本文主要是介绍多模态论文串讲·下【论文精读·49】最近使用 transformer encoder 和 decoder 的一些方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我们今天就接着上次多模态串讲,来说一说最近使用 transformer encoder 和 decoder 的一些方法。
1 BLIP:Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
我们要过的第一篇论文叫做blip,题目中有两个关键词,一个就是 Boost drapping,另一个就是unified,也就是他们这篇文章的两个贡献点。
第一个 Boost drapping 其实是从数据集角度出发的,他是说如果你有一个从网页上爬下来的很嘈杂的数据集,这时候你先用它去训练一个模型,接下来你再通过一些方法去得到一些更干净的数据,然后再用这些更干净的数据能不能train出更好的模型。
那第二个贡献点 unified 其实就从Vision-Language Understanding and Generation来看就非常明了,也就是从模型角度出发,这两个方向,一个是understanding,也就是 image text retrieval、VQA、VR、VE 这些我们上次讲过的任务,还有就是 generation 这种生成式任务,比如说 image captioning,就是图像生成字幕这种任务
作者团队全部来自于 Salesforce research。是我们上次讲过 ALBEF 那篇论文的原班人吗?我们一会儿也可以看到 BLIP 这篇论文,它的模型也有很多 ALBEF 的影子,而且它里面也用了很多 ALBEF 的训练技巧。
1.1 引言
研究动机
那接下来我们直接进入引言部分,看看这篇文章的研究动机到底是什么。 BLIP的引言写得非常清晰,他上来就告诉你,我的研究动机有两个部分,一个是从这个模型角度出发,一个是从数据角度出发。
1、从模型上
- 作者说最近的一些方法,它要就是用了 transformer encoder 的一些模型,这里举的这个clip,还有他们自己的 ALBEF。
- 另外一条路就是用了这种编码器解码器 encoder decoder 的结构,比如说后面这个就是 Sim VLM。
虽然说方法都有,但是作者这里说这种 encoder only 的模型,它没法很直接的运用到这种 text generation 的任务里去,比如说图像生成字幕,因为它只有编码器,没有解码器,那它用什么去生成?当然也不是完全不行,但就说不够直接,肯定你要杂七杂八的再加一些模块儿,才能让他去做这种 text generation 的任务。
那对于 encoder decoder 模型来说,它虽然有了decoder,它虽然可以去做这种生成的任务,但是反过来因为没有一个统一的框架,所以说它又不能直接的被用来做这种 image text retrieval 的任务。
那我们读到这儿,其实发现作者这里这个研究动机跟我们上次讲的那个 VLMO 是完全一样,都是说现有的框架 a 可以干什么?不能干什么, b 可以干什么?不能干什么,但是这两条方向都不能一个人把所有的活都干了,所以如何能提出一个unified,一个统一的框架,用一个模型把所有的任务都解决,那该多好?那接下来我们很快就可以看到,其实 BLIP 这篇论文就是利用了很多 VLMO里的想法,把它的模型设计成了一个很灵活的框架,从而构造了这么一个 unified framework。
2、从数据上
那另外一个研究动机就是说数据层面,作者说目前就是表现出色的这些方法,比如说 clip ALBEF 和 SIM l m,他们都是在大规模的这种网上爬下来的非常 noisy 的数据集上,也就是这种 image text pair 上去预训练模型的。虽然说当你有足够多、足够大的数据集的时候,它能够弥补一些这些嘈杂数据集带来的影响,也就是说你通过这个把这个数据集变大,你还是能够得到非常好的这个性能的提升的。但是 BLIP 这篇论文就告诉你,使用这种 Noisy 的数据集去预训练还是不好的,它是一个 suboptimal,不是最优解。那如何能够有效地去 clean 这个 Noisy 的 data set 如何能够让模型更好地去利用数据集里的这个图像文本配对信息?在 blip 这篇论文里,作者就提出来了这个 captioner 和 filter 这么一个module。
- captioner 的作用就是说我给定任意一张图片,我就用这个 captioner 去生成一些这个字幕,这样我就会得到大量的这个合成数据 synthetic data。
