本文主要是介绍On the Opportunities and Risks of Foundation Models-Introduction(Emergence and homogenization),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- abstract
- Introduction
- Emergence and homogenization
- Naming
abstract
随着模型(如BERT、DALL-E、GPT-3)的兴起,人工智能正在经历一种范式转变,这些模型基于广泛的数据进行训练(通常使用大规模的自我监督),可以适应广泛的下游任务。我们称这些模型为基础模型,以强调它们关键的中心但不完整的特征。本报告全面介绍了基础模型的机会和风险,从其能力(如语言、视觉、机器人操作、推理、人类交互)和技术原则(如模型架构、培训程序、数据、系统、安全、评估、理论)到其应用(如法律、医疗保健、教育)和社会影响(如不平等、滥用、经济和环境影响、法律和伦理考虑)。虽然基础模型是基于标准的深度学习和迁移学习,但它们的规模产生了新的涌现能力,而它们在许多任务中的有效性激励了同质化。均质化提供了强大的杠杆作用,但需要谨慎,因为基础模型的缺陷被下游所有适应的模型所继承。尽管基础模型即将被广泛部署,但我们目前缺乏对它们如何工作、何时失败以及它们甚至由于它们的突发属性而具备什么能力的清晰理解。为了解决这些问题,我们相信,许多关于基础模型的关键研究将需要与其基本的社会技术本质相称的深度跨学科合作。
Introduction
本报告调查了一个新兴的范式建立人工智能(AI)系统,基于一般的模型,我们称之为基础模型。基础模型是任何基于广泛数据训练(通常使用规模自我监督)的模型,可以适应(例如,微调);当前的例子包括BERT1
、GPT-32和CLIP3。从技术的角度来看,基础模型并不新鲜—它们是基于深度神经网络和自我监督学习的,这两种方法已经存在了几十年。然而,过去几年的基础模型的规模和范围扩展了我们对可能的想象;例如,GPT-3有1750亿个参数,可以通过自然语言提示进行调整,在广泛的任务中做一个体面的工作,尽管没有经过明确的训练。与此同时,现有的基础模型有可能加重危害,但人们对其特征普遍知之甚少。鉴于它们即将被广泛部署,它们已经成为一个被严格关注的话题4。
Emergence and homogenization
基础模型的意义可以用 出现 出现 出现和 同质化 同质化 同质化两个词来概括。出现意味着一个系统的行为是隐式诱导的,而不是显式构建的;它既是科学上的兴奋的来源,也是对意外后果的焦虑的来源。同质化表示在广泛的应用中整合了构建机器学习系统的方法;它为许多任务提供了强大的杠杆,但也产生了单点故障。为了更好地欣赏新兴市场和同质化,让我们反思一下过去30年来它们在人工智能研究中的崛起。

图1。人工智能的故事一直不断出现和同质化。随着机器学习的引入,任务如何执行从例子中出现(自动推断);随着深度学习,用于预测的高级特征出现;有了基础模型,甚至上下文学习等高级功能也出现了。与此同时,机器学习同质化学习算法(如逻辑回归),深度学习同质化模型结构(如卷积神经网络),基础模型将模型本身同质化(如GPT-3)。
机器学习 如今,大多数人工智能系统都是由机器学习驱动的,其中的预测模型是根据历史数据进行训练的,并用于做出未来的预测。人工智能内部机器学习的兴起始于20世纪90年代,代表了之前人工智能系统构建方式的显著转变:学习算法不是指定如何解决任务,而是基于数据诱导它—即,如何从学习的动态中出现。机器学习也代表了迈向同质化的一步:广泛的应用现在可以由单一的通用学习算法,如逻辑回归。
尽管机器学习在人工智能的无处不在,语义复杂的任务在自然语言处理(NLP)和计算机视觉等问题回答或对象识别,输入是句子或图像,仍然需要领域专家执行“特性工程”—即编写特定领域的逻辑转换原始数据到更高级的特性(例如,SIFT5在计算机视觉)更适合流行的机器学习方法。
深度学习 2010年左右,深度神经网络以深度学习的复苏6开始在机器学习领域获得关注。深度学习是由更大的数据集、更多的计算量(特别是gpu的可用性)和更大的大胆性推动的。深度学习是由更大的数据集、更多的计算量(特别是gpu的可用性)和更大的大胆性推动的。深度神经网络将在原始输入(例如,像素)上进行训练,而更高层次的特征将通过训练出现(这个过程被称为“表示学习”)。这导致了在标准基准上的巨大性能提高,例如,在AlexNet7:在ImageNet数据集上的开创性工作中8。深度学习也反映了向同质化的进一步转变:不是为每个应用程序定制相同的特性工程管道,而是相同的深度神经网络架构可以用于许多应用程序。
