本文主要是介绍MindSpore21天实战营手记(三) :基于ResNet50的毒蘑菇识别模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
完于2020年11月3日
以前学华为大数据的时候做到过蘑菇识别问题。实验是基于UCI mushroom dataset,预测检测样本是有毒的还是可食用的。数据集有8000多个样本,22个属性。我记得实验第一步是做属性间的相关性分析,把相关度高的属性剔除掉,达到降维加快计算的目的。不过UCI数据中的属性都是经过人提炼的结构化数据,把每个品种的蘑菇的几十个特性用人工抽取出来,感觉工作量巨大。相对来说,ResNet50“看图说话”的本领很厉害,直接识别图片中的蘑菇属于什么品种,是否有毒,显然用ResNet50更省时省力。
作业过程
MindSpore的ResNet50不但功能很牛,而且无论是做训练还是推理,ModelArts已经考虑得很周全,界面交互清晰简洁,在线应用起来超级简单。
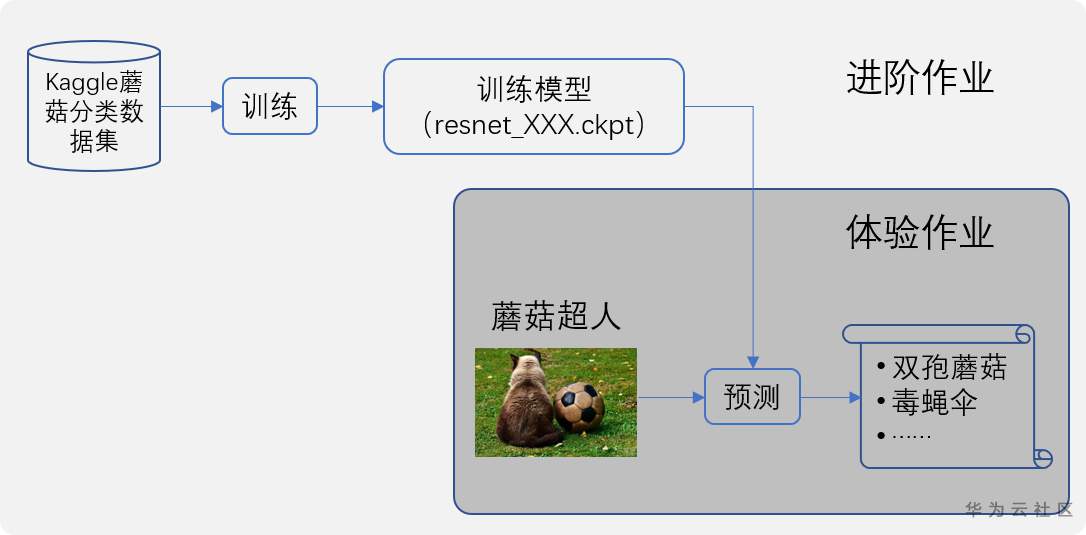
与前两次课一样,学员需要完成体验作业和进阶作业。老师提供了详细的作业指南(附后),关键步骤都做了图文说明,完全作业几乎没有任何难度:
-
体验作业要求上传一张“蘑菇超人”图片(任何图片,不限制必须是蘑菇),让模型推测图片中的“蘑菇”属于哪个品种,有没有毒。
-
进阶作业增加训练的过程,训练数据来自Kaggle mushrooms classification数据集,然后再用训练好的模型预测上传图片中的“蘑菇超人”是否有毒。
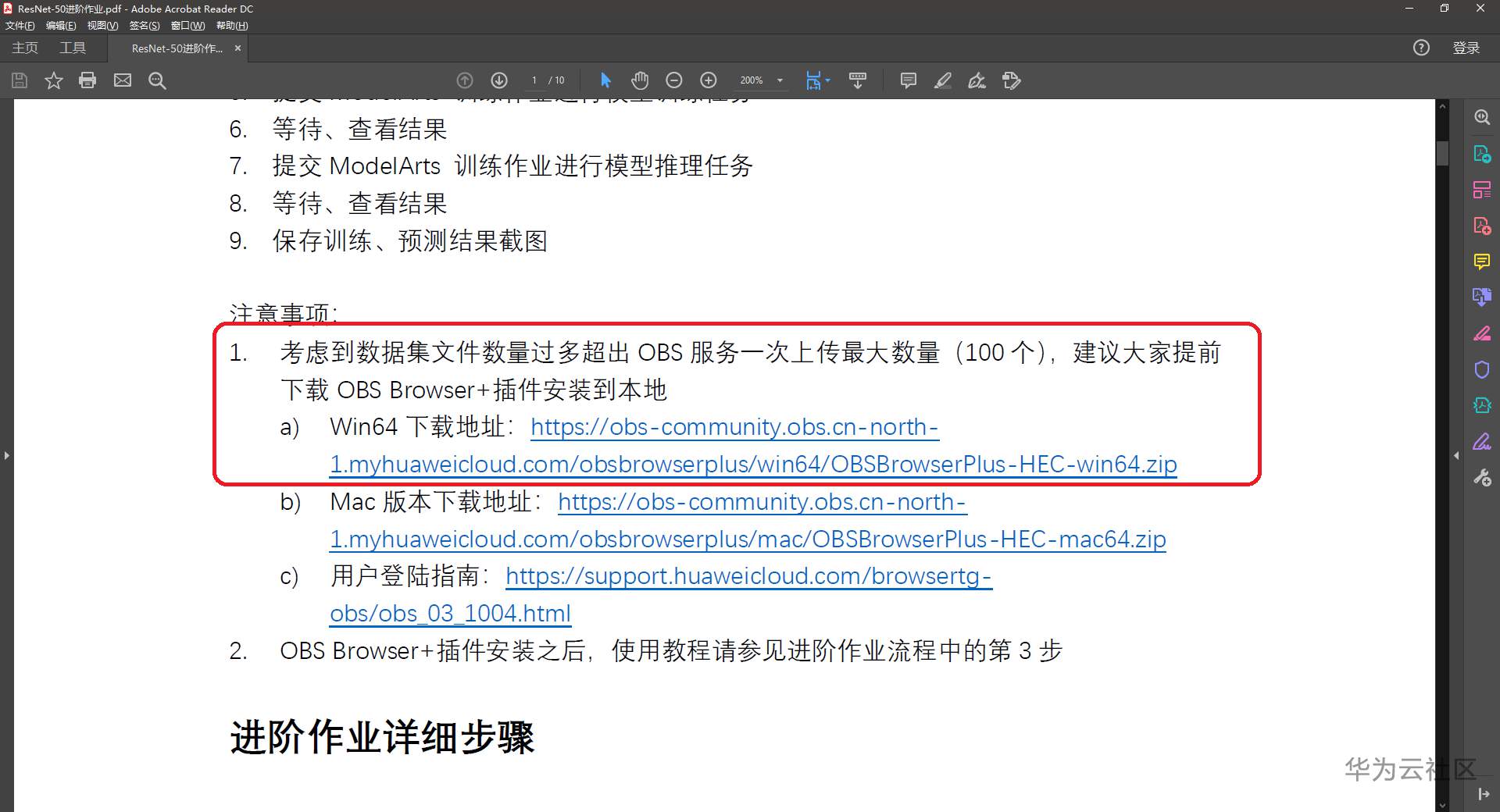
