本文主要是介绍一文教你地平线旭日派X3部署yolov5从训练-->转模型-->部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一文教你地平线旭日派X3部署yolov5从训练,转模型,到部署
近日拿到了地平线的旭日派X3,官方说是支持等效5tops的AI算力,迫不及待的想在上面跑一个yolov5的模型,可谓是遇到了不少坑,好在皇天不负有心人,终于在手册和社区各个大佬的帮助下,终于在板子上推理成功,本文会从训练、模型转换、到部署到旭日派详细说明
1.训练
1.1准备yolov5-2.0源代码
根据地平线社区大佬说明,虽然旭日派X3支持yolov5所有版本,但是只有yolov5-2.0的主干网络算子都跑在BPU上,效果最好,帧率最高
yolov5-2.0源代码
注意yolov5的预训练权重在下载时也要下载对应版本
1.2使用conda创建一个虚拟环境安装相关依赖
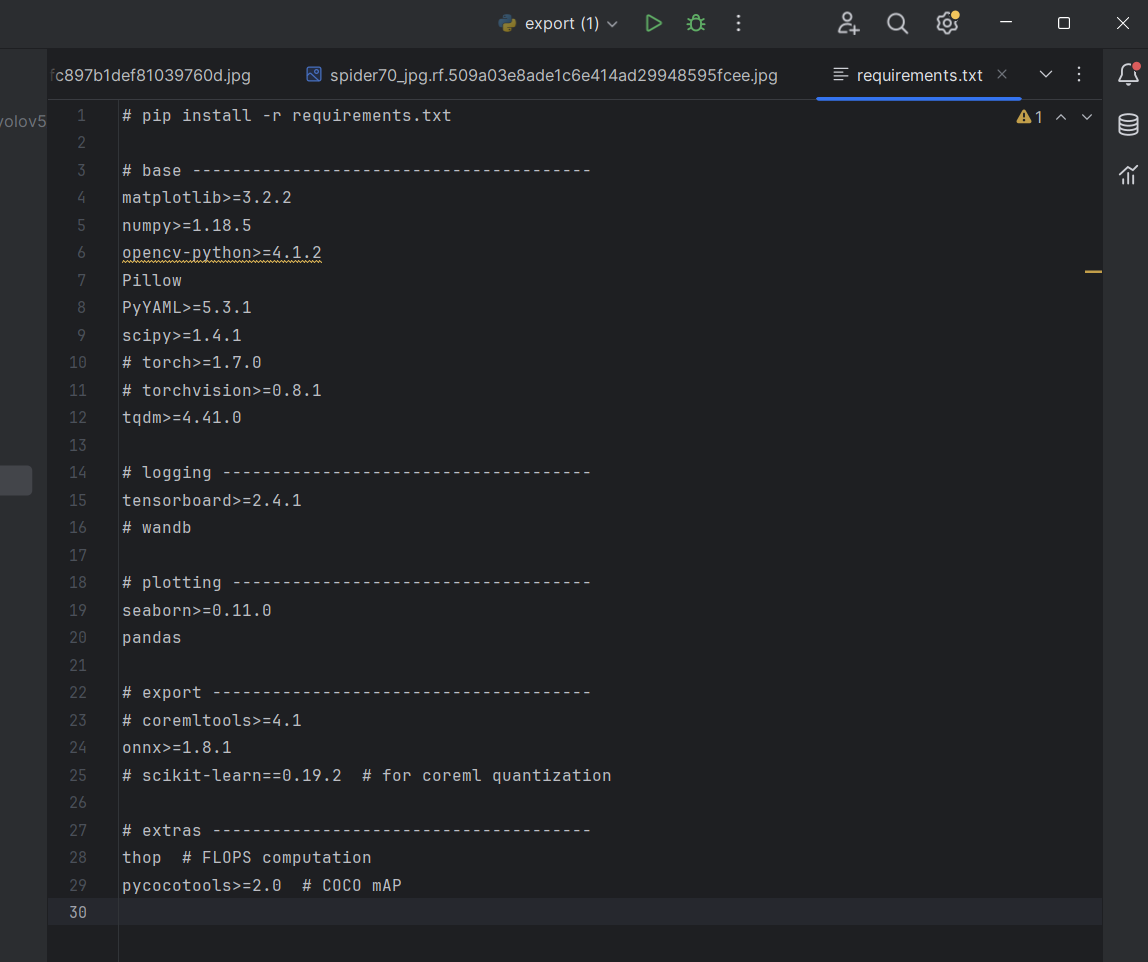