基础模型基础模型在NLP中形成得最为强烈,所以我们现在就把我们的故事放在那里。也就是说,就像深度学习在计算机视觉中普及,但却存在于计算机视觉之外一样,我们将基础模型理解为人工智能的一般范式,而不是以任何方式特定于NLP。到2018年底,NLP领域即将经历另一次地震变化,标志着基础模型时代的开始。在技术层面上,基础模型可以通过迁移学习9和规模来实现。迁移学习的理念是将从一个任务中学习到的“知识”(如图像中的物体识别),并将其应用到另一个任务中(如视频中的活动识别)。在深度学习中,预训练是迁移学习的主要方法:模型被训练为替代任务(通常只是一种目的手段),然后通过微调适应感兴趣的下游任务。
迁移学习是使基础模型成为可能的原因,但规模也是使它们更强大的原因。规模需要三个要素: (i)计算机硬件的改进——例如,GPU吞吐量和内存在过去四年中增加了10x;(ii)变压器模型架构的开发10,利用硬件的并行性训练比以前更具表现性的模型;(iii)更多培训数据的可用性。
不能低估数据的可用性和利用这些数据的能力的重要性。带注释数据集的迁移学习已经有至少十年的普遍做法,例如,在ImageNet数据集上进行预训练11,用于计算机视觉社区的图像分类。然而,注释的重要代价对预训练的好处施加了实际的限制。
另一方面,在自监督学习中,训练前的任务是由未注释的数据自动生成的。例如,用于训练BERT12的蒙面语言建模任务是预测一个给定其周围上下文的句子(例如,我喜欢豆芽)中缺失的单词。自我监督的任务不仅更可扩展,只依赖于未标记的数据,而且它们被设计成迫使模型预测部分输入,使它们比在更有限的标签空间上训练的模型更丰富、可能更有用。
追溯到单词嵌入,自我监督学习已经取得了相当大的进展[13;14;15],它将每个单词与上下文无关的向量联系起来,为广泛的NLP模型提供了基础。此后不久,基于自回归语言建模的自我监督学习(给出前面的单词预测下一个单词)16开始流行起来。这就产生了在上下文中表示单词的模型,如GPT17、ELMo18和ULMFiT19。
自我监督学习的下一波发展—BERT20GPT-221、RoBERTa21、T522、, BART23—紧随其后,拥抱变压器架构,结合更强大的深度双向句子编码器,并扩展到更大的模型和数据集。
虽然人们可以纯粹通过自我监督学习的角度来看待这最后一波技术发展,但围绕着BERT的引入,存在着一个社会学的拐点。在2019年之前,使用语言模型的自我监督学习本质上是自然语言处理的一个分支领域,它与自然语言处理的其他发展并行发展。2019年以后,使用语言模型的自我监督学习越来越成为自然语言处理的基础,因为使用BERT已经成为常态。接受一个单一的模型可以用于如此广泛的任务,标志着基础模型时代的开始。
基础模型导致了前所未有的同质化水平:几乎所有最先进的NLP模型现在都是从少数几个基础模型中改编而来的,如BERT、RoBERTa、BART、T5等。虽然这种同质化产生了极高的杠杆作用(基础模型的任何改进都可能为所有NLP带来直接利益),但它也是一种负担;所有人工智能系统可能继承一些基础模型的同样的问题偏见[24;25;26,除其他])。
我们也开始看到各个研究界的同质化。例如,类似的基于变压器的序列建模方法现在应用于文本[27;21;22],图像[28;29],演讲30,表格数据31,蛋白质序列32,有机分子33,强化学习34。这些例子指出了一个可能的未来,我们有一套统一的工具来跨广泛的模式开发基础模型35。
除了方法的同质化,我们还看到了整个研究社区中实际模型的多模态模型形式的同质化——例如,基于语言和视觉数据训练的基础模型[36]。在某些领域中,数据自然是多模式的——例如,医疗图像、结构化数据、医疗保健中的临床文本。因此,多模态基础模型是一种融合关于一个域的所有相关信息的一种自然方式,并适应同样跨多个模式的任务(图2)。
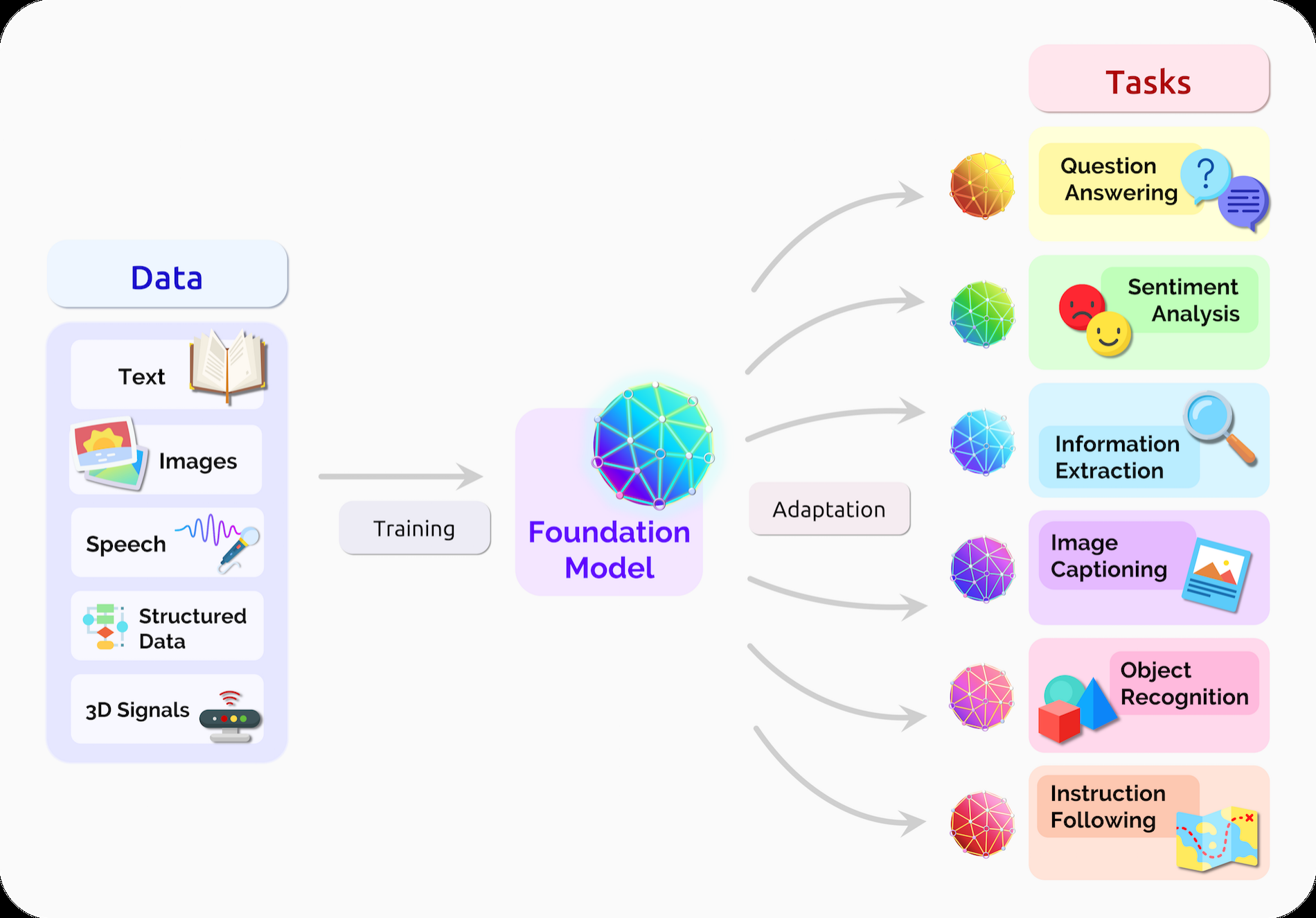
图2。一个基础模型可以集中来自各种模式的所有数据的信息。这个模型可以适用于广泛的下游任务。
基础模型也导致了来自规模的结果的令人惊讶的出现。例如,GPT-337,有1750亿参数与GPT-2的15亿相比,允许上下文学习,语言模型可以适应下游任务只是通过提供一个提示(自然语言描述的任务),一个紧急属性,既不是专门训练也没有预期出现。
