本文主要是介绍Fisher线性分类器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.Fisher线性判别
- 基本原理:
- 最佳W值的确定:
- 阈值的确定
- Fisher线性判别的决策规则
- “群内离散度”与“群间离散度”
- 2.Python代码
- 参考文章
1.Fisher线性判别
线性判别分析是一种经典的线性学习方法,其思想:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异样样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别
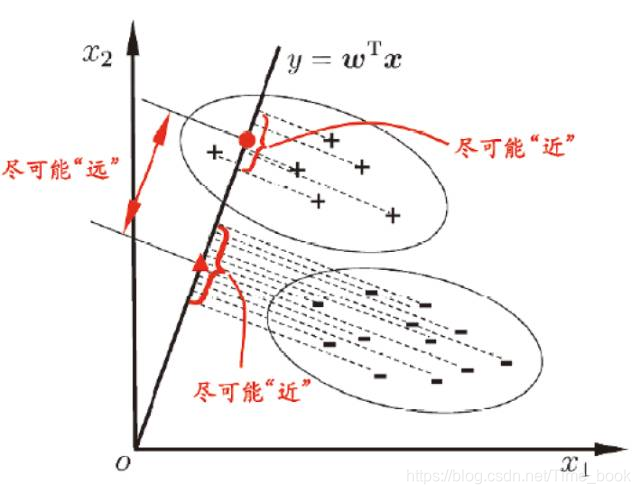
基本原理:
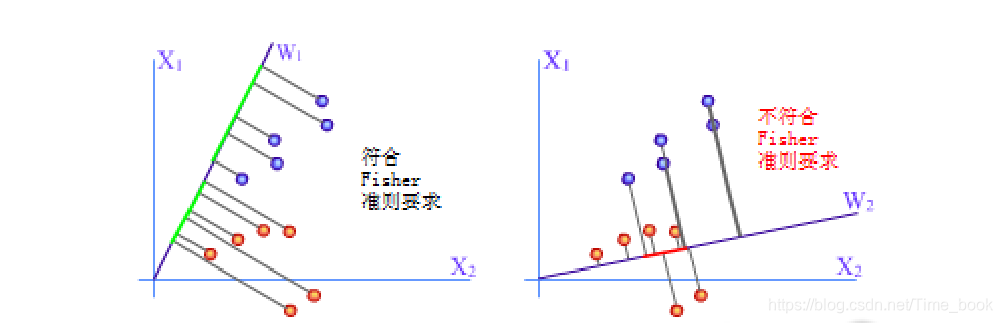
分析w1方向之所以比w2方向优越,可以归纳出这样一个准则,即向量w的方向选择应能使两类样本投影的均值之差尽可能大些,而使类内样本的离散程度尽可能小。这就是Fisher准则函数的基本思路。
Fisher准则的基本原理,就是要找到一个最合适的投影轴,使两类样本在该轴上投影的交迭部分最少,从而使分类效果为最佳。
最佳W值的确定:
最佳w值的确定实际上就是对Fisher准则函数求取其达极大值时的。
对于这个问题可以采用拉格朗日乘子算法解决,保持分母为一非零常数c的条件下,求其分子项的极大值。
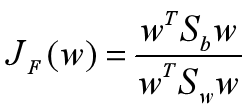

这个函数称为Fisher准则函数。应该寻找使分子尽可能大,分母尽可能小的w作为投影向量。
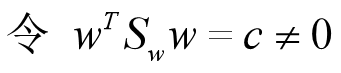
定义函数Lagrange函数:
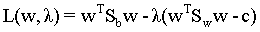
对拉格朗日函数分别对w求偏导并置为0来求w的解。
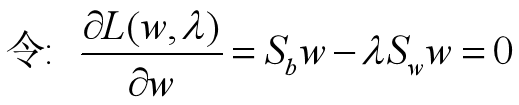
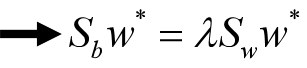
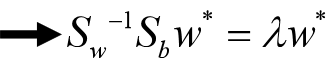
这是一个求矩阵
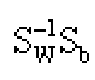
的特征值问题。
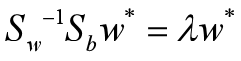
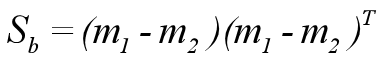
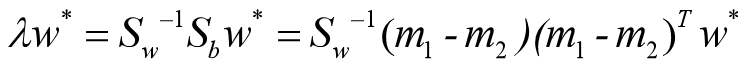
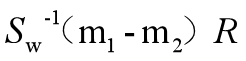
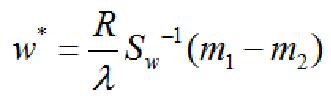
其中(m1-m2)Tw*=R
实际上我们关心的只是向量w*的方向,其数值大小对分类器没有影响。因此在忽略了数值因子R/λ 后,可得:

上式就是使用Fisher准则求最佳法线向量的解。
向量w就是使Fisher准则函数JF(w)达极大值的解,也就是按Fisher准则将d维X空间投影到一维Y空间的最佳投影方向,该向量w的各分量值是对原d维特征向量求加权和的权值。
阈值的确定
对于两类问题的线性分类器可以采用下属决策规则:
g(x)=g1(x)-g2(x)
如果g(x)>0,则决策x属于W1;如果g(x)<0,则决策x属于W2;如果g(x)=0,则可将x任意分到某一类,或拒绝。
Fisher线性判别的决策规则
根据上述式子:
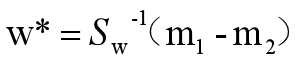
可以得到最后决策规则,如果:
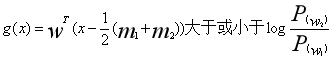
则
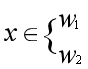
对于某一个未知类别的样本向量x,如果y=WT·x>y0,则x∈w1;否则x∈w2。
“群内离散度”与“群间离散度”
样本类内离散度矩阵Si
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YkS0yY2i-1588653485704)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200505124339438.png)
样本类间离散度矩阵Sb
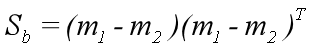
2.Python代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
path=r'F:/人工智能与机器学习/iris.csv'
df = pd.read_csv(path, header=0)
Iris1=df.values[0:50,0:4]
Iris2=df.values[50:100,0:4]
Iris3=df.values[100:150,0:4]
m1=np.mean(Iris1,axis=0)
m2=np.mean(Iris2,axis=0)
m3=np.mean(Iris3,axis=0)
s1=np.zeros((4,4))
s2=np.zeros((4,4))
s3=np.zeros((4,4))
