本文主要是介绍目标识别:Bag-of-words表示图像,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载至:https://www.cnblogs.com/shihuajie/p/5782515.html
BOW (bag of words) 模型简介
Bag of words模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。举个例子,有如下两个文档:
文档一:Bob likes to play basketball, Jim likes too.
文档二:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”,8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数(下文中,将用单词的直方图表示)。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序(这是本Bag-of-words模型的缺点之一,不过瑕不掩瑜甚至在此处无关紧要)。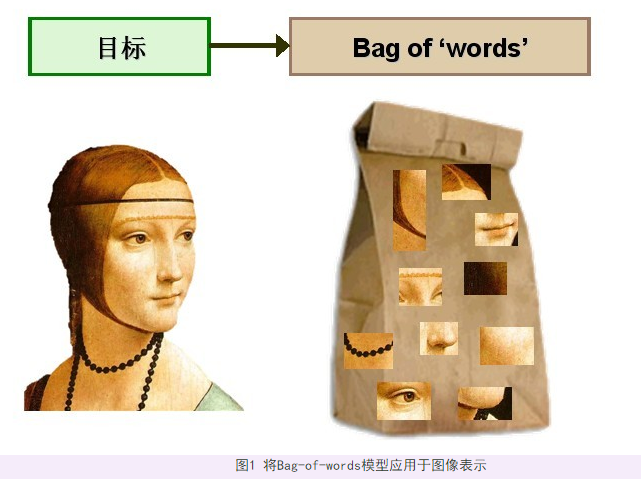
为什么要用BOW模型描述图像
SIFT特征虽然也能描述一幅图像,但是每个SIFT矢量都是128维的,而且一幅图像通常都包含成百上千个SIFT矢量,在进行相似度计算时,这个计算量是非常大的,通行的做法是用聚类算法对这些矢量数据进行聚类,然后用聚类中的一个簇代表BOW中的一个视觉词,将同一幅图像的SIFT矢量映射到视觉词序列生成码本,这样每一幅图像只用一个码本矢量来描述,这样计算相似度时效率就大大提高了。

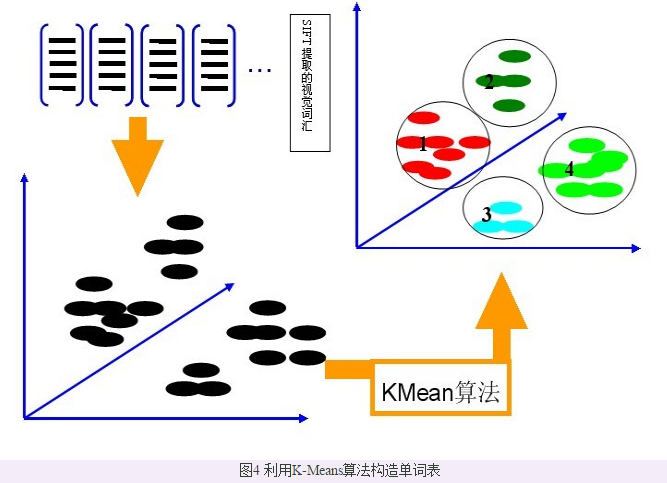
构建BOW码本步骤:
1. 假设训练集有M幅图像,对训练图象集进行预处理。包括图像增强,分割,图像统一格式,统一规格等等。
2、提取SIFT特征。对每一幅图像提取SIFT特征(每一幅图像提取多少个SIFT特征不定)。每一个SIFT特征用一个128维的描述子矢量表示,假设M幅图像共提取出N个SIFT特征。
3. 用K-means对2中提取的N个SIFT特征进行聚类,K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。聚类中心有k个(在BOW模型中聚类中心我们称它们为视觉词),码本的长度也就为k,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中(即将该视觉词的对应词频+1)。
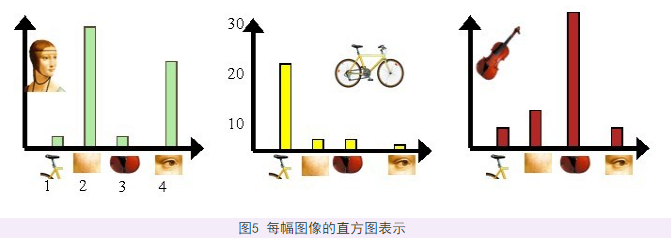
完成这一步后,每一幅图像就变成了一个与视觉词序列相对应的词频矢量。
设视觉词序列为{眼睛 鼻子 嘴}(k=3),则训练集中的图像变为:
第一幅图像:[1 0 0]
第二幅图像:[5 3 4]......
2. 构造码本。码本矢量归一化因为每一幅图像的SIFT特征个数不定,所以需要归一化。如上述例子,归一化后为[1 0 0],1/12*[5 3 4].测试图像也需经过预处理,提取SIFT特征,将这些特征映射到为码本矢量,码本矢量归一化,最后计算其与训练码本的距离,对应最近距离的训练图像认为与测试图像匹配。
当然,在提取sift特征的时候,可以将图像打成很多小的patch,然后对每个patch提取SIFT特征。
总结一下,整个过程其实就做了三件事,首先提取对 n 幅图像分别提取SIFT特征,然后对提取的整个SIFT特征进行k-means聚类得到 k 个聚类中心作为视觉单词表,最后对每幅图像以单词表为规范对该幅图像的每一个SIFT特征点计算它与单词表中每个单词的距离,最近的+1,便可得到该幅图像的码本。实际上第三步是一个统计的过程,所以BOW中向量元素都是非负的。Yunchao Gong 2012年NIPS上有一篇用二进制编码用于图像快速检索的文章就是针对这类元素是非负的特征而设计的编码方案。
这篇关于目标识别:Bag-of-words表示图像的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