均质化和出现以一种潜在的令人不安的方式相互作用。在许多特定任务的数据相当有限的领域提供巨大的收益——看看几个这样的领域的机会(例如,3.1:医疗保健,3.2:law,3.3:教育);另一方面,模型中的任何缺陷都会被所有已适应的模型盲目地继承下来(5.1:公平性,5.6:伦理性)。由于基础模型的力量来自于它们的突发质量,而不是明确的构造,现有的基础模型难以理解(4.4:评价,4.10:理论,4.11:可解释性),它们具有意外的失效模式(4.7:安全性,4.8:鲁棒性)。由于出现对基础模型的能力和缺陷产生了巨大的不确定性,通过这些模型的积极同质化是有风险的业务。从伦理(5.6:伦理)和人工智能安全(4.9:人工智能安全)的角度来看,嘲笑是进一步发展基础模型的核心挑战。
Naming
我们引入了术语基础模型来填补描述我们正在目睹的范式转变的空白;我们简要地叙述了我们对这个决定的一些推理。现有的术语(例如,预训练模型,自我监督模型)部分地捕捉到了这些模型的技术维度,但未能以一种可访问的方式对机器学习之外的人捕捉到范式转变的重要性。特别是,基础模型指定了一个模型类,它们在社会学影响上,以及它们如何赋予人工智能研究和部署的广泛转变。相比之下,技术上预示着基础模型的预训练和自我监督形式未能阐明我们希望强调的实践的转变。

图3。在推理基础模型的社会影响之前,重要的是要理解它们是从数据创建到部署的更广泛的生态系统的一部分。在两端,我们都强调了人们作为基础模型培训的最终数据来源的角色,但同时也作为任何利益和危害的下游接受者。经过深思熟虑的数据管理和适应应该是任何人工智能系统负责任的开发的一部分。最后,请注意,自适应的基础模型的部署是一个独立于其构建的决策,这可以用于研究。
此外,尽管在写作时的许多标志性的基础模型都是语言模型,但术语语言模型对于我们的目的来说太窄了:正如我们所描述的,基础模型的范围远远超出了语言。我们还考虑了通用模型和多用途模型等术语,这些术语捕获了这些模型可以服务于多个下游任务的重要方面,但都未能捕捉到它们未完成的特性和适应的需要。诸如任务不可知论模型这样的术语将捕获训练的方式,但不能捕获对下游应用程序的重要影响。
我们选择了新的术语基础模型来确定作为本报告主题的模型和新兴的范式。特别是,“基础”这个词指定了这些模型所扮演的角色:基础模型本身是不完整的,但作为许多特定任务模型的共同基础。我们还选择了术语“地基”来暗示建筑的稳定性、安全和安全性的重要性:建造不良的地基是灾难的根源,而执行良好的地基是未来应用的可靠基础.目前,我们强调,我们还没有完全了解基础模型所提供的基础的性质或质量;我们无法确定这个基础是否值得信赖。因此,这对于研究人员、基础模型提供者、依赖于基础模型的应用程序开发人员、决策者和整个社会来说都是一个关键问题。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Association for Computational Linguistics (ACL). 4171–4186. ↩︎
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165 (2020). ↩︎
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020 (2021). ↩︎
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (Virtual Event, Canada) (FAccT ’21). Association for Computing Machinery, New York, NY, USA, 610–623. ↩︎
David G Lowe. 1999 1999. Object recognition from local scale-invariant features. In International Conference on Computer Vision (ICCV) Proceedings of the seventh IEEE international conference on computer vision, Vol. 2. 1150–1157. ↩︎
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep Learning. Nature 521, 7553 (2015). ↩︎
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 25 (2012), 1097–1105. ↩︎
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition (CVPR). 248–255. ↩︎
