色椭圆表示每个角的协方差。我们可以看到,当红色边界框和对应的绿色边界框之间的差异很大时,我们的Double-M Quantification预测了较大的橙色椭圆,这意味着我们的方法是有效的。例如,在场景29第20帧的DiscoNet子图中,对于右上方的对象O1,红色和绿色边界框之间的差异很大,因此Double-M Quantification预测出较大的橙色椭圆。对于O1左侧的三个对象,它们的红色和绿色边界框之间的差异很小,因此Double-M量化预测了小的橙色椭圆
结论
这项工作提出了首次尝试估计协作目标检测的不确定性。本文提出了一种新的不确定性量化方法,即双不确定性量化方法,可以通过一次推理同时预测认知不确定性和任意不确定性。关键的新颖之处是定制的移动块引导训练过程,以及为边界盒的每个角估计一个独立的多变量高斯分布的损失函数设计。在不同的协同目标检测器上验证了我们的不确定度量化方法。实验表明,该方法具有较好的不确定度估计和精度。在未来,我们将把我们的方法应用于更多的协同感知数据集,并通过不确定性量化来提高轨迹预测的性能。
这篇关于【论文解读】Uncertainty Quantification of Collaborative Detection for Self-Driving的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