进阶作业需要上传超过上传6000张图片,而通过OBS网页每次最多只能传100个文件。作业指南里提到了要使用OBS Browser+文件传输工具,但没有展开讲安装和配置。其实这个过程并不难。
-
按进阶作业指南中提供的链接,下载OBS Browser+。我用Windows10家庭版,就下载Win64版本。
-
安装完成,启动“obs-browser-plus”。点击下方的“获取AccessKey”。
-
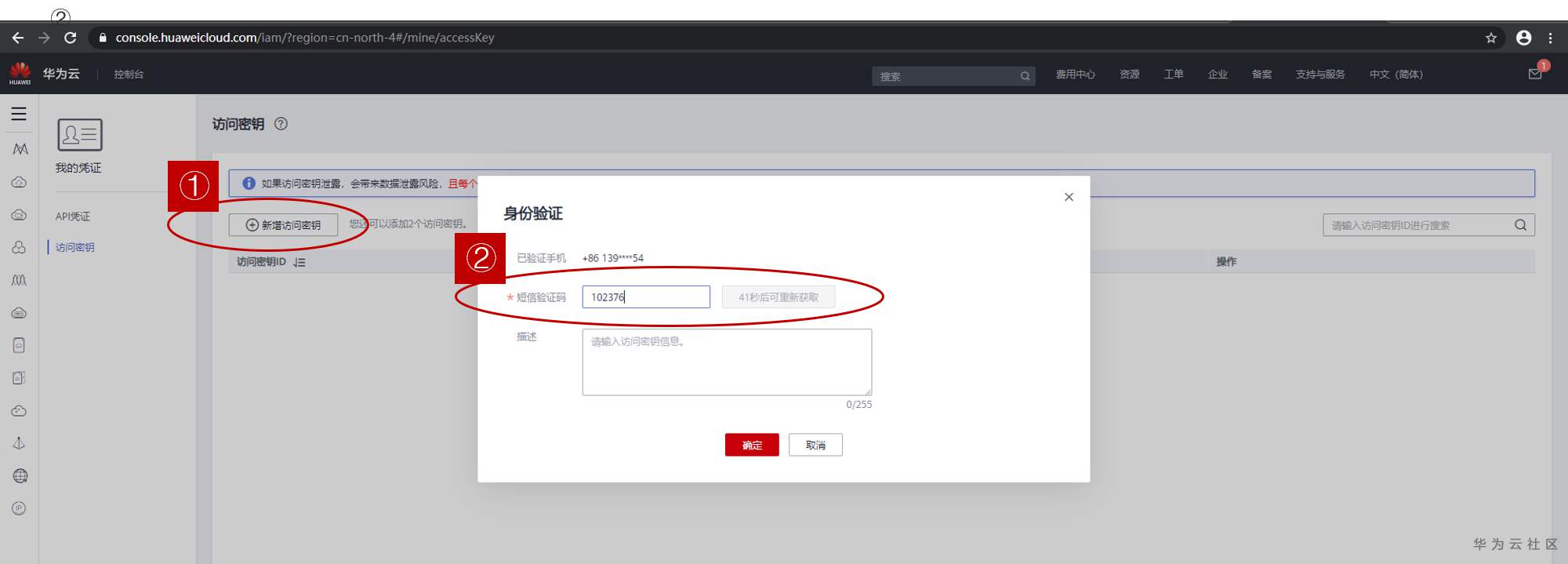
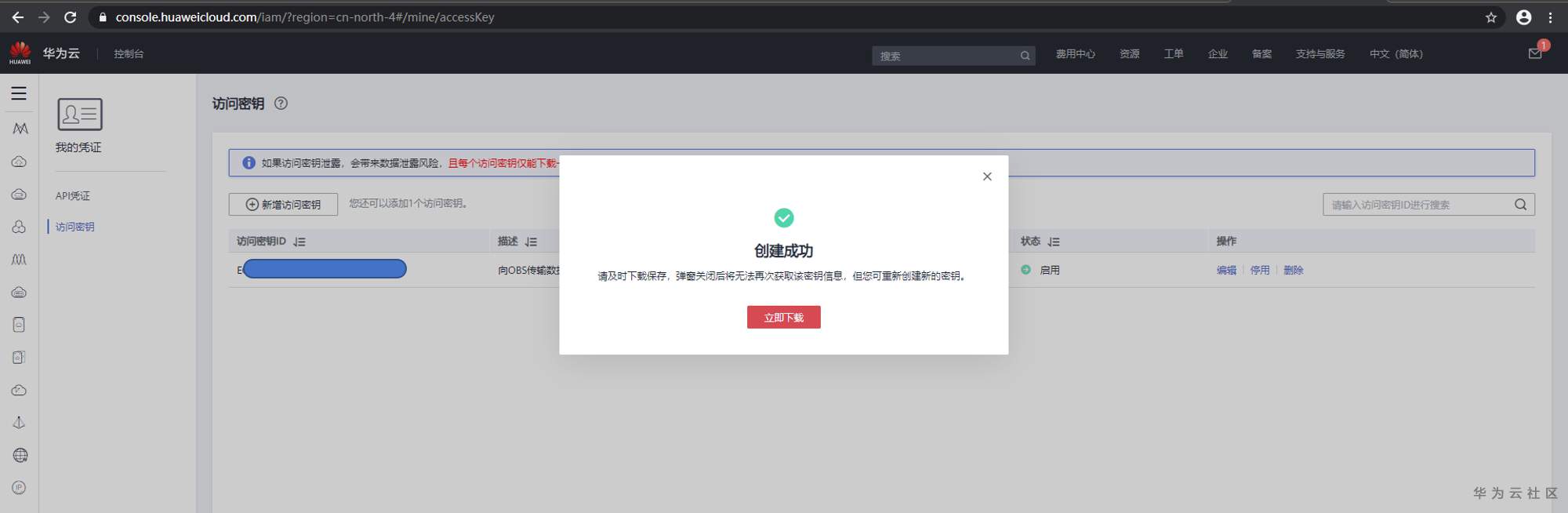
弹出浏览器,导向“华为云”的“访问密钥页面。①点”新建访问密钥“,②在弹出的“身份验证”界面上,获取并填写“短信验证码”,点“确定“。
-