- 然后同时我再去训练这么一个 filtering model,它的作用就是把那些图像和文本不匹配的对儿都从这个数据集里删掉。比如说在这个例子里,这就是一个巧克力蛋糕。那原来从网上直接爬下的这个图像文本堆儿里的文本写的是 blue sky Bakery in Sunset park,就是说一家位于这个日落公园叫蓝天的蛋糕店,那我们可以很明显的看出来这个图文其实是完全不匹配的。那我们上次也提过,之所以它这个文本是这样,其实是因为有利于这个搜索引擎去搜索,因为大家看到这个蛋糕的图片之后,更想做的是去知道这家蛋糕店在哪,我怎么能去买到这家蛋糕店,这样搜索引擎才能收广告挣钱,这个蛋糕店的店主也能得到更多的客流量。所以大部分你爬下来的那些数据集,不论你爬了几百万、几千万、上亿的主图片文本,对儿里面大部分都是这种不匹配的 Noisy 的文本对儿,
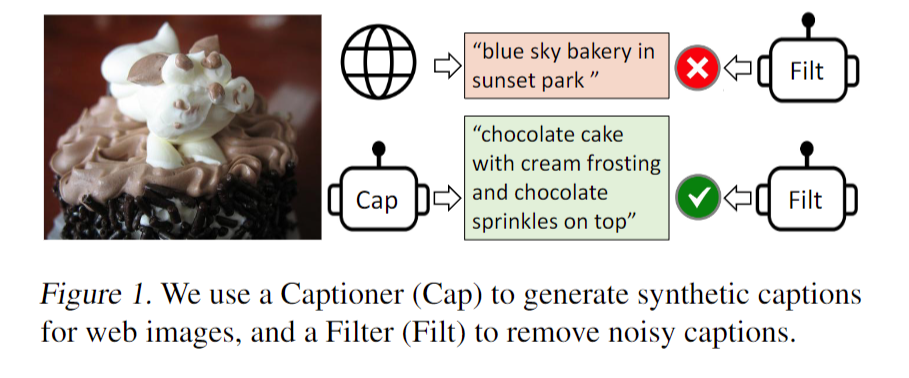
在我们这个时候可以看到作者训练的这个 captain 这个模型,它其实可以生成非常好、非常有描述性的这个文本,那所以在接下来他们训练的这个 filtering 模型来看,他们就会选择这个图像文本对儿去进行模型的训练,而不用原来的那个真实的图形文本对儿去进行训练。
1.2 贡献一:模型结构
那快速过完了引言中的研究动机。接下来我们废话不多说,直接来看文章的图2,看一下 BLIP 整体的这个模型结构。那在看图 2 之前,我想再回顾一下上一期讲的两个方法,因为之前我们说过 ALBEF 的提出就是在 ViLT 和 clip 一系列工作之前的这个经验总结上得到,那我们今天要讲的这个 BLIP 是不是也能用之前的经验总结而得到?那答案是肯定的。
我们首先来看 ALBEF, ALBEF 的模型分成 3 个结构,一个是这个视觉编码器,一个是文本编码器,那还有一个是多模态编码器,对于图像这端来说,就是一个图像进入这个 transformer encoder,它一共有 n 层,然后一个文本进入这个文本的编码器,它有 l 层。然后在得到对应的这个图像文本特征之后,他先做一个 ITC image text contrasted 这个对比学习的loss,去把图像和文本分别的这个特征学好,然后文本特征继续进入这个 self attention layer 去学,然后图像特征通过一个 cross attention layer 进来,然后和文本特征去进行融合,然后经历了 n 减 l 层的这个多模态的编码器之后,最后得到了多模态的那个特征,然后最后用这个多模态的特征去做 image text matching 这个任务,从而去训练更好的模型。为什么文本这端要把一个 n 层的 transformer encoder 硬生生的 p 成 l 层和 n 减 l 层?至于作者还想大概维持这个计算量不变,就是跟 CLIP 一样,左边一个 12 层的 transformer encoder,右边也是一个 12 层的 transformer encoder,他不想增加更多过量的这个多模态融合这部分的计算量,但是多模态这一部分又特别的重要,然后相对而言文本这端不那么重要,所以他就把这边 12 层的计算量给分成了两部分。
但是同样的问题, VLMO 是怎么解决的? VLMO 觉得你这样 p 来 p 去也太麻烦了,而且也不够灵活。那我们现在来设计一个这个 mixard of expert MOE 这种网络,让它变得极其的灵活,就是说我只有一个网络,我的这个 self attention 层全都是共享参数的,我唯一根据模态不同而改变的地方就是这个 feed forward network,我有我的这个 feed forward 的vision、 feed forward text 和 feed forward 的 Multi model,我用这个地方去区别不同的 modelity 去训练不同的expert。这样我就用统一的一个模型,就是在训练的时候是一个模型,但是我在做推理的时候,我可以根据不同的这个任务去选择这个模型中的某一部分去做推理。而且 VLMO 这篇论文用实验大量的实验证明了这个 self attention 层确实是可以共享参数的,它跟这个模态没什么关系。那大家一旦收到这个信号之后,肯定还是觉得 VLMO这个结构更简单,至少直观上看起来更简单更优雅。所以说结合了 ALBEF 和 VLMO,作者就推出了 BLIP 这个模型。
我们先大体从粗略上来看一下 BLIP 这个模型包含了四个部分

- 一个就是图像这边,它有一个完整的 VIT 的模型,一个 n 层的 VIT 模型,而且是非常标准的 self attention 和 feed forward。
- 然后文本这边它有三个模型,分别用来算三个不同的这个目标函数。这个就跟 VLMO 已经非常像了,它根据你这个输入模态的不同,它根据你这个目标函数的不同,它去选择一个大模型里不同的部分去做这个模型的forward。
- 那对于第一个文本模型来说,这里面它也是 n 层,而不像 ALBEF 里的 l 层了。它的目的是根据你输入的文本去做这么一个 understanding 去做这么一个分类的任务。所以说当得到了这个文本特征之后,他就去跟这个视觉特征去做 ITC loss。
