本文主要是介绍DoRA(权重分解低秩适应):一种新颖的模型微调方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
来自:小互
DoRA(权重分解低秩适应):一种新颖的模型微调方法
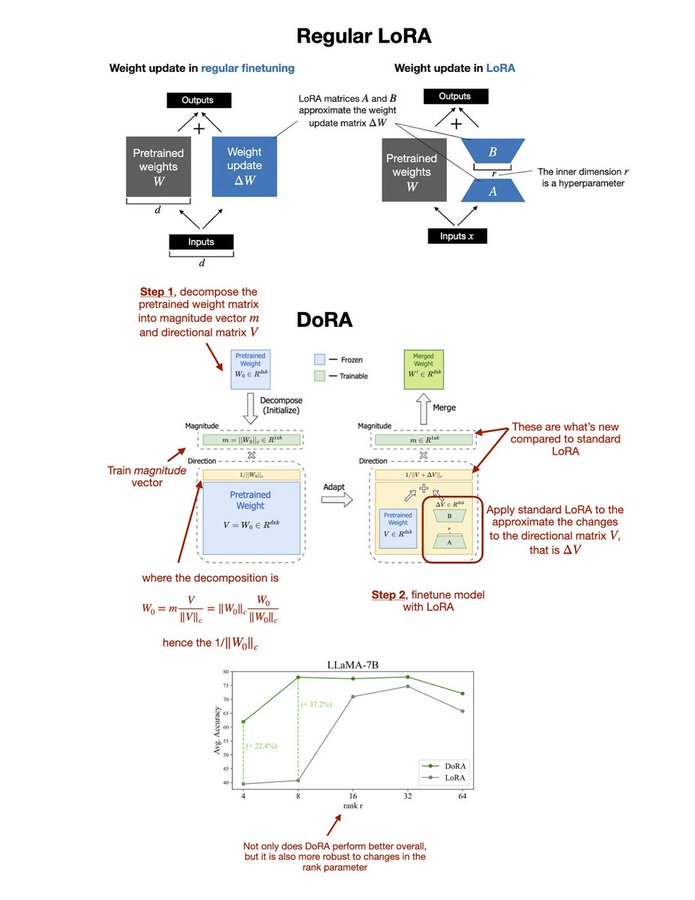
DoRA在LoRA的基础上进一步发展,通过将预训练权重分解为“幅度”和“方向”两个部分进行微调。
这种权重分解方法允许DoRA更精细地控制模型的学习过程,分别针对权重的大小和方向进行优化。
相比LoRA,它提供了一种更精细、更全面的微调策略。
模型微调的挑战
当我们有一个已经训练好的AI模型时,如果想让它适应一些新的任务,我们通常会进行所谓的“微调”,即对模型进行一些小的调整。这就像是给模型上一堂速成课,让它快速学习新技能。但问题是,随着模型变得越来越大,这种“速成课”的成本也越来越高,不仅需要大量的计算资源,还可能使模型变得笨重,影响其运行速度。
DoRA(权重分解低秩适应)和LoRA(低秩适应)都是针对预训练模型进行微调的方法,旨在提高模型针对特定任务的性能,同时尽量减少计算成本和资源需求。尽管两者都旨在实现参数高效的微调,但它们在方法和优势上有所不同。
LoRA的基本原理:
LoRA通过在模型的权重更新中引入低秩矩阵,来实现对模型的高效微调。具体来说,它通过使用两个较小的矩阵的乘积来近似权重的更新,从而减少了需要训练的参数数量。这种方法不改变原始模型的架构,因此不会增加额外的推理负担。
DoRA的创新之处:
DoRA在LoRA的基础上进一步发展,通过将预训练权重分解为“幅度”和“方向”两个部分进行微调。这种权重分解方法允许DoRA更精细地控制模型的学习过程,分别针对权重的大小和方向进行优化。在调整方向部分时,DoRA利用了LoRA的策略,通过低秩适应来有效地更新方向,而幅度部分则单独进行调整。
通俗解释就是:DoRA通过一种聪明的方法来解决这个问题。它将模型的“知识”(即模型中的权重)分解成两个部分:一部分负责“方向”(即模型应该如何调整其判断),另一部分负责“幅度”(即这种调整有多大)。通过这种分解,DoRA可以更精细地调整模型,就像是给模型提供了一个更加个性化的“速成课”。
低秩适应的聪明之处
在调整“方向”部分时,DoRA使用了一种名为LoRA的技术,这种技术只需调整很少量的数据就能实现有效的微调。这就好比是在教模型新技能时,只需给模型一些关键的提示而不是让它重新学习一遍所有的内容。
DoRA相对于LoRA的优势:
-
1、更细致的控制:通过分别针对权重的幅度和方向进行调整,DoRA提供了对模型微调过程更细致的控制,从而能够更准确地适应特定的任务需求。
-
2、增强的学习能力:DoRA的权重分解策略增强了模型在微调过程中的学习能力,使其在多种下游任务上的性能更接近于全参数微调的方法。
-
3、保持高效性:尽管DoRA在微调策略上进行了创新,但它仍然保持了LoRA的高效性,避免增加额外的推理负担。
-
4、提高训练稳定性:DoRA通过分解权重并专门针对方向使用低秩适应,提高了训练过程的稳定性,有助于避免过拟合和其他训练问题。
举例解释DoRA和LoRA的区别:
要理解DoRA在LoRA基础上的进一步发展和其权重分解方法,我们可以用一个简化的类比来帮助说明:
想象你有一辆车(代表预训练的AI模型),现在你的目标是让这辆车能够在一个新的赛道上(特定任务)尽可能好地运行。为了达到这个目标,你需要对车进行调整。在这个例子中,车的“方向”代表模型做决策的方向或方式,而“幅度”则代表这些决策的强度或信心。
LoRA的方法:
如果仅使用LoRA,这就像是你只能调整方向盘的灵敏度(方向),来使车更好地适应赛道。这种方法有效,但可能不足以让车在所有情况下都表现最佳,因为你没有考虑到其他因素,比如加速的力度。
DoRA的创新:
在DoRA中,你不仅调整方向盘的灵敏度,还可以调整油门的敏感度(幅度)。这样,你就可以更细致地控制车的行驶,既能确保它沿着正确的路径前进,又能控制它的速度,以应对不同的路况。
-
方向调整:通过LoRA进行低秩适应,相当于调整方向盘的灵敏度,让AI模型在做出决策时能更精确地指向正确的方向。
-
幅度调整:独立进行的幅度调整,就像是根据赛道的不同部分调整油门的敏感度,让模型对它的决策有适当的信心。
通过这种方法,DoRA能够更全面地对模型进行微调,既考虑到了决策的方向,又优化了这些决策的强度。这使得DoRA在特定任务上的性能更接近于全参数微调方法,而且相比LoRA,它提供了一种更精细、更全面的微调策略。简而言之,DoRA通过在LoRA的基础上增加幅度的调整,使模型的微调更加细致和有效。
这篇关于DoRA(权重分解低秩适应):一种新颖的模型微调方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