Sebastian Thrun. 1998. Lifelong learning algorithms. Learning to learn (1998), 181–209. ↩︎
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. arXiv preprint arXiv:1706.03762 (2017). ↩︎
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition (CVPR). 248–255. ↩︎
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Association for Computational Linguistics (ACL). 4171–4186. ↩︎
Joseph Turian, Lev Ratinov, and Yoshua Bengio. 2010. Word representations: a simple and general method for semi-supervised learning. In Association for Computational Linguistics (ACL). 384–394. ↩︎
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781 (2013). ↩︎
Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. GloVe: Global Vectors for word representation. In Empirical Methods in Natural Language Processing (EMNLP). 1532–1543. ↩︎
Andrew M. Dai and Quoc V. Le. 2015. Semi-supervised sequence learning. In Advances in Neural Information Processing Systems (NeurIPS). ↩︎
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training. Technical Report. OpenAI. ↩︎
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In North American Association for Computational Linguistics (NAACL). ↩︎
Jeremy Howard and Sebastian Ruder. 2018. Universal language model fine-tuning for text classification. In Association for Computational Linguistics (ACL). ↩︎
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Association for Computational Linguistics (ACL). 4171–4186. ↩︎
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog 1, 8 (2019). ↩︎ ↩︎ ↩︎
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683 (2019). ↩︎ ↩︎
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2020a. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Association for Computational Linguistics (ACL). ↩︎
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In Advances in Neural Information Processing Systems, D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett (Eds.), Vol. 29. Curran Associates, Inc. ↩︎