- 那第二个文本模型作者这里说它叫 image grounded taxing coder,就是它是一个多模态的编码器了,它这里是借助了图像的信息,然后去完成一些多模态的任务。很显然那这个就是我们之前要做这个 ITM loss,那这个时候其实我们发现如果你把这个部分直接放到这个上面,其实它不就是 ALBEF 吗?先有一个 n 层的VIT,然后这边有一个 n 层或者 l 层的这个文本端,然后在上面又加了一个这个多模态的端,这个视觉的特征通过这个 cross attention layer 进来,文本端的特征通过这个 self attention layer 进来,然后最后得到一些多模态的特征,然后去算这个 ITML loss。所以如果暂时我们先不看第三个这个文本编码器,其实左边这一部分完完全全就是一个 ALBEF,但是它跟 ALBEF 有一点不同,这是它借鉴了VLMO里,这个 self attention 层是可以共享参数的,所以它就不需要把一个文本模型劈成两个部分去用了,它可以就用一个文本模型,但是共享参数。所以这里我们也可以看到作者说同样的颜色代表同样的参数,就是共享参数的,它不是两个模型。那这里我们可以看到这个 SA 层也是共享参数的,所以相当于第一个文本编码器和第二个文本编码器,它基本就是一样了,它的这个 SA 和 FF 全都是一致的,只不过第二个里头多了一个 cross attention 层,需要新去学习。那所以讲到这儿也就回答了我们刚才的问题,我们确实可以通过看之前的方法总结他们的经验,从而得到接下来的方法的这个大体的模型结构和创新点,
- 但是到这儿我们会发现目前的这个结构,它还是只能做这种 v q A VR VE 这种 understanding 的任务。那怎么去做生成的任务?这个 decoder 在哪?那有了 VLMO 这个想法之后,那一切就变得很简单了,对吧?如果你需要一个decoder,那你就再加一个decoder,不就完了吗?所以你就在后面再加这么一个文本的decoder。但是对于 decoder 来说,它的这个输入输出的形式和尤其是第一层的这个 self attention 是不太一样了,因为这个时候他不能看到完整的这个句子,因为如果他已经看到完整的句子,他再去生成这个句子,那他肯定能 100% 生成出来这个句子,那就训练就没有难度了,那它必须像训练 GPT 模型一样,它把后面的这些句子都挡住都 mask 掉。它只通过前面的这些信息去推测后面的句子到底长什么样,这才叫 text generation。所以说它的第一层用的是 causal 的 self attention,也就是因果关系的这个自注意力,就是你要去做一些这个因果推理,你要通过前面的这些文本去推测后面的文本到底是什么。那因为这里它做的是这种 causal self attention,跟前面的这个 Bidirectional self attention 就不一样了,所以我们可以看到它这里颜色是不一样的,就是它俩是没办法共享参数的。作者后面也做了实验,就是如果你硬要让他们去共享这个参数,这个性能是会下降的,因为它确实是在做不同的任务。但是除了第一层的这个自注意力之外,后面的这个 cross attention 和 feed forward,它就跟前面的全都是共享参数的了。所以说名义上它新添加了一个第三个这个 text decoder,但事实上参数量并没有增加多少,只是增加了一些 causal self attention。最后的目标函数就是用的 GPT 系的这种 language modeling,也就是说给定一些词,还去预测剩下的那些词,这个就叫 language modeling。那对于MLM,也就是 ALBEF 和 VLMO之前用的那个目标函数,那个是属于完形填空,就给一个句子中间词抠掉,我去预测中间这个词,所以说 l m 和 m l m 其实是不一样的,那在这篇论文里,因为作者要去做这种生成式的任务,所以更好的一个选择是使用 language modeling 的目标函数。
那说到这儿,文章的模型部分就基本已经说完了,再来快速总结一下,就是说对于图像它就有一个VIT,但是对于文本来说,它对应了三个模型,分别是一个标准的这个 text encoder,然后还有就是 image grounded text encoder 和 image grounded text decoder。但不论你是 encoder 还是decoder,其实模型之间的差距都是非常小的。比如说对于 image grounded text encoder,它就有一个新的 cross attention,然后对于 image grounded text decoder,它就有一个新的 causal self attention,剩下的部分其实基本都是共享参数的。然后就跟 VLMOy 一样,当我们选择头两个模型的时候,我们就去算这个 ITC loss。当我们选择第一个和第二个模型的时候,我们就去算 ITM loss。当我们选择第一个模型和第三个模型的时候,我们就去算这个 l m loss。所以从目标函数角度来说, blip 也是三个目标函数,头两个跟 ALBEF 和VLMO都是一样的,只不过第三个从 MLM 换成了LM。