for i in range(0,30,1):a=Iris1[i,:]-m1a=np.array([a])b=a.Ts1=s1+np.dot(b,a)
for i in range(0,30,1):c=Iris2[i,:]-m2c=np.array([c])d=c.Ts2=s2+np.dot(d,c) #s2=s2+np.dot((Iris2[i,:]-m2).T,(Iris2[i,:]-m2))
for i in range(0,30,1):a=Iris3[i,:]-m3a=np.array([a])b=a.Ts3=s3+np.dot(b,a)
sw12=s1+s2
sw13=s1+s3
sw23=s2+s3
#投影方向
a=np.array([m1-m2])
sw12=np.array(sw12,dtype='float')
sw13=np.array(sw13,dtype='float')
sw23=np.array(sw23,dtype='float')
#判别函数以及T
#需要先将m1-m2转化成矩阵才能进行求其转置矩阵
a=m1-m2
a=np.array([a])
a=a.T
b=m1-m3
b=np.array([b])
b=b.T
c=m2-m3
c=np.array([c])
c=c.T
w12=(np.dot(np.linalg.inv(sw12),a)).T
w13=(np.dot(np.linalg.inv(sw13),b)).T
w23=(np.dot(np.linalg.inv(sw23),c)).T
#print(m1+m2) #1x4维度 invsw12 4x4维度 m1-m2 4x1维度
T12=-0.5*(np.dot(np.dot((m1+m2),np.linalg.inv(sw12)),a))
T13=-0.5*(np.dot(np.dot((m1+m3),np.linalg.inv(sw13)),b))
T23=-0.5*(np.dot(np.dot((m2+m3),np.linalg.inv(sw23)),c))
kind1=0
kind2=0
kind3=0
newiris1=[]
newiris2=[]
newiris3=[]
for i in range(30,49):x=Iris1[i,:]x=np.array([x])g12=np.dot(w12,x.T)+T12g13=np.dot(w13,x.T)+T13g23=np.dot(w23,x.T)+T23if g12>0 and g13>0:newiris1.extend(x)kind1=kind1+1elif g12<0 and g23>0:newiris2.extend(x)elif g13<0 and g23<0 :newiris3.extend(x)
#print(newiris1)
for i in range(30,49):x=Iris2[i,:]x=np.array([x])g12=np.dot(w12,x.T)+T12g13=np.dot(w13,x.T)+T13g23=np.dot(w23,x.T)+T23if g12>0 and g13>0:newiris1.extend(x)elif g12<0 and g23>0:newiris2.extend(x)kind2=kind2+1elif g13<0 and g23<0 :newiris3.extend(x)
for i in range(30,50):x=Iris3[i,:]x=np.array([x])g12=np.dot(w12,x.T)+T12g13=np.dot(w13,x.T)+T13g23=np.dot(w23,x.T)+T23if g12>0 and g13>0:newiris1.extend(x)elif g12<0 and g23>0: newiris2.extend(x)elif g13<0 and g23<0 :newiris3.extend(x)kind3=kind3+1
correct=(kind1+kind2+kind3)/60
print("样本类内离散度矩阵S1:",s1,'\n')
print("样本类内离散度矩阵S2:",s2,'\n')
print("样本类内离散度矩阵S3:",s3,'\n')
print('-----------------------------------------------------------------------------------------------')
print("总体类内离散度矩阵Sw12:",sw12,'\n')
print("总体类内离散度矩阵Sw13:",sw13,'\n')
print("总体类内离散度矩阵Sw23:",sw23,'\n')
print('-----------------------------------------------------------------------------------------------')
print('判断出来的综合正确率:',correct*100,'%')
参考文章
http://bob0118.club/?p=266
这篇关于Fisher线性分类器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







