本文主要是介绍【论文阅读笔记】Make-A-Character: High Quality Text-to-3D Character Generation within Minutes,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【论文阅读笔记】分钟级别的高质量文本到3D角色生成
- Abstract
- Introduction
- Method
- LL/VM解析人脸面部属性并生成
- 根据密集地标重建face/head形状
- 几何生成
- 纹理生成
- 纹理提取
- 漫反射反照率(Diffusion Albedo)估计
- 纹理矫正和补全
- 头发生成(牛了)
- 资产匹配
- 实验
- 未来工作
| paper | https://arxiv.org/abs/2312.15430 |
|---|---|
| Demo | https://huggingface.co/spaces/Human3DAIGC/Make-A-Character |
| Code | https://github.com/Human3DAIGC/Make-A-Character |
| Project | https://human3daigc.github.io/MACH/ |
前文介绍过DreamFace,MACH支持生成头发、眼睛、眼镜、舌头、牙齿、衣服等资产,且可以和现有CG管线相结合。可以直接用于需要数字人的场景,无需二次编辑
multiView
Abstract
- 定制和富有表现力的3D角色的需求越来越大,但传统的计算机图形学手动创建创建是昂贵的。
- 提出了一个名为 Make-A-Character (Mach) 的用户友好的框架,以从文本描述中创建类似生命的 3D 化身。
- 该框架利用大型语言模型的强大功能进行文本意图理解和中间图像生成,然后是一系列面向人类的视觉感知和 3D 生成模块。
- 两分钟左右生成、可以和现有CG管道集成、可支持动画驱动
Introduction