所以说 VLMO 和 blip 推广的这一系列 unified framework,虽然它不是真正意义上的unified,但确实是非常灵活,而且能把大部分的任务都融合到一个模型中来,大大加速了这个多模态学习的进展。当然文章中还有一些细节,比如对于三个文本模型来说,它们对应的这个 token 就不一样,第一个文本模型就用的是 CLS token,第二个用的是encode,第三个用的是decode。还有就跟我们上次说的一样,这些模型都很难训练,训练的代价非常高,原因就是因为在做每一次这个 training iteration 的时候,图像端其实只需要做一次forward,但其实文本端在这里要做senseforward,要分别通过这三个模型去得到对应的那个特征,然后去算对应的目标函数,所以还是非常费时间的。另外因为 blip 就是 ALBEF 的原班人马做的,所以说里面用到了很多 ALBEF 的技巧,比如说在算 i t seed 时候,它也用了 momentum encoder 去做更好的 knowledge distillation,也去做更好的这个数据集的清理。同时在算 ITM loss 的时候,也像 ALBEF 一样,利用 ITC 算的那个 similarity score 去做 hard negative money,从而每次都用那个最难的负样本去算这个ITM,从而增加这个 loss 的有效性。总之这就是 blip 的模型结构。文章中作者把这叫MED,就是 mixture of encoder and decoder,就是把编码器和解码器混到一起了。那其实这个命名方式跟 VLMOre 也很像,对吧? VLMOre 提出的那个 transformer block,它就叫MOME,就是 multimodity mixture of expert。所以 BLIP 只不过就是把 mixture of expert 换成了 mixture of encoder and decoder,但意思都是一个意思。
1.3 贡献二:cap filter model

那说完了模型结构MED,接下来我们就来讨论一下 BLIP 这篇论文。第二个贡献点,也就是最重要的那个贡献, cap filter model,它的出发点或者研究动机。就是说,假如说你有很多这个数据集,这个 d 里面可能有一些网上爬下的数据集,可能有一些手工标注的数据集。当然像 CLIP 模型的训练,他就没有用这个手工标注的数据集,就只用从网上爬下来的那 400 million。但是有的时候,反正手工标注的数据集,比如说 Coco 也是存在的,那不用白不用,所以有的人也会用。总之对所有的现有的这个数据集 d 来说,它最大的问题就是说从网页上爬上的数据集这个图片文本对不匹配,也就是说这里的这个 TW 不好,所以作者这里用红色来表示,然后这个 Coco 手工标注的,他认为这个文本就一定匹配,所以用绿色来表示。然后作者这里的论点就是说,如果你用这种 Noisy 的数据集去预训练一个这个模型,它的效果就不是最好。那如果我们想清理一下这个数据集,从而去达到这个最优解该怎么做?那很自然的我就需要训练一个模型,这个模型最好是能给我一些像图像文本之间这个相似度,那相似度高的就说明匹配,相似度不高的可能就不匹配,所以这也就是 filter 这个模块的由来。
至于 filter 是怎么训练的,作者就是把已经提前预训练好的这个MED,也就是把已经训练好的这个 blip 模型拿出来,然后把那个图像模型和两个文本模型,就是分别做 ITC 和 ITM 的那两个文本模型拿出来,然后又在 Coco 数据集上,就是在干净的数据集上又去做了一些很快的微调,然后先训练出来的这个就是微调过后的这个 MED 就叫做这个 filter 了。那接下来他主要用这个模型去算一下这个图像文本的这个相似度,尤其是这个 image text matching 的这个分数,那它就知道到底这个图像和文本是不是一个 match 了,那不是match,自然它就可以把它拿掉。所以通过这个filter,作者就把原始这个爬下来的 noisy 的 it 的文本对,比如说这里红色的 TW 就变成了这个稍微 clean 一点的这个图像文本,对,唉,就是这个绿色的 TW 了,那其实到这里这个任务其实就已经完成了,对吧?
那为什么作者还要再去加一个captioner?主要原因我觉得还是因为作者在训练出来那个 decoder 之后,他发现这个 blip 模型训练好的这个 decoder 真的是非常的强,它有时候生成的那个句子比原始的那个图像文本段要好很多。就即使原来的那个图像文本对儿是一个match,它俩是匹配的,但是我新生成的这个文本儿更匹配,它的质量更高,所以作者就想说,那我就试试看,对吧?那我用生成的这些文本去充当新的训练数据集,那会不会得到更好的模型?那其实这里作者也是在 Coco 这个数据集上去把已经训练好的这个 image grounded text decoder 又去微调了一下,然后就得到了这个captioner,然后给定任意一张从网上爬下的图片,然后他就用这个 captioner 去给这个图片去生成新的字幕,也就是红色的这里的TS,当然 t s 的质量可高可低,这个完全是由模型来决定,有的时候就描述的特别好,那有的时候可能就是非常差,就有可能甚至都不 make sense 了。所以作者这里还是用红色去表示的,因为它是 synthetic date。