系统显示创建成功,并提示下载。点击”立即下载“,获取credentials.csv密钥文件。密钥文件一定要保存好。我想再次下载,但找不到入口了。
-
打开credentials.csv文件,按下图示将对应关系,把字段信息拷贝到OBS Browser+窗口对应的文本框内。在”服务提供商“中选择”华为对象存储服务(默认)”,在“访问路径”中手工填写新建的obs桶的根目录。点击“登录”。

-
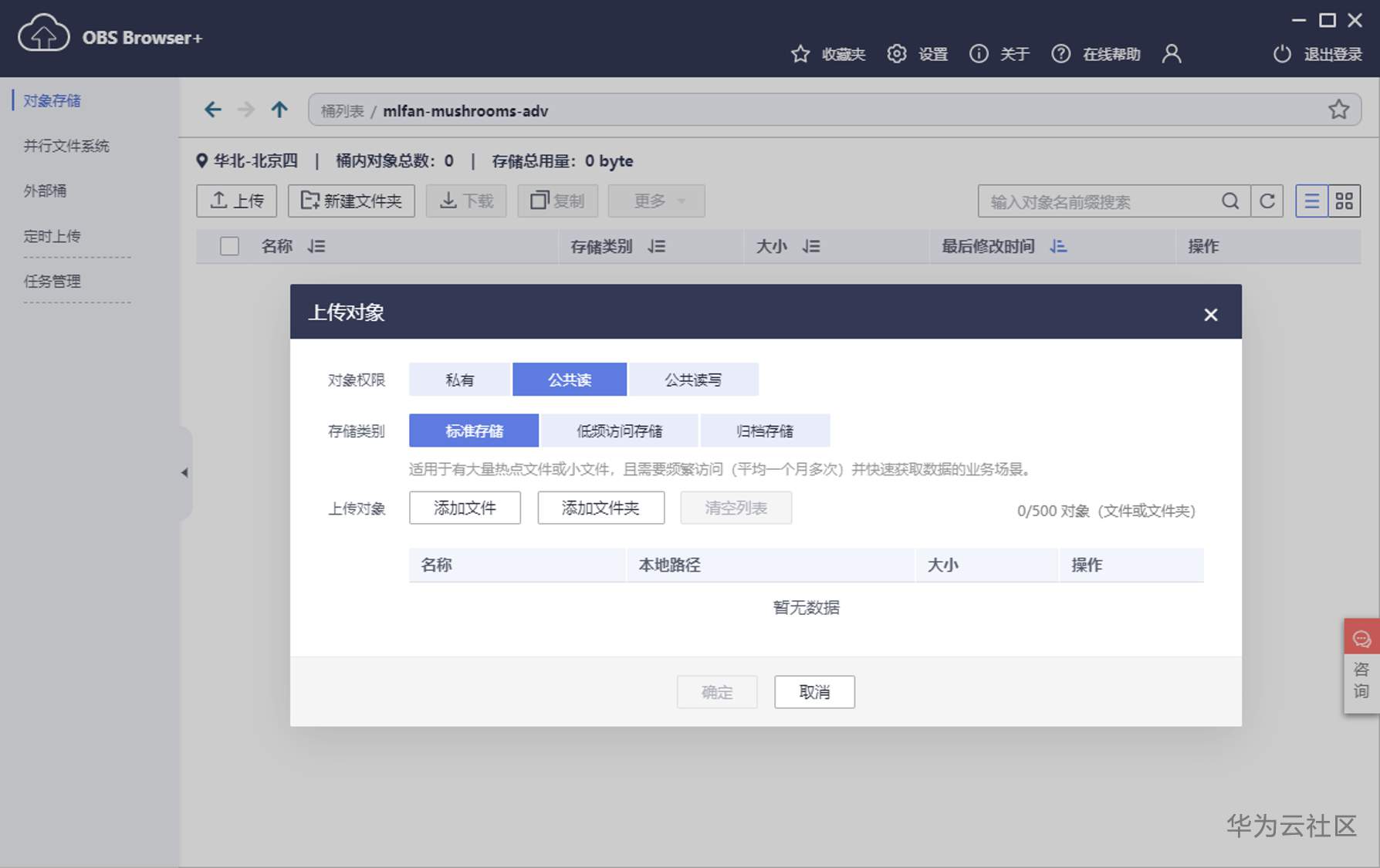
接下来就可以舒舒服服地传文件了,没有文件数量的限制,而且不但可以添加文件,还可以添加文件夹,非常人性化。
-
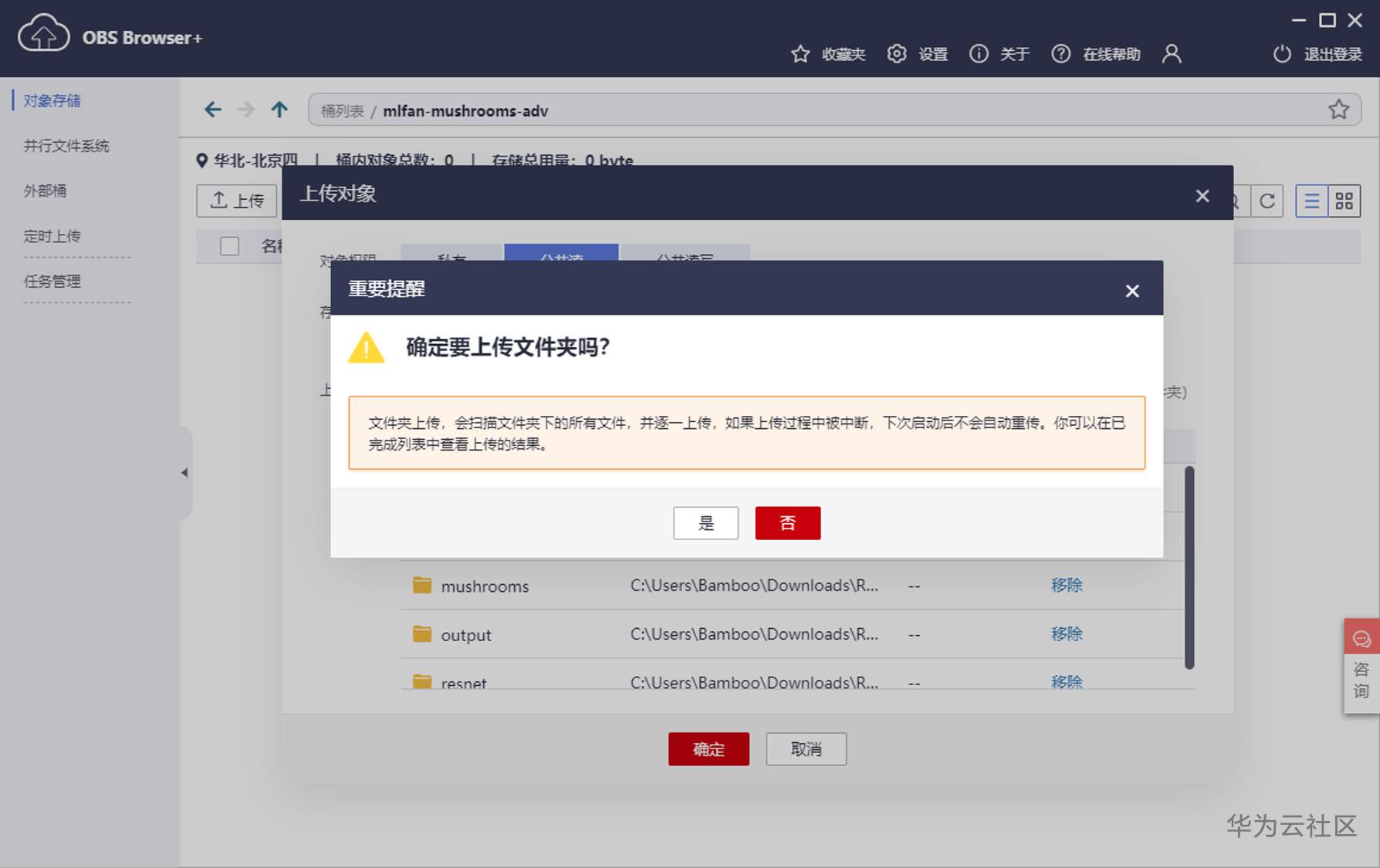
不过当上传文件启动时,系统会有下面“中断重启不会自动重传”的提示。所以如果文件非常多的情况下,最好还是规划一下文件上传的策略,免得中断重启之后麻烦。这点感觉不是太方便。
写在最后
体验作业的推理过程不用一分钟就能完成,进阶作业的训练过程需要十分钟左右的时间,都不需要等太长时间。
前课笔记:
MindSpore21天实战营手记(一):基于MindSpore Lite开发端侧AI图像分类应用
MindSpore21天实战营手记(二) :基于Bert进行中文新闻分类
转自文章链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=85549
感谢作者的努力与分享,侵权立删!
这篇关于MindSpore21天实战营手记(三) :基于ResNet50的毒蘑菇识别模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







