本文主要是介绍MLP-Mixer: AN all MLP Architecture for Vision,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 发表于NeurIPS 2021, 由Google Research, Brain Team发表。
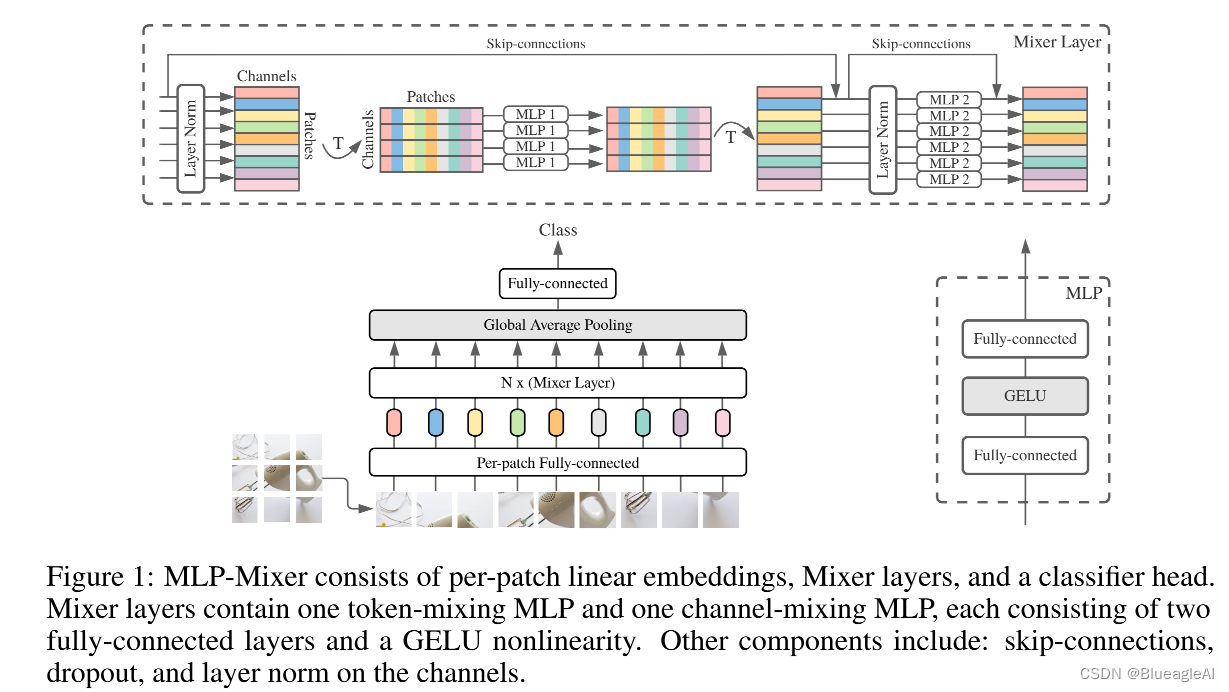
Mixer Architecture
Introduction
- 当前的深度视觉结构包含融合特征(mix features)的层:(i)在一个给定的空间位置融合。(ii)在不同的空间位置,或者一次融合所有。
- 在CNN中,(ii) 是由N x N(N > 1 )卷积和池化完成的。更深的神经元有更深的感受野。同时 1 x 1的卷积完成了(i)。
- 在 Vision Transformer和其他基于attention-based architectures,自监督层同时做到了(i)和(ii), 而MLP-blocks 做到了(i)。
- 因此Mixer architecture的内在思想是去清晰区分per-location(channel-mixing) 操作(i) 以及cross-location(token-mixing)operations(ii)。这些操作都由MLPs完成。
Steps
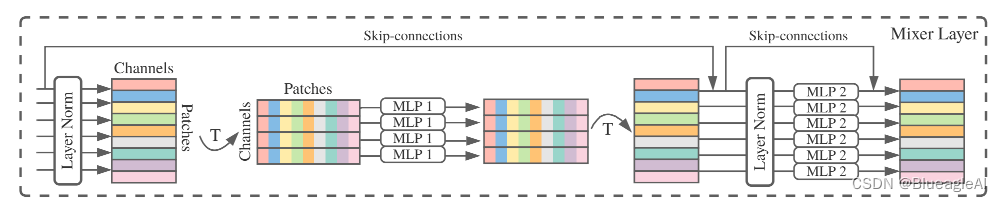
- Mixer的输入是S个无重叠的图像块,每一块投影成维度C的隐层,也就是一个二维真值输入表, X ∈ R S × C X \in \mathbb{R}^{S \times C} X∈RS×C。 S维度就代表空间,C代表同一空间位置的不同特征。
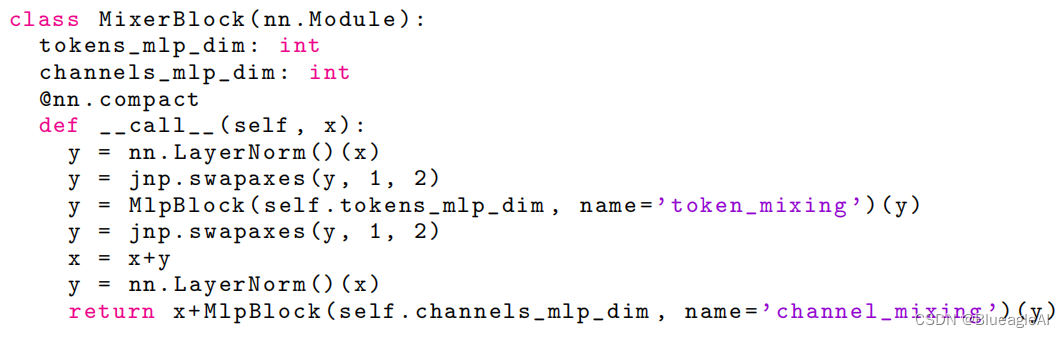
- Mixer 包括同一尺寸的多层,每层包含两个MLP块。第一个是token-mixing MLP:作用于X的列(通过将X转置 X T X^T XT)。第二个是channel-mixing MLP:作用于行。
- 每一个模块包含两个全连接层和一个非线性层。
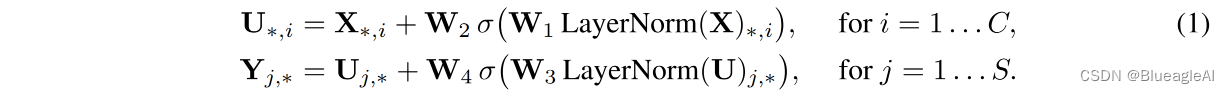
这篇关于MLP-Mixer: AN all MLP Architecture for Vision的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![【课程笔记】谭平计算机视觉(Computer Vision)[5]:反射和光照 - Reflectance Lighting](https://i-blog.csdnimg.cn/blog_migrate/605975d30e1d112f02269197ccfca1e1.png)