那最后通过 captioner 和filter,我们得到的数据集就从原来的这个 d 就变成了现在这个d,我们就会发现多了一项,就原来的那个 CC 12 million。假如说我们用 CC 12 million 来做例子的话,这个![]() 就是这个 filter 过后的 CC 12 million,它还是原来从网上爬下来的图像文本。对,只不过是 filter 过了,变少了,但是质量也变高了。那第二个这里的
就是这个 filter 过后的 CC 12 million,它还是原来从网上爬下来的图像文本。对,只不过是 filter 过了,变少了,但是质量也变高了。那第二个这里的![]() 就是 CC 12 million 合成的新生成的这些图像文本对儿,然后接下来如果你使用这个手工标注的,比如 Coco 数据集,你就还有
就是 CC 12 million 合成的新生成的这些图像文本对儿,然后接下来如果你使用这个手工标注的,比如 Coco 数据集,你就还有![]() 。总之你的数据集不仅变得更大了,而且质量变得更高了,那这个时候你再拿新的这个d,然后返回来再去预训练一个 BLIP 模型。最后作者发现了模型的提升非常显著,而且还有很多有趣的应用。这个就是本文提出的第二个创新点,这个 cap FILTER 模型,或者说 fine tuning 的一个 cap FILTER 模型,从而做到了数据集上的这个bootstrapping。
。总之你的数据集不仅变得更大了,而且质量变得更高了,那这个时候你再拿新的这个d,然后返回来再去预训练一个 BLIP 模型。最后作者发现了模型的提升非常显著,而且还有很多有趣的应用。这个就是本文提出的第二个创新点,这个 cap FILTER 模型,或者说 fine tuning 的一个 cap FILTER 模型,从而做到了数据集上的这个bootstrapping。
可视化效果
那接下来我们先看几张图,形象的了解一下这个 cap filter 模型到底有多强大。

这里作者给了三个例子,上面的 TW 就是直接从网页端下载下来的那个文本,下面的这个 TS 就是他们的 captioner 新生成的文本,红色的就代表被 filter 掉的那些文本,而绿色就代表 filter 以后保留下来的那一个文本,也就是说跟图片更匹配的那个文本。
- 那现在我们来看一下第一个例子,看着像一个自然风光,那原来从网上爬下来的就是说在我家旁边有一个桥上,可能照出来的这张图片确实也不能说不对,但是如果你看底下这个生成的这个句子,他说在日落的时候,有一群鸟飞过了一个湖面,这个描述的简直是太精确了,把这个日落湖和鸟全都包含在里面了。那如果你用这个图像文本邓去训练模型,肯定训练出来的模型效果很好,因为语义是完全 match 上的。
- 我们再来看第三个例子,从网上爬下来的这个说这是一个 1180 年建立的这么一个城堡,它是取代了 9 世纪的时候一个用木头做的一个城堡,但是 capture 这次的效果就差强人意也是对的,但是他说这是一个很大的一个楼,然后上面有很多很多的窗户,那它就不够具体了,因为这里这些有可能就是那些门洞、拱门或而且整个这就是一个卡色,它不是一个大的building。所以这次 BLIP 训练出来的这个 filter 就选择了上面就原始的这个图片文本对,所以这里我们不仅可以体会到这个 captioner 的强大之处,就你给定什么样的一张图,我都能给你生成比较 reasonable 的这个文本。同时我们也能体会到这个 filter 的强大之处,就是我能够很准确的从这个原始的文本和新生成的文本里去挑出来哪个跟这个图像是更匹配的
实验结果
所以我们看完这几个例子之后,我们就应该知道 cap FILTER 真的是把这个数据集清理的相当好了。那这个时候我们再看上面这个图表,看到 cap FILTER 带来这个提升之后,我们也就不会再惊讶。那接下来我们就来看一下这个表一,
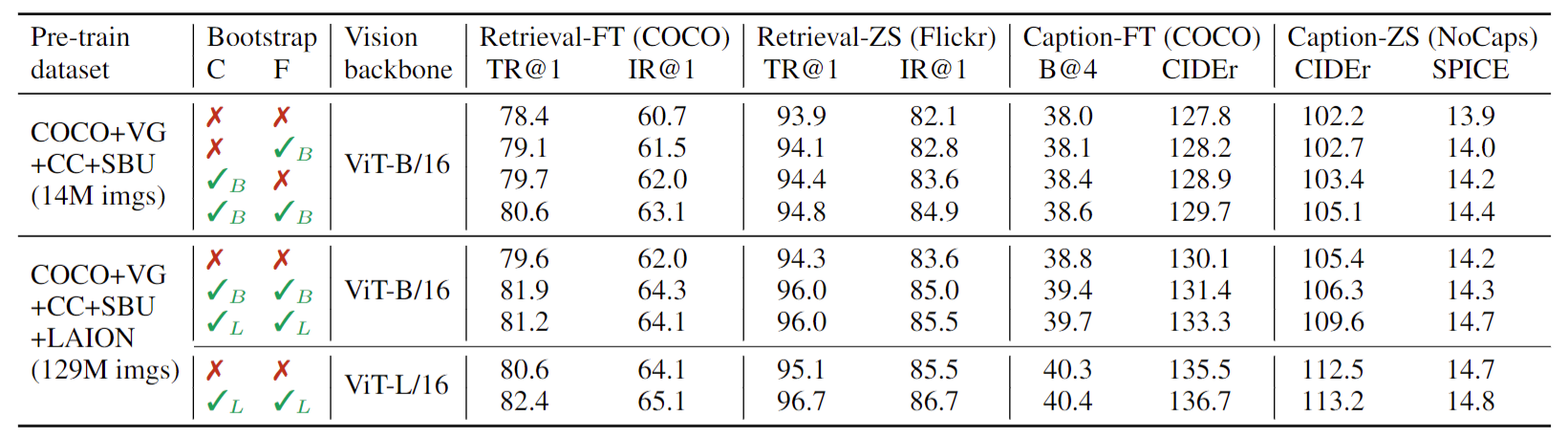
这是一些主要的消融实验和主要的一些结果,里面不仅有这个检索的任务,而且也有这个 captioning 的任务。然后这个表一分了几个部分,就是分了几个setting。
- 我们首先来看当这个模型保持一致的时候,就这个 vision backbone 都用 VIT base 的时候,那如果我们改变了这个数据集的大小,从 14million 变成了 129 million,就是数据集增大,我们可以明显的看到这个分数,就这一列的分数是比这一列的分数要普遍偏高的。这就意味着你用了更多的数据集,一般都是能够带来更多的提升的。
- 那接下来我们再锁定这个数据集,就是用同样的数据集,但是我们把这个模型变大,从 base 变到large,那我们也可以看到这一列是普遍要比这一列效果要好很多的,但这些都是老生常谈,大家都知道的东西,数据集大,模型越大效果就越好。