执行pip install -r requirements.txt可以注释掉有关torch的,使用此文件安装torch可能会导致安装cpu版本
1.3准备训练需要的文件
可以在data目录下创建自己的文件夹
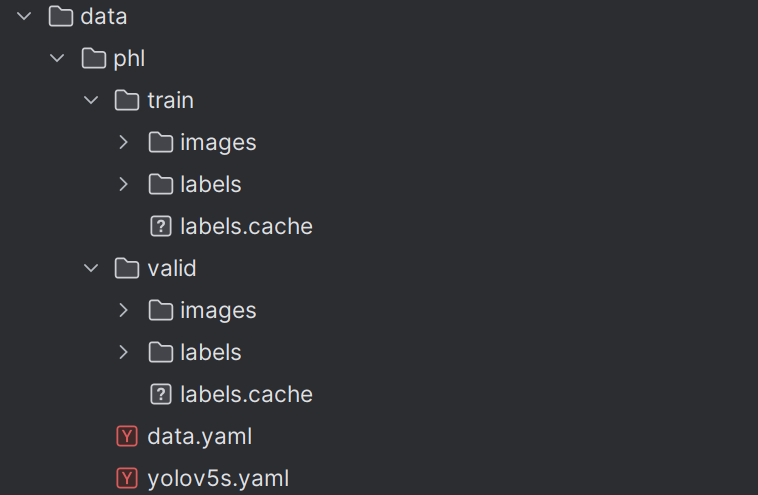
这是最终的目录结构目录结构,images和labels一定要对应,data.yaml和yolov5s.yaml是从其他位置复制过来修改的,下图中的cache缓存文件一定要删除,一定要删除,一定要删除,否则会报错照片找不到
复制data目录下的voc.yaml,改为data.yaml
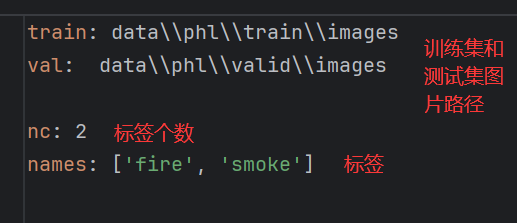
根据自己的需求修改,这个文件夹知名了数据集的路径和标签的种类和个数
复制model目录下的yaml文件,有四种网络结构可供选择
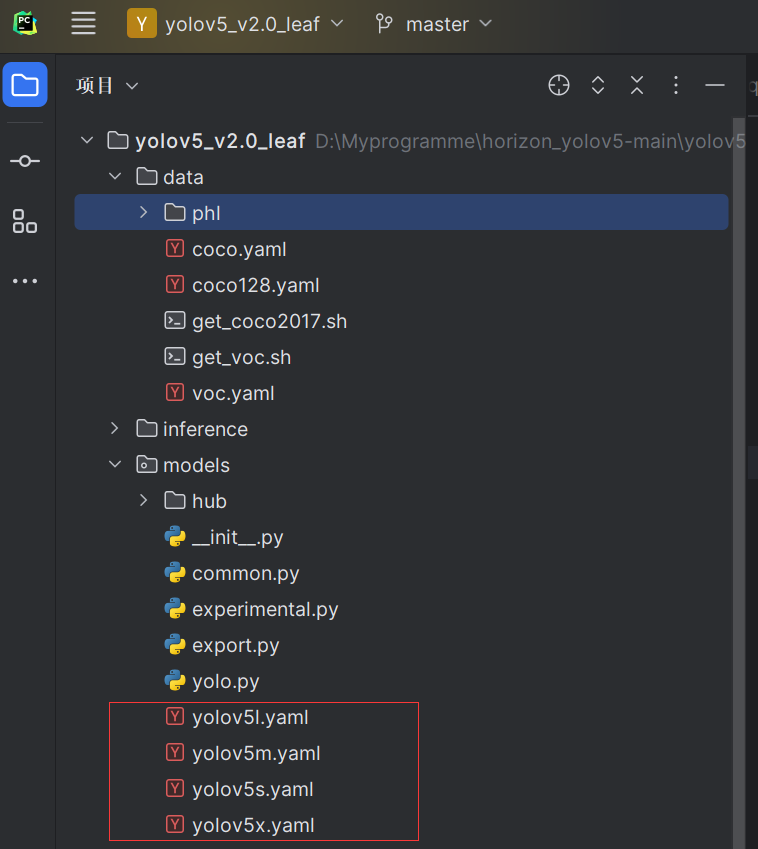
例如我选择的是yolov5s,修改yolov5s.yaml中的nc为自己的标签个数
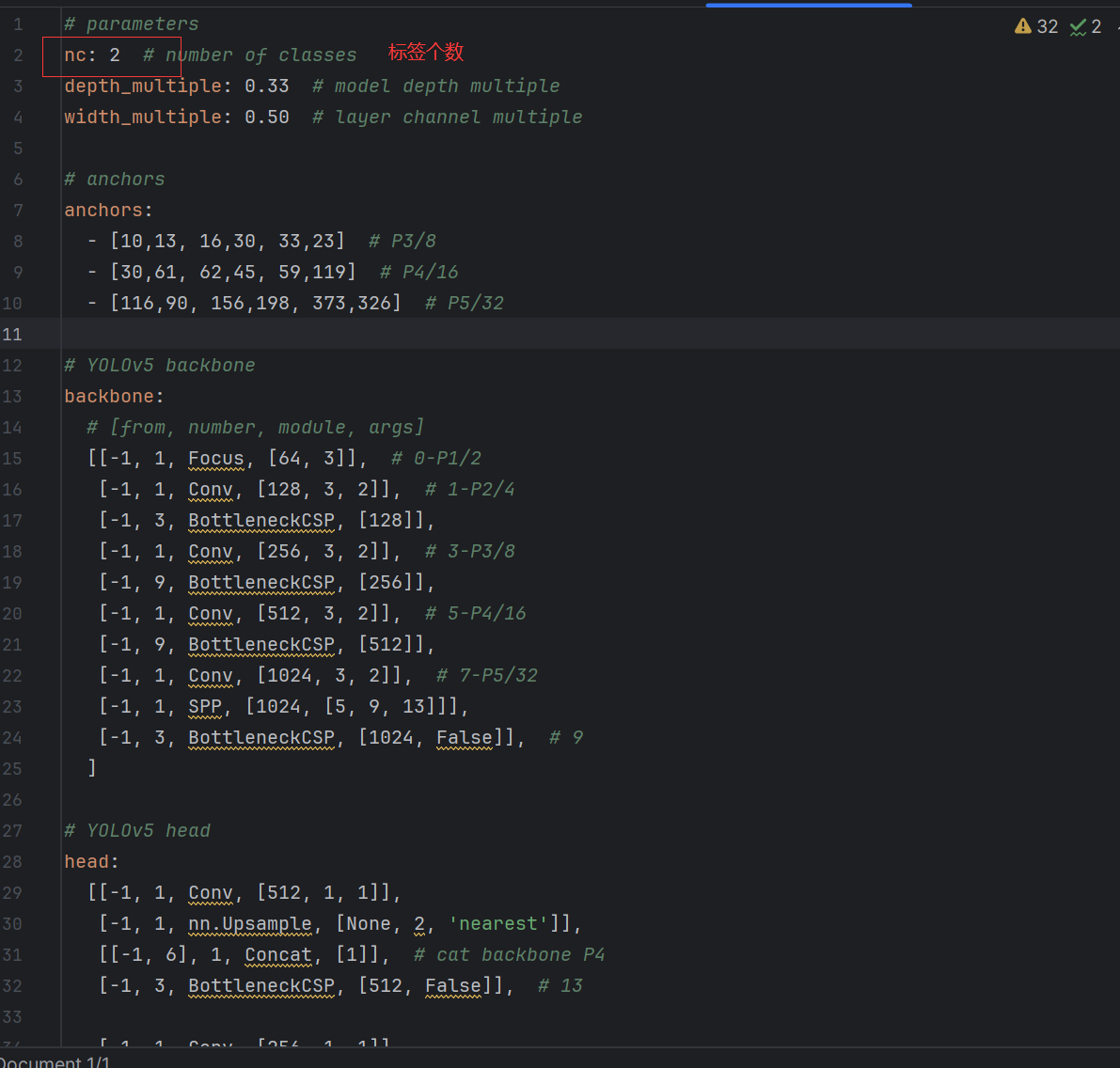
