crowd专题

HDU 4456 Crowd (cdq分治)
大意就是给出一个矩阵 初始每个位置上的值都为0 然后有两种操作 一种是更改某个位置上的值 另一个是求某个位置附近曼哈顿距离不大于K的所有位置的值的总和 网络上众多题解都是 二维树状数组 但是这题也被认为是cdq分治的基础题 下面提供两种基于cdq分治的解法 解法一: 将所有点绕原点左旋45° 然后新的坐标也很好计算 x'

152 - Tree's a Crowd
题目:152 - Tree's a Crowd 题目大意:找两颗树之间最近的距离,判断有多少的距离在0 - 10 之间; 解题思路:遍历,两两比较,注意要判断距离是否小于10 , 小于才加加。 #include<stdio.h>#include<algorithm>#include<math.h>#include<string.h>using namespace std;c
UVA 152 Tree's a Crowd (简单计算)
本来以为有高明的剪枝,结果……所以暴力就行 #include <stdio.h>#include <math.h>#include <string.h>#include <stdlib.h>#define sqr(x) ((x)*(x))typedef struct _Point {double x, y, z;}Point;int cmp(const void *_a,
hdu 4456 Crowd(二维树状数组)
题目链接:hdu 4456 Crowd 题目大意:给定N,然后M次操作 1 x y z:在x,y的位置加z2 x y z:询问与x,y曼哈顿距离小于z的点值和。 解题思路:将矩阵旋转45度,然后询问就等于是询问一个矩形,可以用容斥定理搞,维护用二维树状数组,但是空间开 不下,直接用离散化,将有用到的点处理出来。 #include <cstdio>#include <cstrin
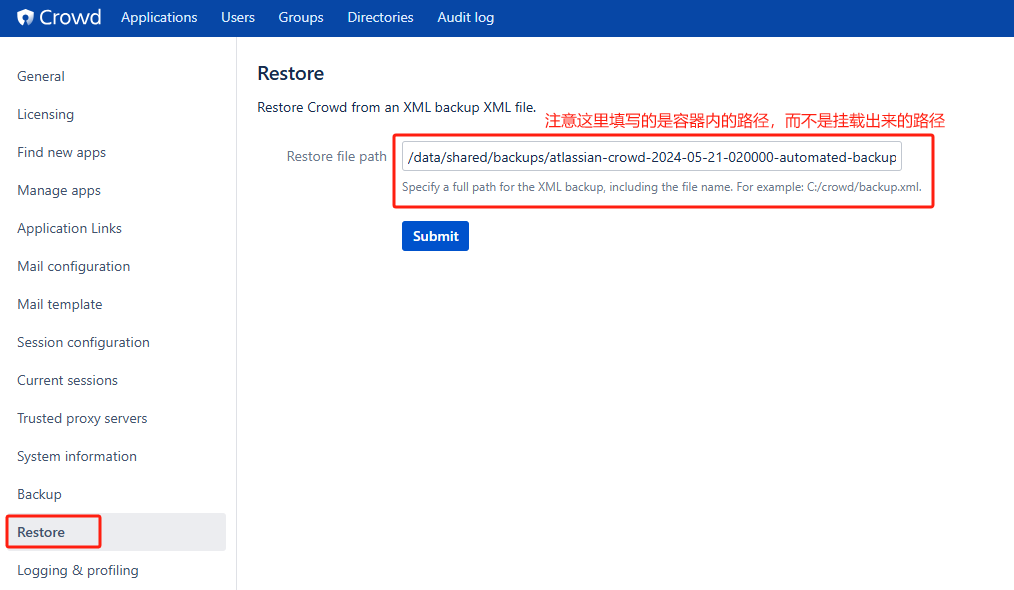
开源工具专题-04 Atlassian Crowd部署备份及迁移
开源工具专题-04 Atlassian Crowd部署备份及迁移 注: 本教程由羞涩梦整理同步发布,本人技术分享站点:blog.hukanfa.com转发本文请备注原文链接,本文内容整理日期:2024-05-29csdn 博客名称:五维空间-影子,欢迎关注 1 安装部署 1.1 制作镜像 注:官方镜像也是可以用的,但这里需要做些定制操作所以干脆自行制作镜像 操作如下 前置环境准备 #


Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction
本博文是对郑宇老师团队所提出的STResNet网络的一个略微扩充说明。本人自己在看完这篇论文的时候,感觉就一个字‘懵’。你说不懂吧,好像又明白点,你说懂吧又感觉有好多细节还是不清楚。好在该论文开放了源代码。经过对源代码的一番剖析,总算是弄懂之前不明白的一些细节。不过该源码是基于Keras实现的,由于本人之前一直使用Tensorflow,所以又对其利用tf进行了重构,代码整体上看起也来更加简洁,

Switching Convolutional Neural Network for Crowd Counting(CVPR2017)——论文笔记
Abstract 本篇论文主要做了以下三点: 端到端的switch-CNN来预测人群密度;Switch-CNN将人群照片的片段送入到独立的CNN回归网络来得到最小的估计错误和提高密度局部利用人群密度的变化率;我们在三个通用数据集里测试网络的性能。 3 Our Approach 在这篇论文中,我们提出了一个选择CNN结构的网络,通过网络将一张图片分成各个片段(patch
Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning-笔记
通过Active Learning(AL)算法,找到最小的需要标注的数据进行训练,来标记未标记的数据。 AL必须满需下边的需求才能作为crowd-sourced database的默认的最优策略: Generality:算法必须能够应用到任意的分类和标记任务。因为crowd-sourced systems应用广泛。Black-box treatment of the classife

Bootstrap-Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning
论文Scaling Up Crowd-Sourcing to Very Large Datasets A Case for Active Learning对bootstrap做了介绍。 原书(B. Efron and R. J. Tibshirani. An Introduction to the Bootstrap. Chapman & Hall, 1993.)

ranker-Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning
论文Scaling Up Crowd-Sourcing to Very Large Datasets A Case for Active Learning提出两种AL算法。 首先找到分类器θ对未标注数据的不确定程度。然后让crowd对这些数据进行标定。下边介绍两种不确定性方法。 下边的u是未标记数据,但是是指未标注数据的每一个,而不是整体。 一:Uncertainty Algorithm

activate learning-Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning
Active Learning Notation 本文是介绍论文Scaling Up Crowd-Sourcing to Very Large Datasets A Case for Active Learning中的AL算法。 Active learning algorithm主要由:1.一个ranker R; 2. selection strategy S;3. budget allo

论文笔记-Learning from Synthetic Data for Crowd Counting in the Wild 人群计数新方法
Hello, 今天是论文阅读计划的第11天啦。 今天介绍的这篇论文是CVPR 2019的一篇论文,是关于在室外拥挤的人群中的人群计数问题。哈哈,这是我在看别人整理的CVPR论文合集的时候,发现了这篇论文,然后对这个任务有点好奇,所以就下载来看看学习下了。 附上别人整理资料: CVPR 2020 论文开源项目合集:https://github.com/amusi/CVPR2020-Code E
喜报!Stratifyd入选G2 Crowd“2021文本分析软件高成长者”象限
点击上方蓝字关注我们 全球领先的商业软件评测机构G2 Crowd发布了2021文本分析软件魔力象限报告,Stratifyd凭借优异的客户满意度跻身高成长者象限(High Performer in Text Analytics),其中Stratifyd增强智能数据分析平台更是获得了4.2星(满分5星)的好成绩,向市场充分证明了其在数据分析领域的高增长潜力。 G2 Crowd——软件行业的“大