那接下来我们来看一下这篇文章独有的这个 caption filtering 模式到底带来什么样的提升。那这个 c 就代表captioner, f 就代表用了filter。
- 我们第一个可以观察到的现象就是说如果都不用它,这个结果肯定是最差的。
- 然后不论是用了 filter 还是用了这个captioner,效果都会有提升。
- 而且比较神奇的是,用了 Captioner 以后,这个提升是更加显著的。也就意味着说这个 captioner 带来的这个 data diversity 这种多样性是会更让这个模型受益的。尤其是对大模型或者大数据集的训练来说,你偶尔这个数据集有点noise,其实无所谓,模型都是能够 handle 的,但是因为模型参数量太大,所以它非常的 data hungry,它需要大量的数据,所以这个时候你只要能生成更多更好的数据,它往往就能够受益。
- 那最后这个 captioner 和 filter 同时用,效果就达到最好了,当然这个只是一个消融实验,
但是这个表格里最有意思就是这两行都是打了这个对号,也就是说它都用了 caption 和filter。为什么一个叫base,一个叫large? 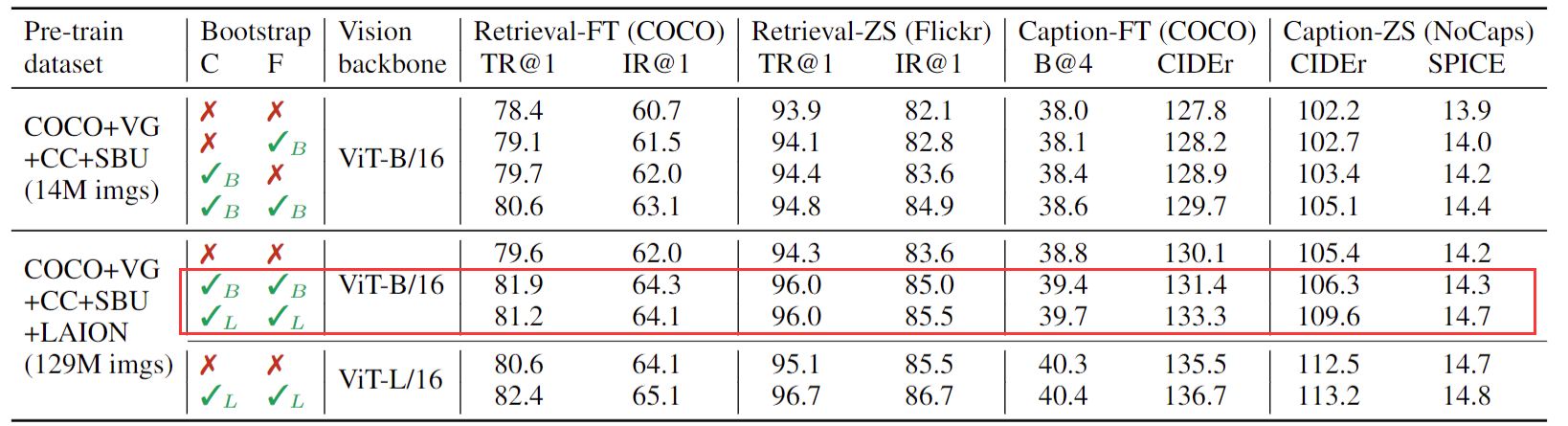
是因为如果你回想我们这个 boot strapping 的过程,它其实一个分阶段的训练,就跟 VOMO 一样,分阶段blip,其实也是分阶段,他先是用嘈杂的数据集预训练了一个模型,这是训练 stage one。然后这个时候他用 Coco 去fine,tuning、 captioner 和filter,然后把数据集重新处理一遍,得到了一个新的、更大的质量、更好的数据集,这是 stage two。然后第三个 stage 就是他用这个新的数据集就又 pretrain 了一个blip,那这几个步骤,这三个 stage 其实都是互不相干的,其实是可以分开训练或者分开使用的。所以作者这里的意思就是说,即使我的这个模型是 VIT base,就我的模型可以很小,但是我在第二阶段生成这个新的数据集的时候,我可以用更大的这个模型,用更大的那个MED,更大的 cap filter 模式去生成更好、质量更高的这个数据集。我并不一定说我这儿用的模型是base,我那个 capifilter 模型就一定要用 base 生成数据,这一步完全是一个额外的步骤,完全是另外一步 pseudo labeling 的过程,理论上我也可以用任何一种方式去生成这种 pseudo label,所以这个就很有意思,也就是说理论上你是可以拿 blade large 训练出来的这个 MED 这个 caption 的 filter 去生成更好的这个数据,然后去给别的模型做训练用。你可以拿这个数据去训练VLMO,你也可以拿它去训练Coca,去训练 B I T 3,去训练各种各样的多模态的模型,因为它的目的就是生成更好的数据,所以是一个非常通用的工具。
看看最新的一些非常有趣的工作是怎么利用 BLIP 的
那为了说明 BLIP 或者这个 cat filter 是个有效的工具,是个通用的工具。我们接下来就举两个例子,看看最新的一些非常有趣的工作是怎么利用 BLIP 的。比如说前段时间这个 stable diffusion 火起来的时候,其中就有一个例子:lambdalabs.com
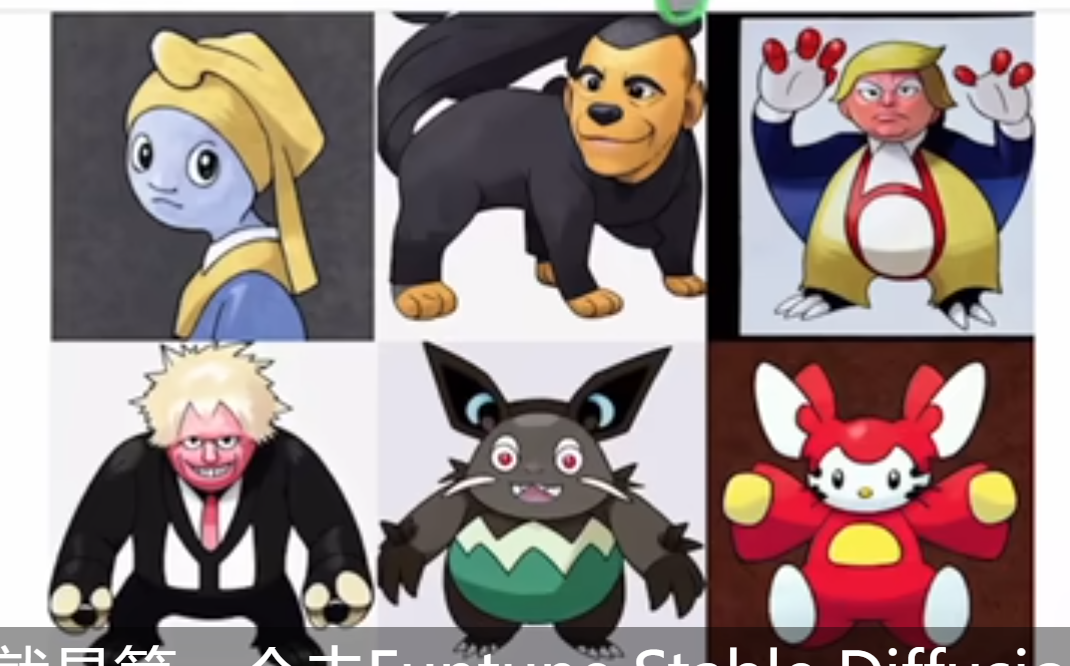
就是第一个去 fine tuning stable diffusion 去生成各种各样的 Pokemon modeled,当时也很是火了一波,而且我们也可以看到它这里生成的这些 pokemon 还真的是非常的形象,有世界名画,还有各国的总统,效果真的是非常拔群。当然我这里不是来讲 stable diffusion 怎么去 fine tuning,或者这个东西到底是怎么做成的,我只是想说一下 BLIP 在这里起到了一个什么样的作用。
那这篇博文说它在这个训练的时候,首先在处理这个数据的时候,图片他们很容易就找到了这个 pokement data set from fast again,大小也比较适中,然后清晰度也非常高,而且这个风格也非常一致,都是pookman。所以说用来做这个 fine tuning 的训练是再合适不过,但可惜它没有对应的这个文本,那你没有对应的这个文本,你怎么训练 stable diffusion 呢?那所以说这时候作者就想这个最简单的方式,就是说我能不能有一个这个 image caption 的model,我把这个图像扔进去,我直接生成一些caption,这不就完了吗?我 sensitive caption 行不行?作者就去试了一下BLIP,结果就发现了这个 BLIP 模型真的是效果出奇的好,它根本没有在破克曼上去做任何的 fine tuning,但是依旧能生成非常合理的这个caption。那比如说接下来这个就是作者用 BLIP 生成的一个caption,这个就是那个绿色的青蛙的pokemon,然后我们可以看到 blip 生成的这个 caption 就是 a drawing of a green Pokemon with red eyes,非常具有描述性。然后作者就觉得这个文本就已经足可以训练 stable diffusion,而事实上证明也确实可以。他们翻听出来的 stable diffusion 就是能够生成质量很高的 Pokemon model。