训练所需要的文件就准备好了
1.4修改train.py文件正式开始训练
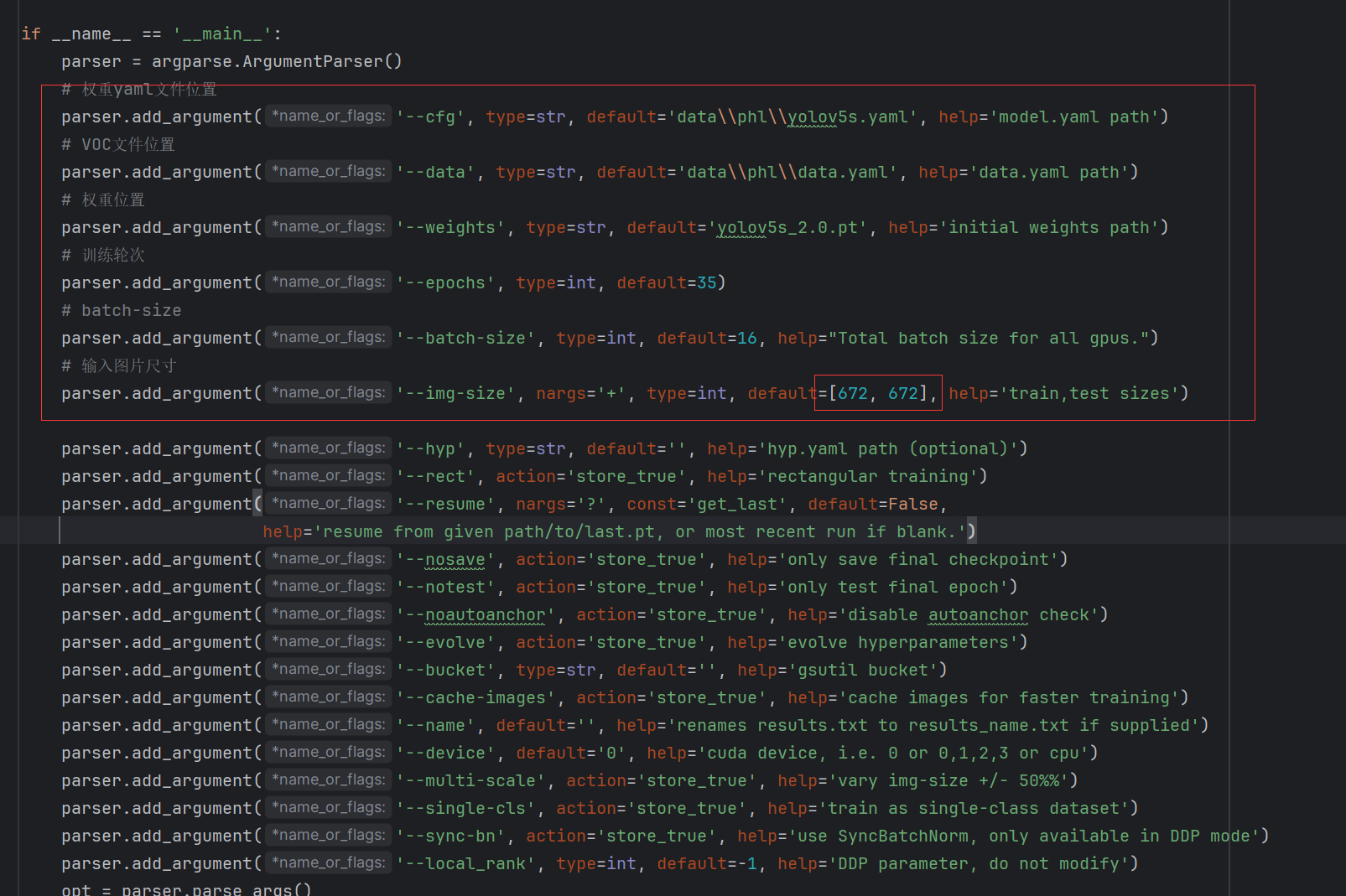
修改红框中这几个default参数
- 注意预训练模型与yolov5s.yaml要对应上
- 输入图片大小最好使用672X672与后续官方例程保持一致
- 训练轮次根据需求自己设置
- batch-size 根据自己显卡的显存设置我是4060 8G版本设置的16
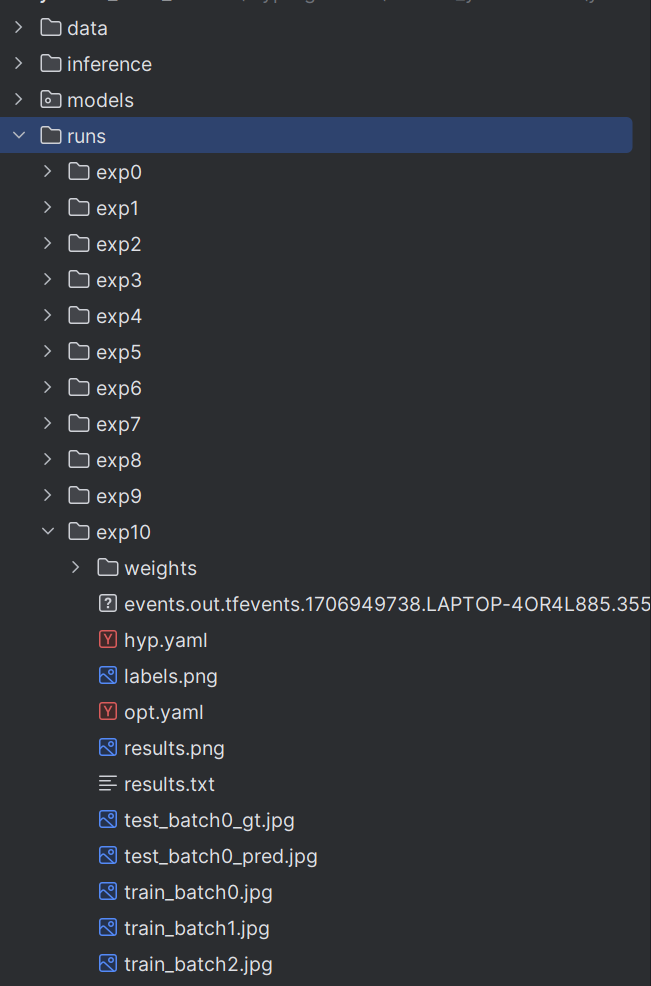
之后就可以运行train.py文件开始训练,模型保存在根目录下的runs文件夹下的exp文件夹下的weight文件夹,也可以查看训练的收敛情况图片
1.5导出onnx模型
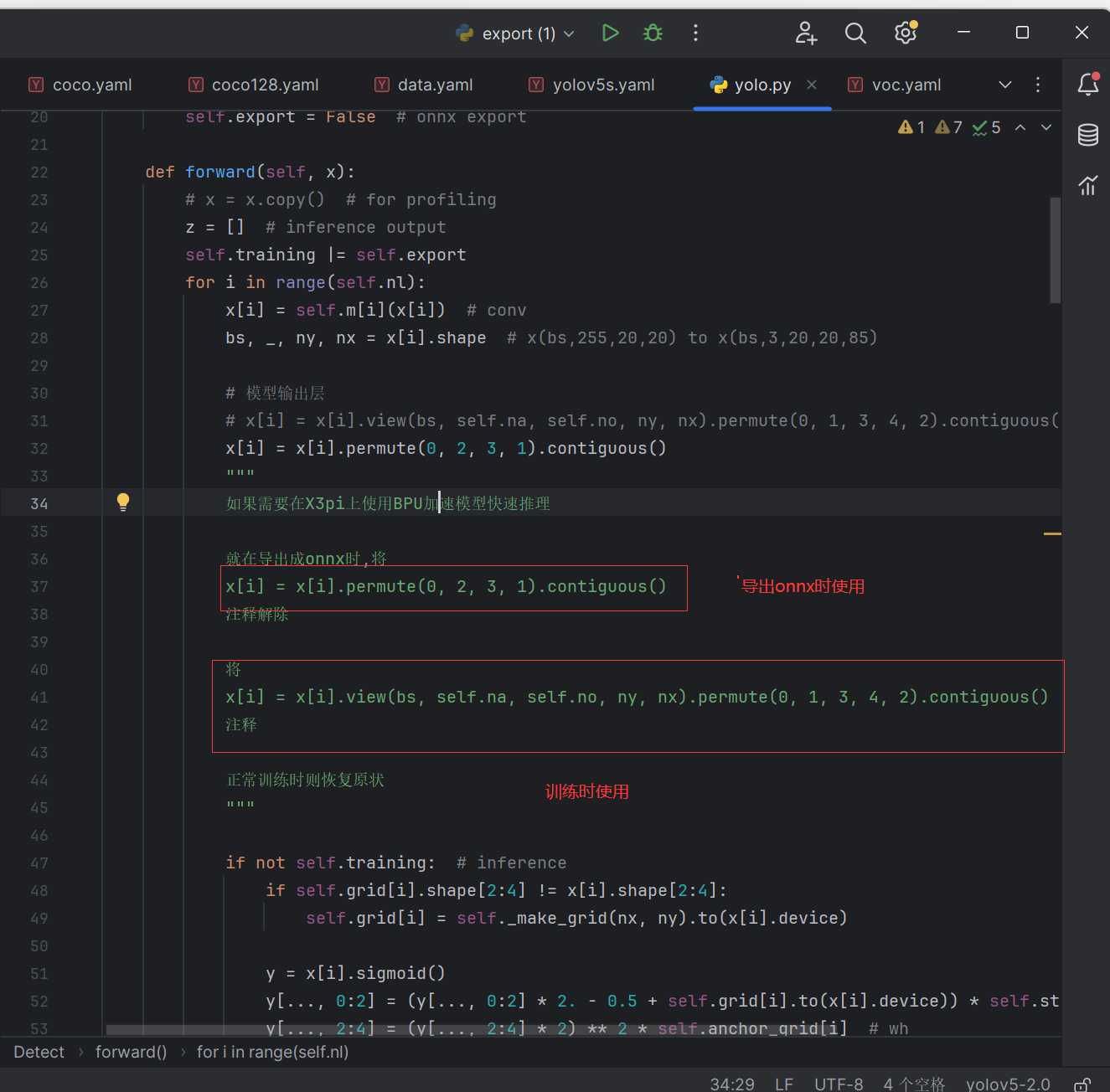
1.5.1为旭日派的BPU加速特殊处理
根据地平线官方文档说明为了更好地适配后处理代码
在使用export.py导出onnx模型时需要对yolo.py做特殊修改