Aylin Caliskan, Joanna J. Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases. Science 356, 6334 (2017), 183–186. ↩︎
Abubakar Abid, M. Farooqi, and J. Zou. 2021. Persistent Anti-Muslim Bias in Large Language Models. ArXiv abs/2101.05783 (2021). ↩︎
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Association for Computational Linguistics (ACL). 4171–4186. ↩︎
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations. ↩︎
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. 2020d. Generative Pretraining From Pixels. In Proceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119), Hal Daumé III and Aarti Singh (Eds.). PMLR, 1691–1703. ↩︎
Andy T. Liu, Shuwen Yang, Po-Han Chi, Po-Chun Hsu, and Hung yi Lee. 2020d. Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2020), 6419–6423. ↩︎
Pengcheng Yin, Graham Neubig, Wen tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. In ACL. ↩︎
Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. 2021. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences. Proceedings of the National Academy of Sciences 118, 15 (2021). ↩︎
Daniel Rothchild, Alex Tamkin, Julie Yu, Ujval Misra, and Joseph Gonzalez. 2021. C5T5: Controllable Generation of Organic Molecules with Transformers. ArXiv abs/2108.10307 (2021). ↩︎
Michael Janner, Qiyang Li, and Sergey Levine. 2021. Reinforcement Learning as One Big Sequence Modeling Problem. ArXiv abs/2106.02039 (2021). ↩︎
Alex Tamkin, Vincent Liu, Rongfei Lu, Daniel Fein, Colin Schultz, and Noah Goodman. 2021b. DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning. arXiv:2111.12062 [cs.LG] ↩︎
Wonjae Kim, Bokyung Son, and Ildoo Kim. 2021a. ViLT: Vision-and-language transformer without convolution or region supervision. In International Conference on Machine Learning (ICML). ↩︎
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165 (2020). ↩︎
这篇关于On the Opportunities and Risks of Foundation Models-Introduction(Emergence and homogenization)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)