那另外一个使用 BLISS 模型的例子就是 Lion Coco 这个数据集。当然对于 Lion 团队大家可能都不陌生了,他们从去年刚开始先推出了 Lion 400 million,就是跟那个 open i 的 CLIP 400 million 数据集去对齐。接下他们又推出了更大的laion 2 billion,laion 5 billion。这些开源的大规模数据集极大的促进了这个多模态学习的进展。当然作者团队他们也意识到我收集这么大的数据集肯定是有用的,但是确实这里面的 noise 也是相当的高,那我能不能把它变成一个质量更高的数据集?这个时候他就想到利用 BLIP 这个模型,那于是作者就从他们最大的这个 line 5 billing 里去选了他们的这个一个英语的一个subset,然后用 BLIP 模型和两个 CLIP 模型去不停地做这种 filtering 和 capturing 的过程,然后最后得到了这个 Lion Coco 600 million, 这个数据集的质量按道理来说是应该比原来这个 Lion 两 billing 或者 5 billing 要高很多的。
那么接下来也可以先看一下它具体的这个做法,那我们来看它这个 method 其实非常的简单粗暴,它首先就是给定任何一张图片,它先用最大的这个 blip 模型去生成 40 个caption,因为每次都是在随机的采样,所以说它生成的 40 个 caption 也不完全一致,都是很 diverse 的。然后接下来我怎么去选这个图像文本对儿?你一个图像现在有 40 个caption,那这个时候我去需要用 CLIP 去做一下这个ranking,这一步也是非常普遍的操作,用 CLIP 模型去做一下ranking,看看最后 retrieve 谁排前谁排后,或者说 stable diffusion 生成的一些图片,哪些图片质量更高更低,一般都是内在的有一个这个 clip 模型去做这个排位的。所以首先第二步他们就是用这个 open i 这个 vision Transformer large 去选最好的这 5 个caption,然后选到了这五个 caption 之后,他再用 open i 的 CLIP 模型,但这次是用 Resnet 50,就最大的那个 Resnet 去做一次重新的ranking,然后把最好的那个选出来,这样子你就有一个这个图像文本对了,一个图像就对应一个文本。然后最后他还用一个比较小的这个 T0 的模型去修复了一下这个语法,还有这个文本的标点符号这些的,就争取让那个文本看起来更真实、更正确。那这个其实就是他们所有这个 captioning 和 filtering 的方法了。
那么现在回来看一下它这里给的几个例子。那首先第一个是这个钻戒原来配的这个文本,虽然说非常非常长,但它其实说了很多很多这个废话。但 BLIP 生成这个就是简洁明了,就是说它就是一个戒指,上面有两颗爱心。当然这两个并不能说谁好谁坏,我们接下来再看别的例子。那在接下来的这个例子里,明显这就是一个漫画,它原始配备的这个文本很短,就说 ship of family。当然这里确实是几只羊,而且确实只有小羊老羊什么的,这是一个family,但是如果跟 BLIP 生成的这个文本来比,肯定是 BLIP 更胜一筹的。BLIP 这里头形象地描述这里的所有的元素,比如说这里是一个卡通画,而且描述的是这个羊在看电视,而且是很多羊,一个family,还有他们的 baby 在一起看电视,所以真的是把那要描述的全都描述到这样的文本,按道理来说是应该能促进这个模型的预训练。
所以说 BLIP这篇论文真的是一篇非常好的论文,它并不是说提出了一个什么样的模型框架,而是说他提出的这个 caption filtering 这个方法非常非常的有效,而且具有普适性,你可以拿它去做很多很多的事情。所以如果当你的科研问题中遇到类似的问题,就是说你现在有一些图片,有一些视频,但是你没有 caption 的时候,你也不妨去考虑一下这个 BLIP 模型,甚至你有可能是在这个医疗领域,或者这个 remote sensing 领域,或者任何一个非自然图像领域,有可能也可以使用 blip 去生成一些caption,但是效果我也就不知道了。另外基于这个新推出的 line Coco 六百 million 这个数据集,也有很多这个可以做的这个 research 工作。那比如说最近有很多这种 language guided detection、language guided segmentation,比如说 group VIT,它们都是用这种嘈杂的数据集去进行训练的。那这个时候如果你把它原来训练的数据集替换掉,用这个 line 600 million 去训练,或者用 line 600 million 的一个 subset 去训练,效果是不是就会比之前更好?所以 BLIP 真的是开启了很多可能性,也挖了很多很多的坑,可以让我们去做。