去除了每个输出分支尾部从4维到5维的reshape(即不将channel从255拆分成3x85), 然后将layout从NHWC转换成NCHW再输出。
以下左图为修改前的模型某一输出节点的可视化图,右图则为修改后的对应输出节点可视化图。
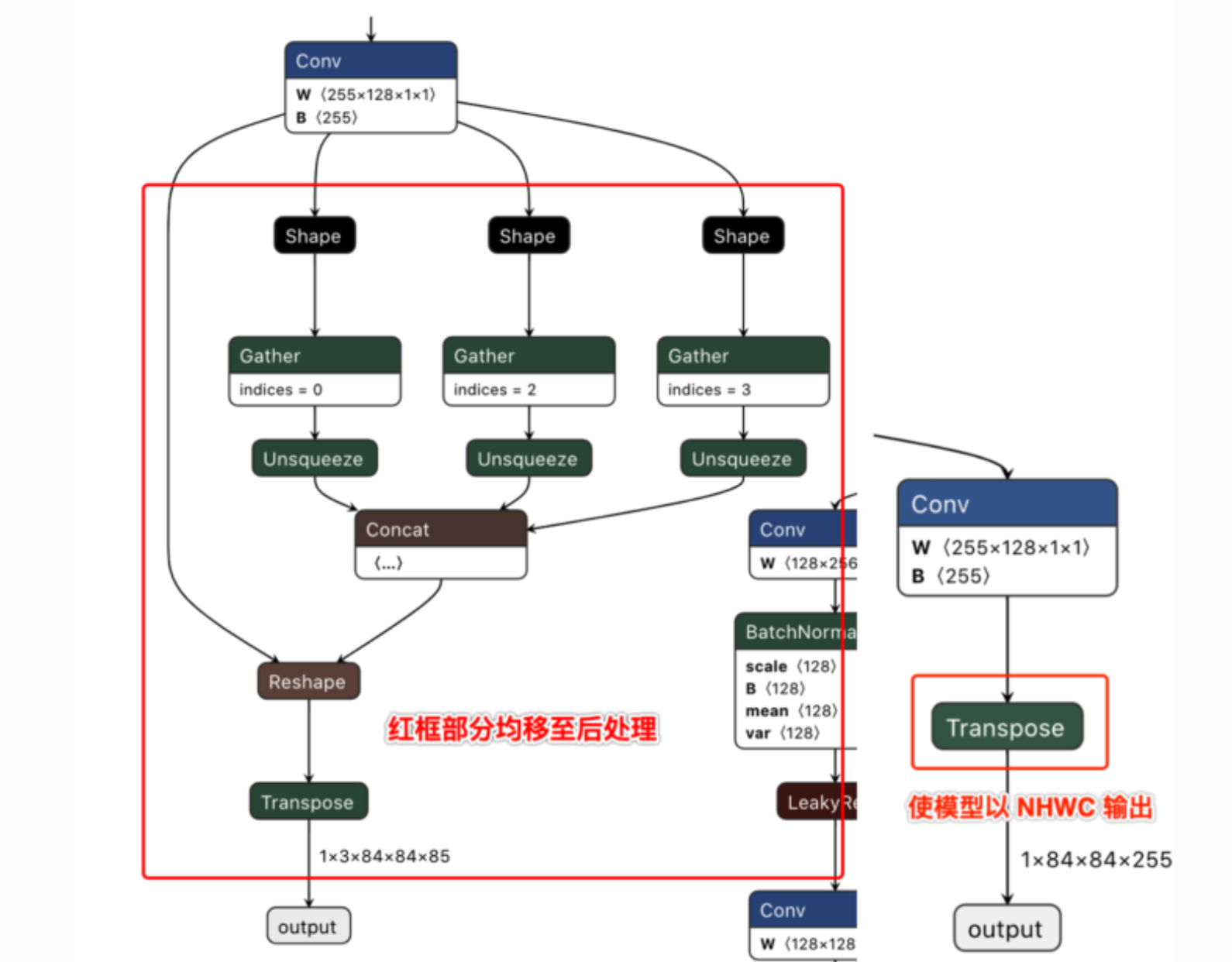
注意训练时和导出onnx模型时,此文件的不同
注意训练时和导出onnx模型时,此文件的不同
注意训练时和导出onnx模型时,此文件的不同
1.5.2修改export.py文件
在使用export.py脚本时,请注意:
- 由于地平线AI工具链支持的ONNX opset版本为 10 和 11, 请将
torch.onnx.export的opset_version参数根据您要使用的版本进行修改。 - 将
torch.onnx.export部分的默认输入名称参数由'images'改为'data',与模型转换示例包的YOLOv5s示例脚本保持一致。 - 将
parser.add_argument部分中默认的数据输入尺寸640x640改为模型转换示例包YOLOv5s示例中的672x672。