Adaptive NMS: Refining Pedestrian Detection in a Crowd
这两年不少人在做NMS的优化工作。NMS是检测的后处理工作,在RCNN系列算法中,会从一张图片中找出很多个候选框(可能包含物体的矩形边框),NMS就是去除冗余矩形框的过程。具体流程如下: 对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B
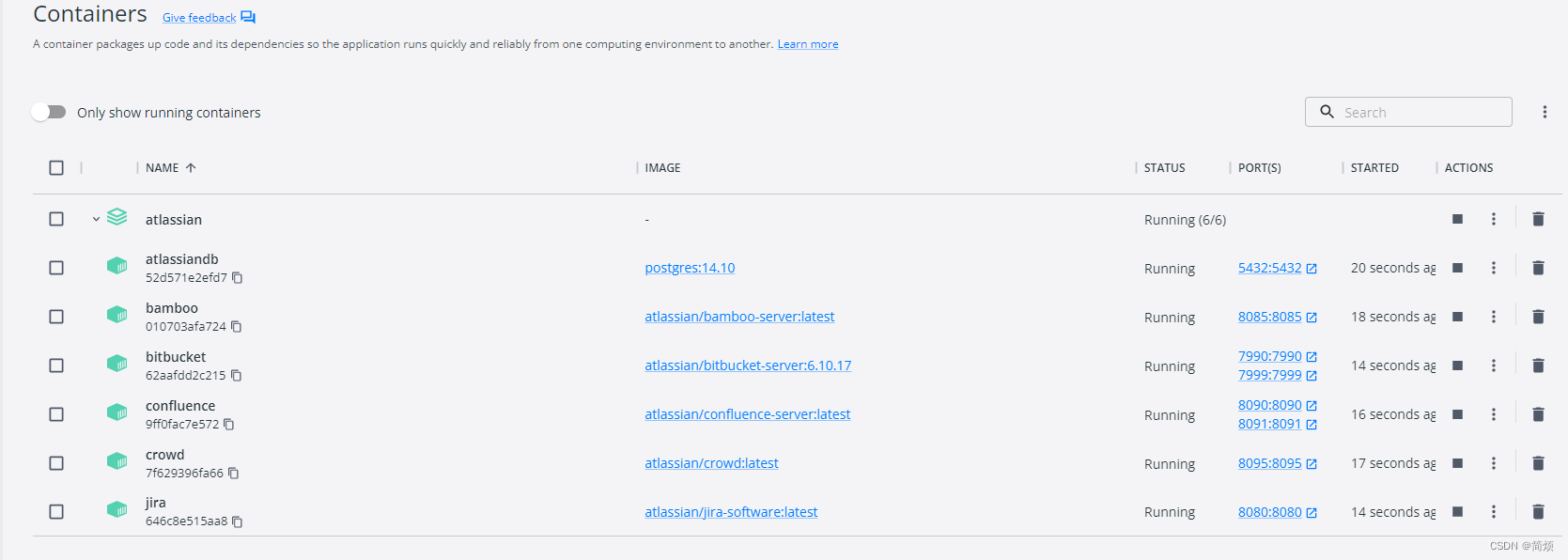
Docker部署Jira、Confluence、Bitbucket、Bamboo、Crowd,Atlassian全家桶
文章目录 省流:注意:解决方案: 1.docker-compose文件2.其他服务都正常启动,唯独Bitbucket不行。日志错误刚启动时候重启后查询分析原因再针对第一点排查看样子是安装的bitbucket和系统环境有冲突问题? 结论: 省流: bitbucket 只能安装6版本及其以下,原因会在下面说明,其他可按需安装。 注意: 还是不太推荐使用docker部署,官网也

Single-Image Crowd Counting via Multi-Column Convolutional Neural Network
================================================================ Single-Image Crowd Counting via Multi-Column Convolutional Neural Network 论文背景人群密度方法过去的发展历史早期方法基于轨迹聚类的方法基于特征回归的方法基于图像的方法 Multi-colu

Crowd Counting近期研究(附代码资源)
1.Semi-Supervised Crowd Counting with Contextual Modeling: Facilitating Holistic Understanding of Crowd Scenes paper:https://arxiv.org/abs/2310.10352 code:https://github.com/cha15yq/MRC-Crowd 摘要:

精读论文:Predicting Citywide Crowd Flows Using Deep Spatio-Temporal Residual Networks
Predicting Citywide Crowd Flows Using Deep Spatio-Temporal Residual Networks AAAI 2017 郑宇组的论文 文章首先介绍该问题的基本概念 ,接着描述系统的框架(本文跳过),然后介绍基于DNN的预测模型,最后进行实验验证模型结构与参数和与基线模型进行对比。 OUTLINE 人流量数据(crowd flows)
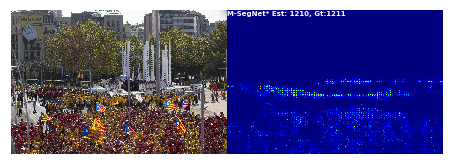
Variations-of-SFANet-for-Crowd-Counting可视化代码
前文对Variations-of-SFANet-for-Crowd-Counting做了一点基础梳理,链接如下:Variations-of-SFANet-for-Crowd-Counting记录-CSDN博客 本次对其中两个可视化代码进行梳理 1.Visualization_ShanghaiTech.ipynb 不太习惯用jupyter notebook, 这里改成了python代码测试,下
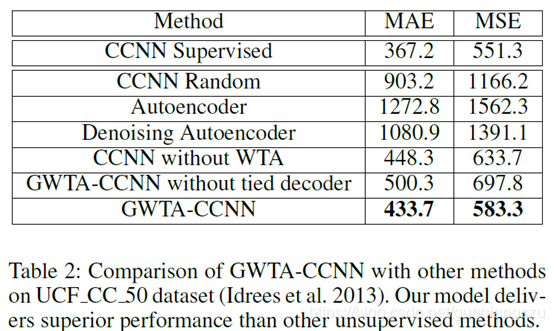
论文解读《Almost Unsupervised Learning for Dense Crowd Counting》AAAI2019
Almost Unsupervised Learning for Dense Crowd Counting Deepak Babu Sam, Neeraj N Sajjan, Himanshu Maurya, R. Venkatesh Babu AAAI2019 摘要: We present an unsupervised learning method for dense crowd c
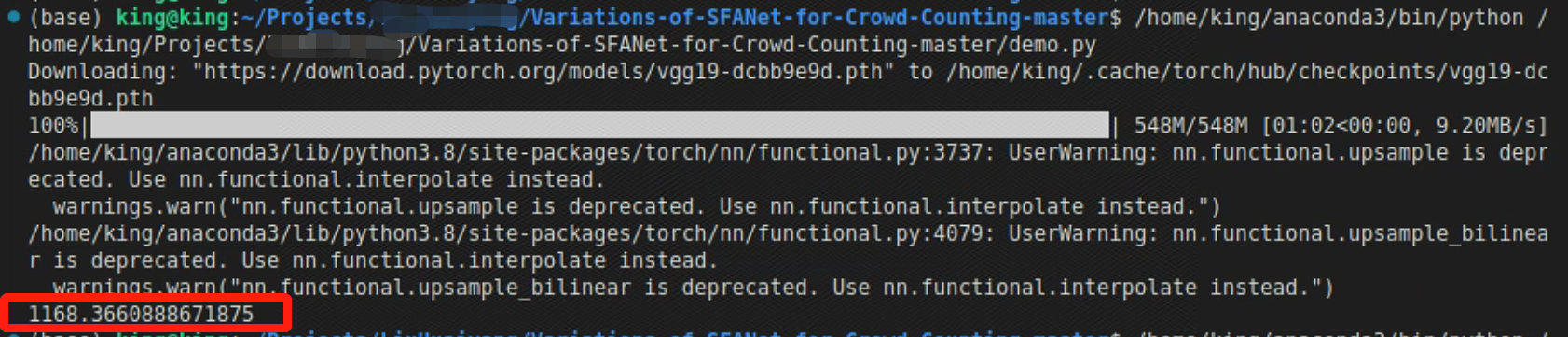
Variations-of-SFANet-for-Crowd-Counting记录
论文:Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting 论文链接:https://arxiv.org/abs/2003.05586 源码链接:GitHub - Pongpisit-Thanasutives/Variations-of-
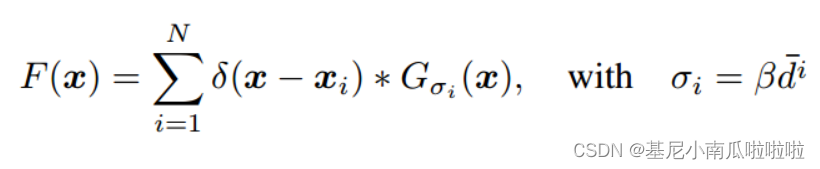
人群计数(Crowd Counting)相关内容
引用自知乎链接:人群计数(Crowd counting)从入门到深入 CSDN链接:人群计数:Single-Image Crowd Counting via Multi-Column Convolutional Neural Network(CVPR2016) 人群计数的研究意义 人群计数,又叫人群密度估计,直白的讲就是一种通过计算机计算或估计图像中人数的技术。通过对人群聚集的分析,可以帮助城
jira+confluence+bitbucket+bamboo+crowd+crucible+fisheye(2023年生产环境最新版)安装部署
截止2023年5月整个atlassian都在持续更新版本各版本如下: jira software 当前最新版为:9.8.1 confluence 当前最新版为:8.2.3 bitbucket 当前最新版为:8.10.1 bamboo 当前最新版为:9.2.1 crowd 当前最新版为:5.1.2 fisheye 当前最新版为:4.8.12 crucible 当前最新版为:4.8.1