本文主要是介绍Adaptive NMS: Refining Pedestrian Detection in a Crowd,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这两年不少人在做NMS的优化工作。NMS是检测的后处理工作,在RCNN系列算法中,会从一张图片中找出很多个候选框(可能包含物体的矩形边框),NMS就是去除冗余矩形框的过程。具体流程如下:
对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空。
我们发现这个流程中阈值Nt很重要, 以前的检测工作中Nt是一个固定值, 这个不是很合理, 因为实际上存在一些物体的gt矩形框重叠(稠密物体场景), 这样NMS中很可能会把正确的框剔除掉。 那么我们会想:把这个Nt增大不就好了, 可数据集中稀疏场景下,较大的阈值会放掉一些False positive, 这样也不是我们想要的结果。 自然地, 我们想要的是这个阈值自适应的改变:稠密场景下增大, 稀疏场景下减小。
ICCV17 soft NMS的工作:
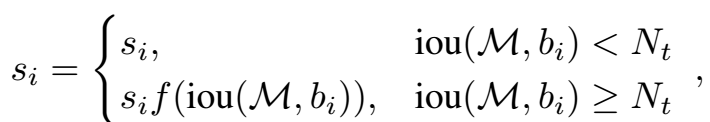
根据iou来改变检测的分数, 小于阈值时, 分数不变, 大于阈值时, 减小对应的分数。 这里的改进就是减少分数而不是完全置零。 f的具体形式可以是:
![]()
本文继续优化soft nms, 先估计场景的稠密程度(在RPN上的一个子网络):
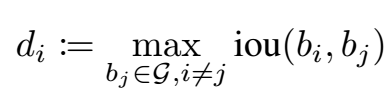
再设置对应阈值, 根据阈值计算分数:

其实感觉变动不是很大, 但是网络不一定好调试不来。 具体网络细节没有太大兴趣了解。
小结:
a. 检测的整个流程中各个环节都有可以提升的空间, 同理其他任务也是如此, 分析这些环节中存在那些不够完善的点, 想办法改进;
b. 不用担心一定要做出多大变动才能叫创新, 科研本来就是一点点的探索, 一点改进如果是扎实的, 那么它就有自己的价值。
这篇关于Adaptive NMS: Refining Pedestrian Detection in a Crowd的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