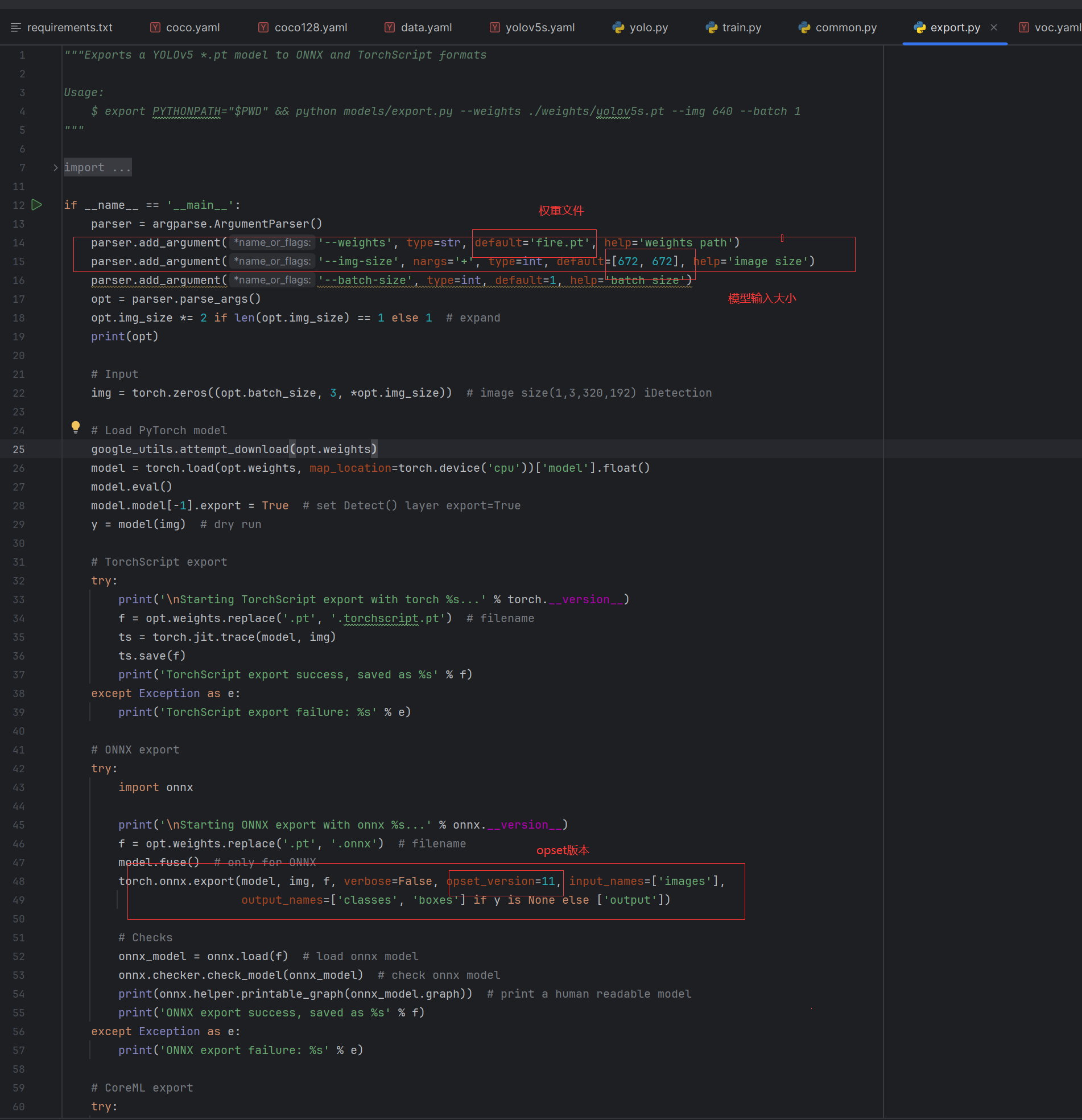
执行后就得到onnx文件了
2.转模型
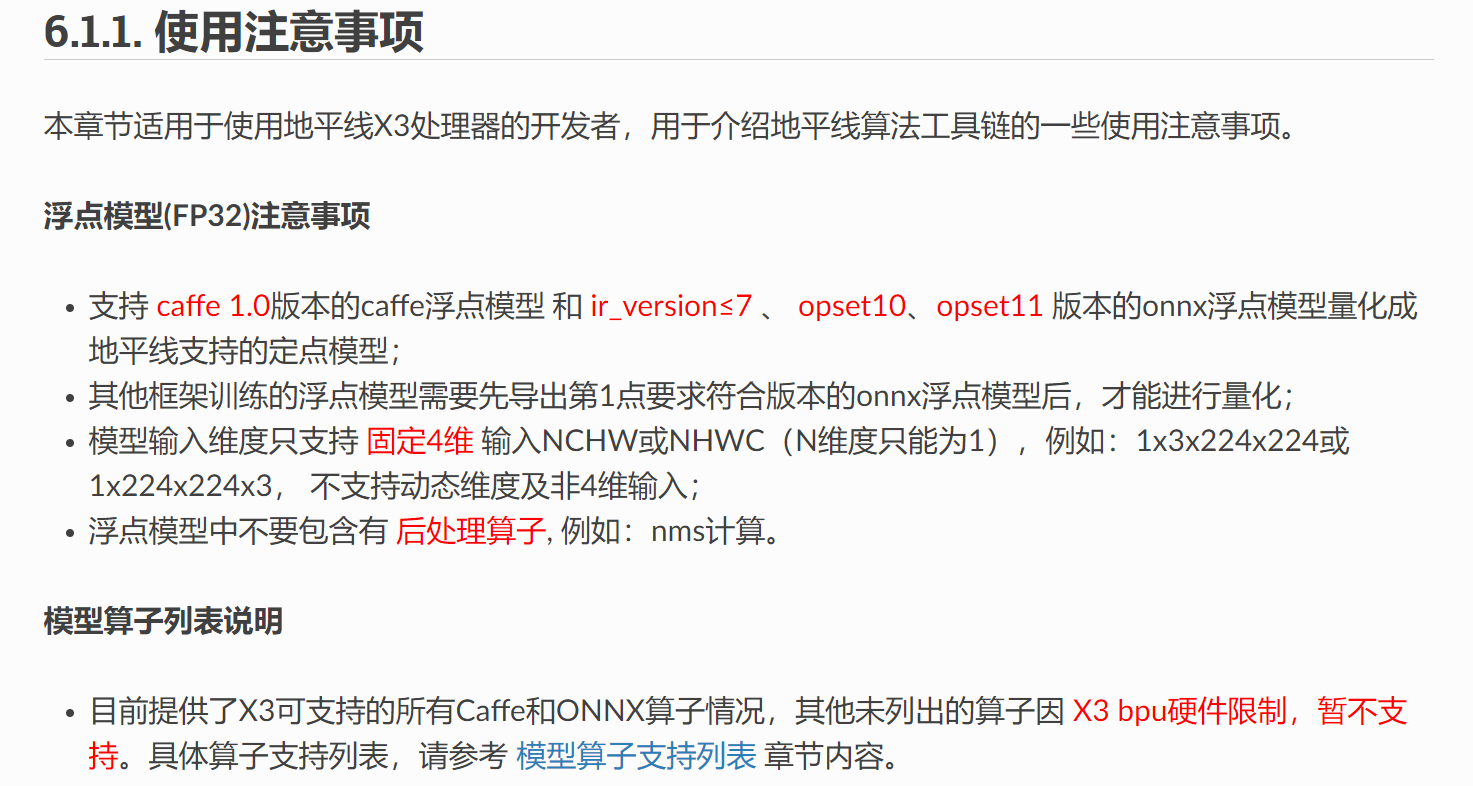
转模型需要在linux环境或者docker容器内进行,推荐使用ubuntu虚拟机进行,需要有anaconda+py3.6环境
2.1环境配置
2.1.1获得yolov5-2.0转模型demo
wget -c ftp://xj3ftp@vrftp.horizon.ai/ai_toolchain/ai_toolchain.tar.gz --ftp-password=xj3ftp@123$%wget -c ftp://xj3ftp@vrftp.horizon.ai/model_convert_sample/yolov5s_v2.0.tar.gz --ftp-password=xj3ftp@123$%
若需更多公版模型转换示例,可执行命令: wget -c
