本文主要是介绍文章:Emotion Recognition From Speech With Recurrent Neural Networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://blog.csdn.net/vvnzhang2095/article/details/79993058
代码部分:https://github.com/vladimir-chernykh/emotion_recognition
1. 背景与简介
1.1. 现状
计算机只能识别“说了什么”,无法识别“谁说的”、“怎样说”。
1.2. 目标
关注“怎样说”,识别说话者的情感。
1.3. 困难
(1)一句话的情感是什么因人而异,因此很难定义某句话的情感是什么;
(2)经常会遇到的情况是,整句话没什么情感,但中间几个词带有情感。
1.4. 工作
(1)在语音情感识别中应用了CTC损失函数,从而可以识别一个较长的包含有情感的部分和没有情感部分的utterance(句子),从而解决上述的第二个困难。
(2)可以预测一个句子的情感状态序列。
2. IEMOCAP数据描述
2.1. 基本信息
包含10个演员的音频+视频信息,时长为12小时,每一段录音都是一男一女对话。
2.2. 处理
将对话分成小的utterances(句子),每一个长度基本都是3-15秒,然后让专家去评估这些话的情感。句子按照性别被分为两种。Label有10个种类:neutral(中立)、happiness(开心)、sadness(伤心)、anger(生气)、surprise(惊喜)、fear(害怕)、disgust frustration(厌恶)、excited(兴奋)等。本文只讨论四种:anger、excitement、neutral、sadness。
值得一提的是,只有在超过一般的专家都同意这句话为某种情感的时候,这句话才会被打上标签。
2.3. 特征
(1)Acoustic features(声学特征):比如波、信号、语调等。
(2)Prosodic features(声韵特征):比如词之间的停顿、韵律、声音大小等。但是这些特征的问题在于它会依赖于说话者。
(3)Linguistic features(语言学特征):语义特征。但是问题在于这是声音,我们并不能得到精确的台词,无法得到说话内容。
这篇文章只用了acoustic features,总共34个特征。文章对所有声音段都进行如下处理:利用0.2秒的窗口,每次滑动0.1秒,计算特征。
3. 问题描述
本质上就是一个多分类问题。
训练集:
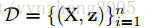
特征:

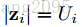

注意特征序列的长度和真实label序列的长度一般来说不会相等,真实label序列长度会小于等于特征序列的长度,即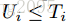
举个例子,一个人说“你好“,表现出来的可能是n-n-n-i-i-h-a-a-o-o-o,但输出的就只有nihao。这里跟CTC方法的提出很有关系,之后会解释为什么。
目标:找到分类器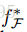
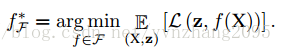
4. 方法
这里用几个RNN模型结合两种方法进行。
4.1. One-label方法
定义:无论utterance多长,每个utterance只有一个情感label。回顾一下IEMOCAP数据集,它的标记方法就属于这种。所以这个时候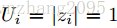
把通过分类器预测出来的值记为
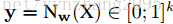
loss函数:
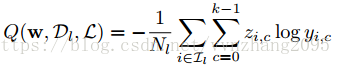
不足:
(1)无论utterance长度多长都只转换成一个label
(2)做在线学习的时候,不会有已经分割好的utterance,因此很难再根据一个一个的utterance去预测label值。
过程图:

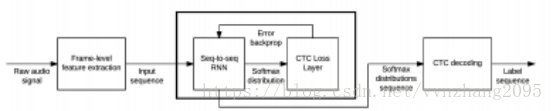
4.2. CTC(Connectionist Temporal Classification,联结主义时间分类器)
定义:一种end-to-end(端到端)计算损失函数的方法,一个utterance不再是只能有一个label了,而是有一个label序列。
引用知乎用户@火华 对CTC的一个解释,可以看到CTC是用来解决输入输出长度不一时用传统的损失函数无法计算的问题:
RNN模型可以用来对两个序列之间的关系进行建模。但是,传统的RNN,标注序列和输入的序列是一一对应的。语音识别中的序列建模问题不是这样:识别出的字符序列或者音素序列长度远小于输入的特征帧序列。所以不能直接用RNN来建模。CTC解决这一问题的方法是,在标注符号集中加一个空白符号blank,然后利用RNN进行标注,最后把blank符号和预测出的重复符号消除。比如有可能预测除了一个"--a-bb",就对应序列"ab"。这样就让RNN可以对长度小于输入序列的标注序列进行预测了。
至于为什么叫端对端,知乎用户@王赟 Maigo 给出了回答:
传统的语音识别系统,是由语音模型、词典、语言模型构成的,而其中的语音模型和语言模型是分别训练的。这就造成每一部分的训练目标(语音模型的likelihood,语言模型的perplexity)都与整个系统的训练目标(word error rate)不一致。而使用了CTC之后,从语音特征(输入端)到文字串(输出端)就只有一个神经网络模型(这就叫“端到端”模型),可以直接用WER的某种proxy作为目标函数来训练这个神经网络,避免花费无用功去优化一个别的目标函数。
额外处理:
既然是要给出label序列,即给出更多的utterance内部的情感细节,而不是简单地给一个句子贴上一个label了,就可能会出现一个情况:一个utterance里面可能有情绪,可能没有情绪。所以这时候要加上一个label叫NULL,因此label集合变成:
把通过分类器预测出来的值记为
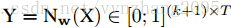
计算步骤:
(1)对于每个输入X,定义一条长度为T的path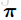
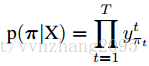
其中,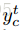
打个比方,现在有一个输入X,它是“你好”的特征,它的真实label序列为“nihao”,一共有30帧。
需要注意的是,即使在训练集中,真实的每一帧label也是无法得知的。因为训练集只给了真实label序列“nihao”,并不会给出具体每一帧是对应哪个label。我们不妨假设它真实情况下每一帧可能会长这样:nnnnnnniiiiihhhh....ooo(一共30帧)。
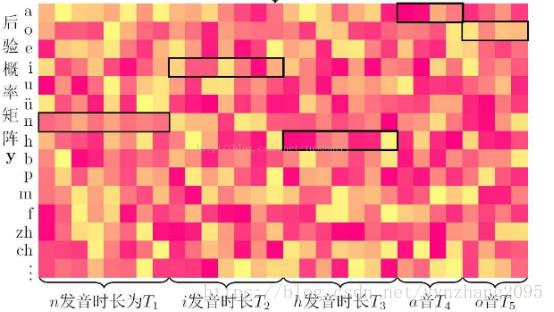
训练后,每一帧输出都有14个音素(音素就是a,o,i,e,u,n,p,...),比如第一帧真实label为n(但注意,如上所述,我们是不知道它是哪个label的),那t=1的时候,我们就用t=1,c=n对应的y;比如第二帧真实label为n,我们就用t=2,c=n对应的y……最后把T个时刻的对应y都乘起来,就得到这个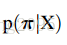
下面这张图可能会看的清晰一点:
(2)接下来通过对path删掉所有连续重复的label和删去所有的NULL,把path转换成label序列的形式。所以会有类似这样的形式:M(-aa-b-b--ccc)=M(abb---bc-)=abbc,“-aa-b-b--ccc”和“abb---bc-”都是path,而“abbc”则是label序列。于是可以计算出每一个label序列的概率:

继续用上面的例子说明。我在上面提到,真实的每一帧label是不知道的,训练集能告诉模型的只有真实的label序列“nihao”,所以我们要把所有可能的每一帧label序列加起来。比如说,“nihao”可能的30帧label序列可能是“nnniiiiihhhaaaooo..oo”,也有可能是“niiiiiiiiiiiihh...aaaoo”,我们需要把所有这些可能的序列概率都加起来,就得到“nihao”的概率。
这一步直接穷举的话计算会很复杂,可以用HMM里面的前向后向算法进行计算。
(3)用最大似然法更新权重w,等同于最小化下式:
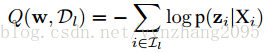
还是上面的例子,“nihao”只是众多输入的X里面的一个。还有许许多多比如“buxiangqichuang”、“zhixiangchi”等等语音,同样按(1)和(2)进行计算,然后把这些语音的概率值进行log变换后再求和就得到这条式子。接着不断更新权重,使这条式子最小时达到最优。
(4)利用下式做预测:
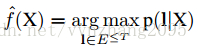
比如现在来了一段语音,真实label序列为“nizhenmei”,用上面更新好的权重算出所有可能的label序列,比如“nizhenshou”、“nizhenhaokan”、“meibumei”……最后取概率最大的那个label序列作为预测值。
过程图:
5. 实验
因为实验里面有些细节我还不太看得明白,所以就大致画了一下文章里都做了什么样的实验,以及进行了什么结果对比,有机会再来补充吧:
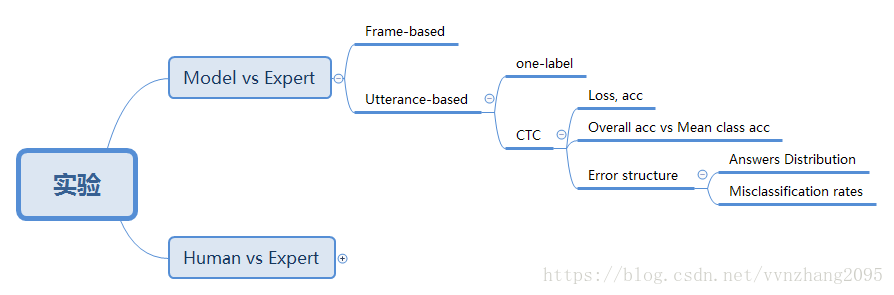
补充说明:
文章做的实验主要是Model vs Expert的三种方法(Frame-based、Utterance-based的one-label和Utterance-based的CTC)、Human vs Expert。上图我只画了CTC实验里进行了什么结果对比,其他没写,因为CTC的实验分析方法最为详尽,包含了其他实验的分析方法。
Model vs Expert里面的这三种方法都需要和RNN网络(LSTM/BLSTM)结合。
End. 未搞懂的问题:
1. one-label的方法相当于IEMOCAP数据集的标记方法,就是每一个utterance给一个label。但CTC的一个utterance一个label序列要怎么得到呢?文章第七页其实有提到没有label的问题,但是没讲到怎么解决。
2. 文章在开始讲所有实验之前就说,utterance是变长的,所以他们把utterance分割成0.2秒长度的帧,然后以0.1秒滑动,那utterance-based到底是以这个0.2秒长度的“utterance”为utterance,还是以原来的utterance为utterance?
3. 实验部分的细节还没看懂。
这篇关于文章:Emotion Recognition From Speech With Recurrent Neural Networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!