2 CoCa
那说完了BLIP,接下来我们就讲一下 22 年另外一篇很著名的工作,Coca,从题目上来说,顾名思义就是 contrastive captioner。那我们大概也可以猜出来,模型可能就是用这两个目标函数训练出来的,一个就是 contrasive loss,一个就是 captioning loss,所以听起来跟 blip 非常的像。
作者团队全自来自于 Google research。这篇论文是在 22 年 5 月份传到 ARCHIVE 上,比 BLIP 晚了四个月,但是因为数据集更大,模型用的也更大,所以它的效果非常的亮眼。不光是把多模态所有的这个任务刷了个遍,而且在单模态里头,在 Imagenet 上也得到了 90 以上的这个 top one 准确度。而且在这个视频动作识别领域,一直到现在为止,在 paper with code 上 Coca 可能还是K400,K600, K700 这些数据集上排名前三的方法,所以效果是非常的强。
那鉴于我们已经讲过这么多模态的工作,该铺垫的都铺垫过了,所以我们现在直接可以看模型总览图,看一下 Coca 到底是怎么训练的。
我们打眼一看这个图 2 这个模型总览图,才发现,其实 Coca 是 ALBEF 的一个后续工作,它跟 ALBEF 的这个模型长得多像。左边是一个 image encoder,右边是一个 text 的decoder,这里面是decoder,不是encoder。但是从左右来看,还是左边图像右边文本的这个分支,然后右边文本这个分支又从中间被劈成了两半。前面专门用来抽这个 union model 的这个文本特征,后面去做多模态的这个特征,这不跟 ALBEF 完全一样吗?然后至于这个输入输出的走向,还有这个目标函数,图像这边通过这个 image encoder 就得到了一系列的这个token,那文本这边通过这个文本的解码器就得到了一系列的文本特征,而这里面图像的 CLS token 和文本的 CLS token 去做这个 ITC loss,然后图像这边其他的 token 作为一个 tentional pooling,然后再传到多莫太的这个 text decoder 里面去做一下 cross attention,然后就把视觉和文本的特征融合在一起了。那属于多模态的这个特征是怎么训练的?作者这边就用了一个 captioning loss,其实就是 Blapley 用的 language modeling loss,也就是 GPT 用的loss,那因为整个模型就是用两个目标函数训出来的,那一个是ITC,一个是 language model loss,也就分别是 contrasting 和captioning。所以就是 Coca 这里面模型的布局,甚至连这个 i t seed 位置都跟 ALBEF 是一模一样的。所以说 Coca 其实真的就是 CLM 和 ALBEF 的一个非常直接的一个后续工作。Coca 跟 ALBEF 还是有区别的,比如说在图像这一支,它这里就做的是 attentional pooling,这一部分是可学的,作者就发现这种可学的 pooling 方式能够针对不同的任务学到更好的特征,从而能对最后的这个多模态学习产生更好的影响。第二个就是不论是单模态的这个文本特征的学习,还是多模态的这个特征学习,整个文本这一端全都是用的decoder,而且因为最后的这个 loss 是 captioning 的loss,所以这也就意味着文本这边的输入从一开始前面的这个 self attention layer 就是 causal 的,也就是说我 mask 住这个一个句子后半部分,然后我用前半部分去预测这个后面是什么,也就是我们 blah 刚刚讲过的这个 language modeling loss。那文本这一端为什么统一都用decoder?然后训练目标函数为什么只用一个 captioning loss 而不用 ITM loss?作者这里其实就是想解决我们之前强调过几次的一个问题,也就是训练的这个效率问题,那不论是 ALBEF 还是 view mo,因为它要去算各种各样的这个目标函数,所以它往往一个 training iteration,它要 forward 这个模型好几次,那这无形中就增加了这个模型训练的时间长度。明明是训练 100 个epoch,那其实你 forward 了 3 次之后,你相当于是训练了 300 个epoch,那作者这里就想我能不能只做一次forward,那这不一下就减了一半或者甚至 2/ 3 的这个计算量吗?所以说
这篇关于多模态论文串讲·下【论文精读·49】最近使用 transformer encoder 和 decoder 的一些方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