ftp://xj3ftp@vrftp.horizon.ai/model_convert_sample/horizon_model_convert_sample.tar.gz --ftp-password=xj3ftp@123$%
2.1.2创建模型转换环境
//horizon_bpu 为环境名,可自行设置conda create -n horizon_bpu python=3.6 -y
2.1.3进入模型转换环境:
// horizon_bpu 为上文创建python环境名, conda环境命令会根据不同的操作系统有所差异,以下两条命令请选择其中能进入conda模型转换环境的命令来使用source activate horizon_bpu 或 conda activate horizon_bpu
2.1.4解压模型转换环境和示例模型安装包并进行相关依赖的安装
tar -xzvf yolov5s_v2.0.tar.gztar -xzvf ai_toolchain.tar.gzpip install ai_toolchain/h* -i https://mirrors.aliyun.com/pypi/simplepip install pycocotools -i https://mirrors.aliyun.com/pypi/simple
2.2转换模型
2.2.1验证模型
修改01_check.sh
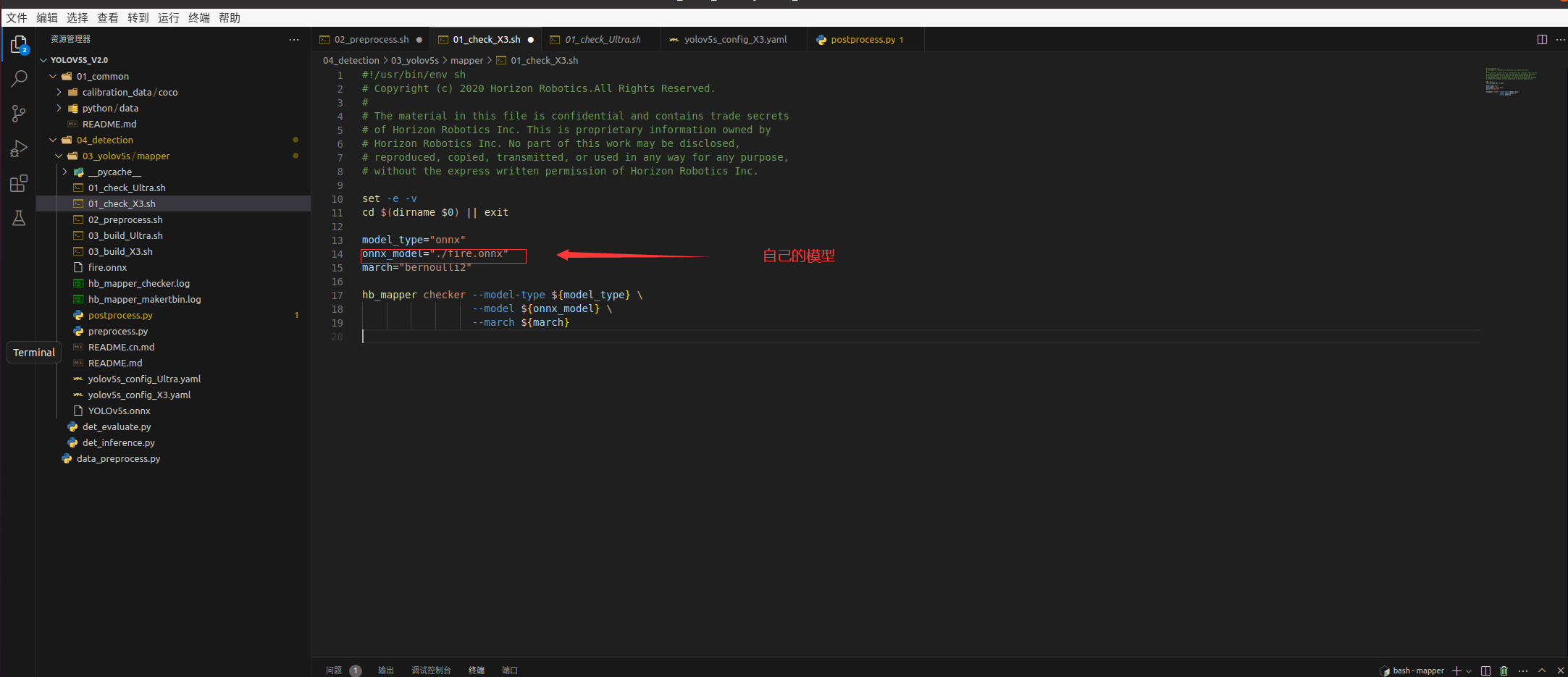
运行
./01_check.sh
终端输出这些就说明你的onnx是正常的可以运行在旭日派X3上的
2.2.2校准模型
因为BPU是INT8计算,所以注定会有精度损失。而且这些误差也是可以传递的,所以到后面精度是越来越低的。如果网络深度过高,也会导致整体精度的下降。
参考了地平线社区一个佬的yolov3文章这里
1. 在01_common创建一个存放图像文件夹
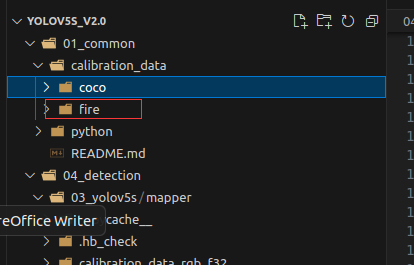
执行 bash 02_preprocess.sh
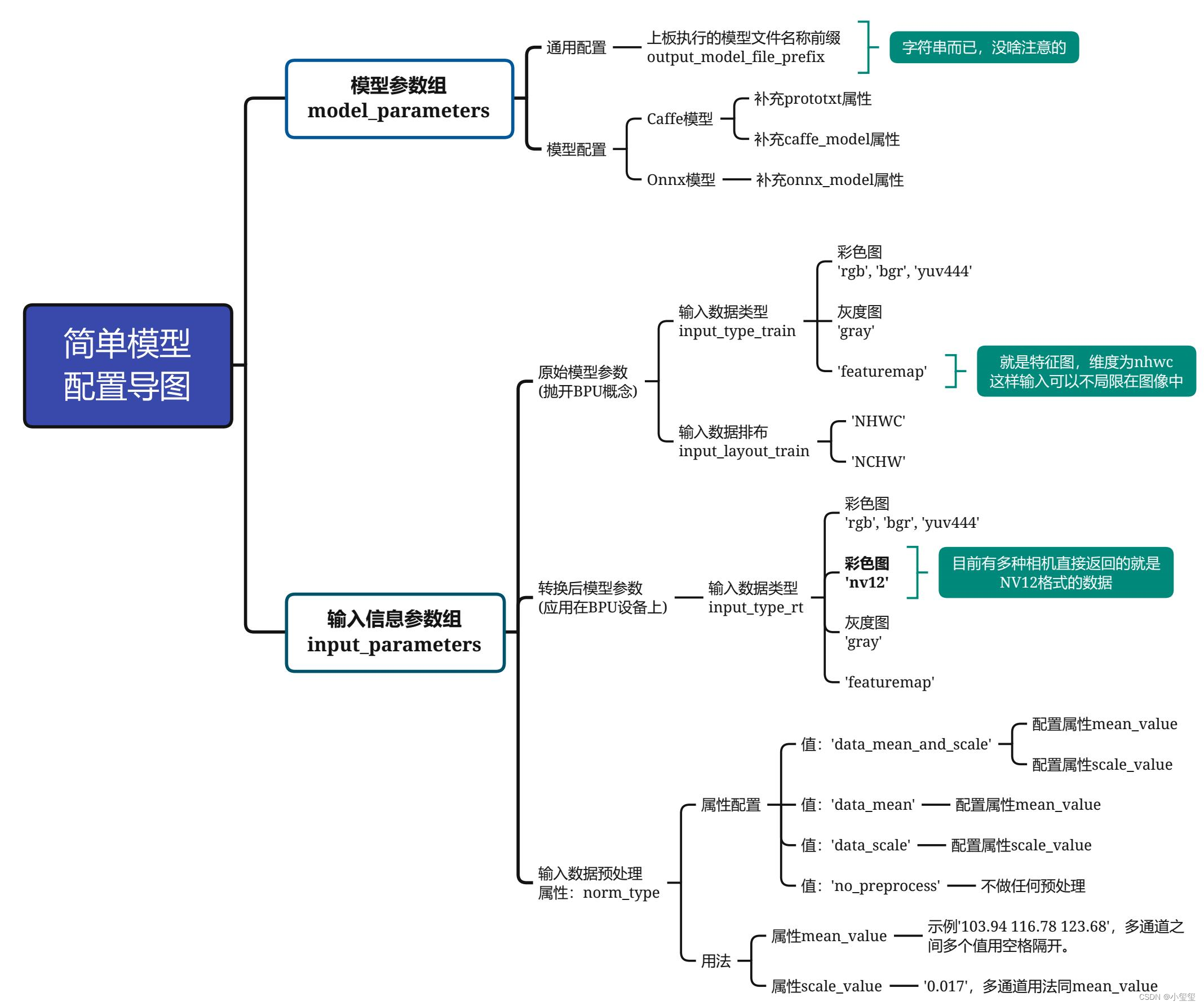
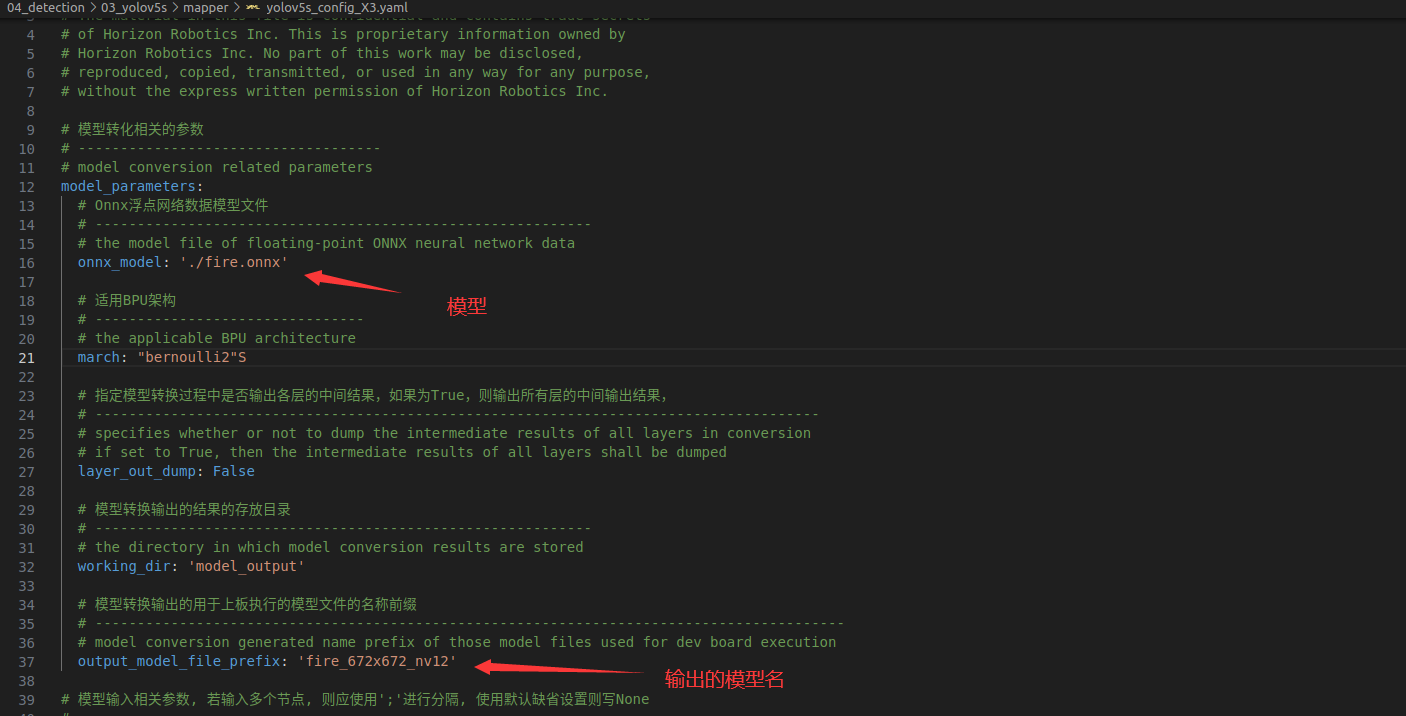
2.2.3转换配置yolov5s_config_X3.yaml
借用大佬的yolov3的思维导图
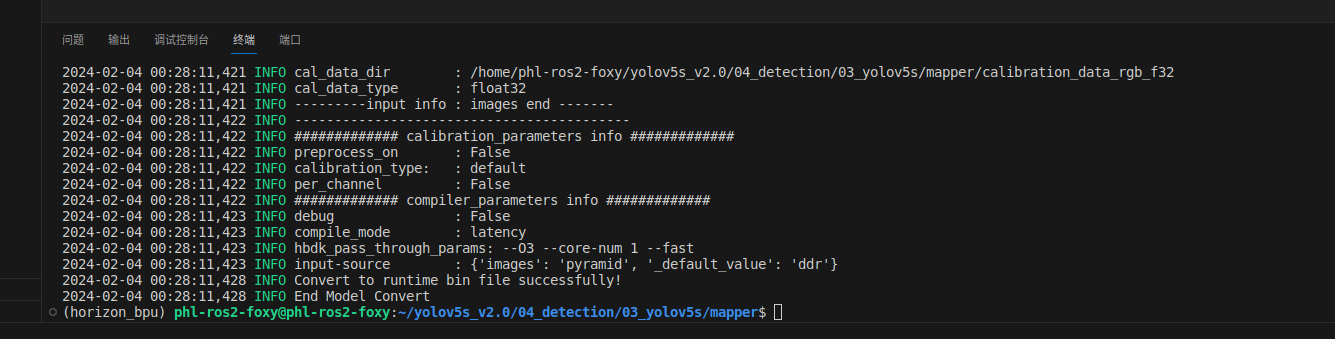
执行03_build.sh
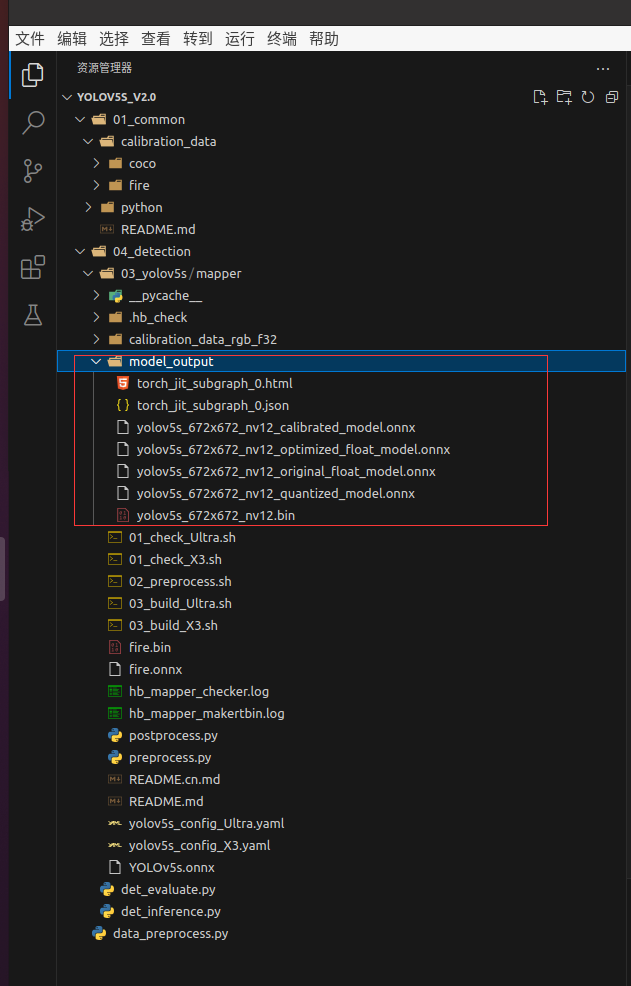
转换成功,位于model_output文件夹
3.部署
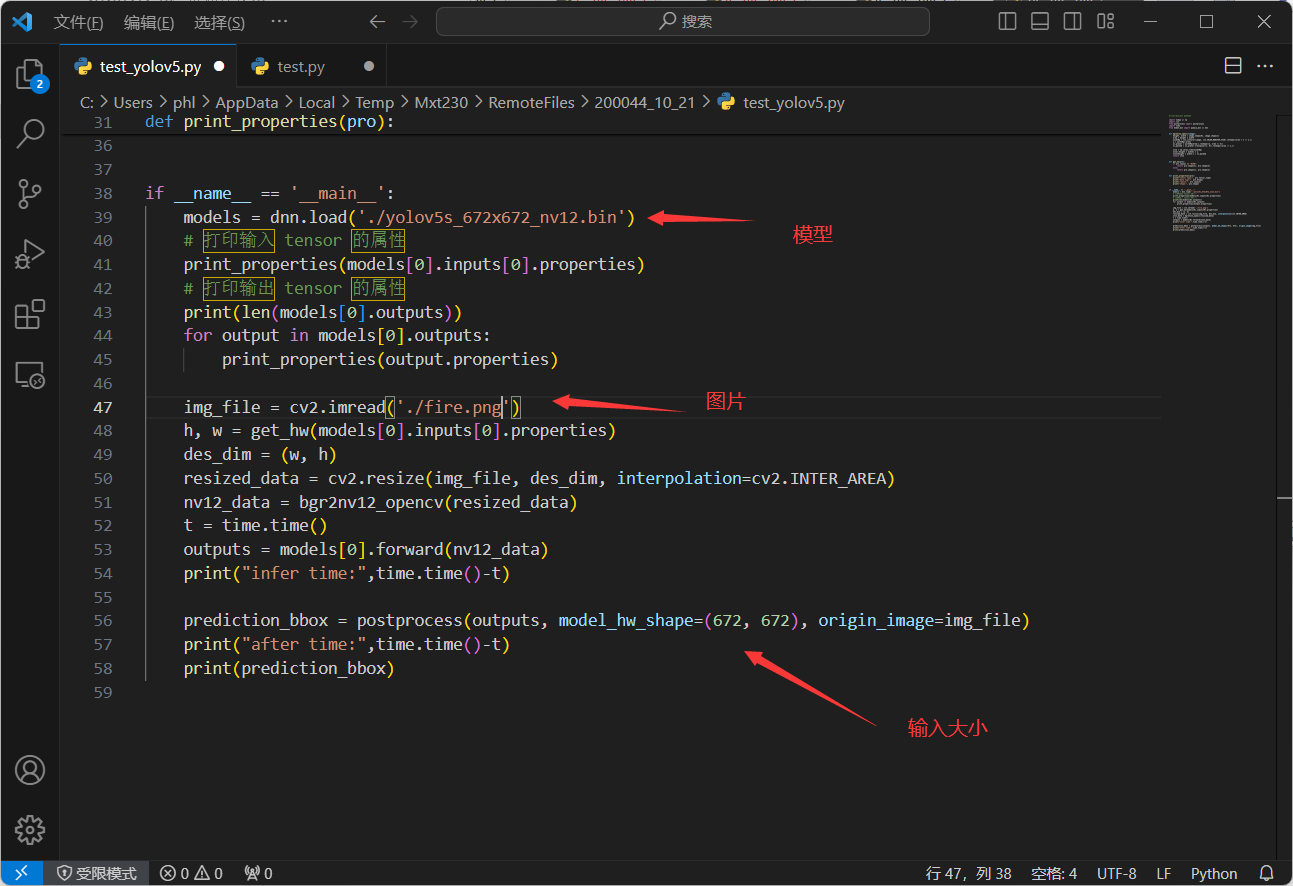
3.1修改test_yolov5.py
3.2postprocess.py
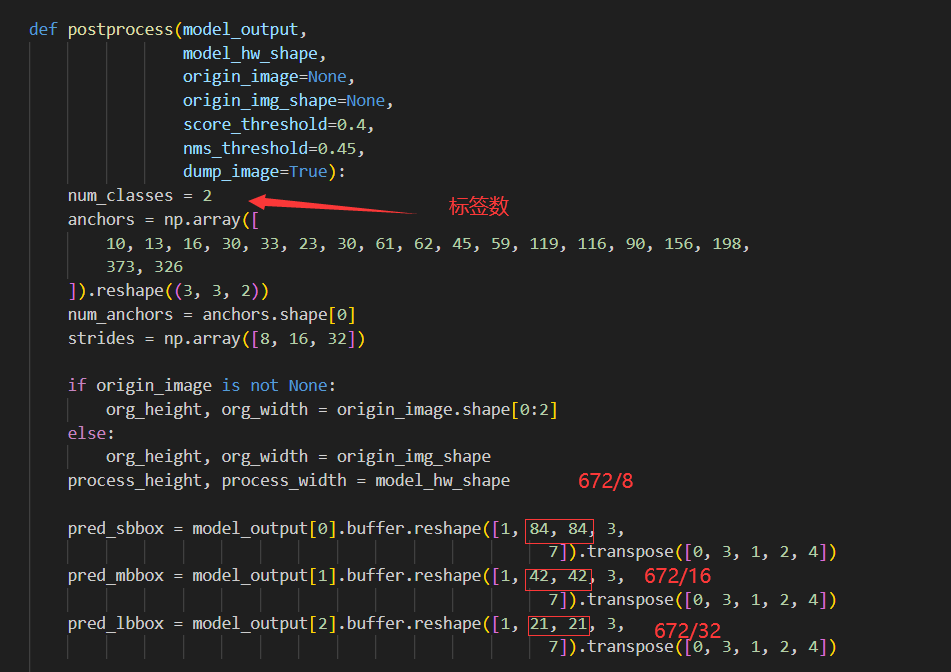
reshape的第2,3个参数,就是你模型尺寸分别除以8,16,32;第5个参数要改成刚才的num_classes+5(图中没有标出来)
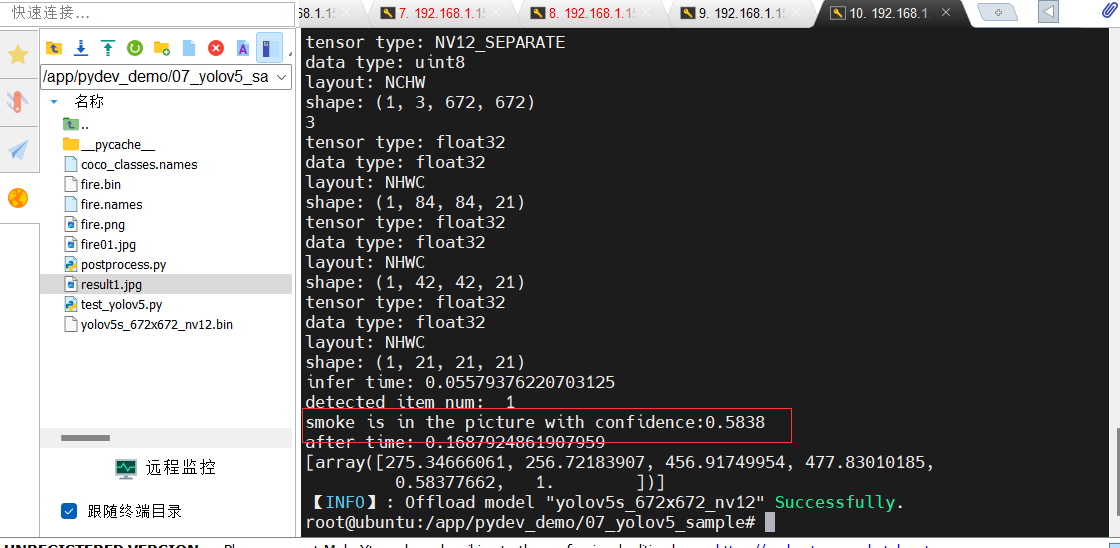
将图片fire01.jpg输入推理

结果

这篇关于一文教你地平线旭日派X3部署yolov5从训练-->转模型-->部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