目标:无缝地将文本描述符转换为生动的视觉化身,为用户提供一种简单的方法来创建与其共鸣的自定义化身
下定义:3D数字人的属性应包含
- 可控:定制详细的面部特征,包括面部的形状、眼睛、虹膜的颜色、发型和颜色、眉毛的类型、嘴巴和鼻子,以及皱纹和雀斑的添加
- 真实:基于收集的真实人体扫描数据集生成的。此外,它们的头发是以细丝而非网格的形式构建的,基于PBR(物理渲染)技术渲染
- 完整:我们创建的每个字符都是一个完整的模型,包括眼睛、舌头、牙齿、全身和服装。这种整体方法确保我们的字符准备在各种情况下立即使用,而无需额外的建模。
- 可动画:角色是骨骼绑定的,支持标准动画
- 工业兼容:利用显式的 3D 表示,确保与游戏和电影行业中使用的标准 CG 管道无缝集成
Method
选择包含了面部和身体的完整表示的 MetaHuman作为显式3Dmesh,因为它包含了面部和身体的完整表示,并提供了更细微的表情动画能力,主要是因为它的高级面部装备系统,它为虚拟角色生动的动态性能提供了强大的支持。
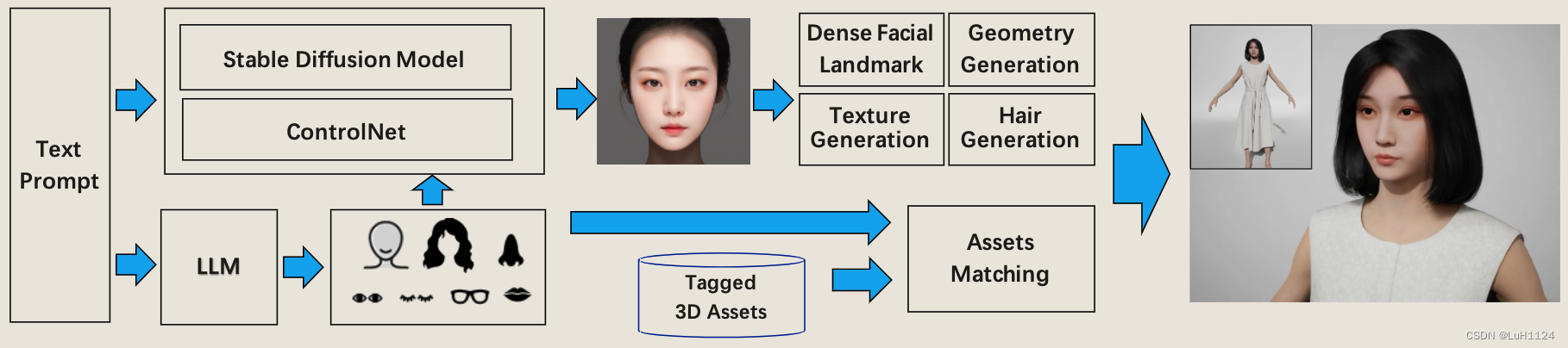
Mach的体系结构上图所示。
- 给定一个文本提示,利用大型语言模型(LLM)进行语义理解,可以提取各种面部属性,如面部形状、眼睛形状、嘴巴形状、发型和颜色、眼镜类型。
- 然后将其中一些语义属性映射到相应的视觉线索,作为使用SD和ControlNet生成参考肖像图像的精细指导。由于我们的姿态控制,参考肖像保证具有中性表情的正面,这给头部几何和纹理生成带来了很大的便利。
- 我们在头部网格和三平面图之间建立转换机制,因此我们可以直接优化2D地图,而不是求助于提供灵活顶点级控制的3DMM方法。
- 利用可微分渲染和光照技术根据参考图像提取和细化漫反射纹理,头发生成模块通过提供链级头发合成来增强整体表现力。
- 对于服装、眼镜、睫毛和虹膜等其他配件,将它们从标记的3D资产库中与提取的语义属性进行匹配,最后将它们组装成一个完整的3D图形。
整个过程的持续时间在 2 分钟以内。
LL/VM解析人脸面部属性并生成
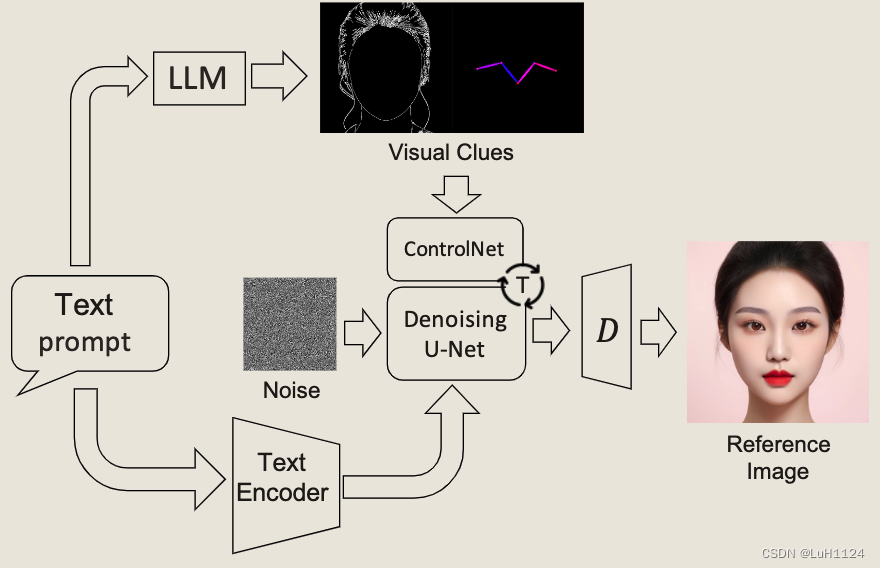
- 给定提示词,通过Qwen-14B分解为详细的面部属性词
- ControlNet集成了Openpose和canny映射,以确保面部特征的合理分布,最终获得与文本提示密切相关的参考图像
根据密集地标重建face/head形状
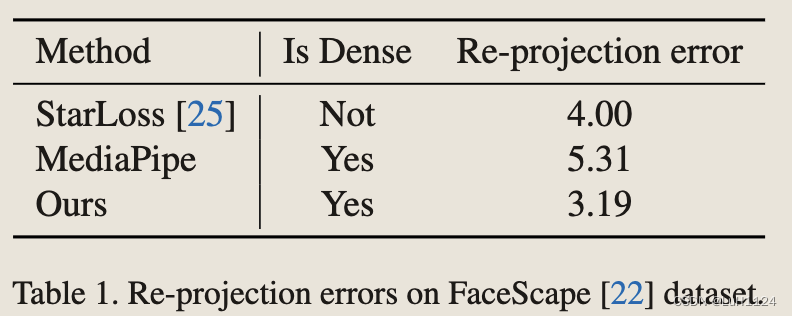
- 受益于微软的3D face reconstruction with dense landmarks文章(从密集地标重建人头),由于密集的面部关键点不能手动注释,采用合成图像作为训练数据。
- 建立了一个的多视角捕捉设备和处理管线。

- 得益于该设备,采集了超过1,000 real human scans,并得到了统一拓扑的几何和面部纹理
- 使用了各种数字资产,包括 23 个头发、45 个衣服、8 个帽子和 13 个嘴部,以创建完整的人类头部模型。为了生成不同的面部表情,使用了 52 个混合形状的经典集合,并从多个角度渲染每个模型。
- 地标检测训练一个stacked hourglass networks 回归面部标志点热图(应该是2D回归)

几何生成
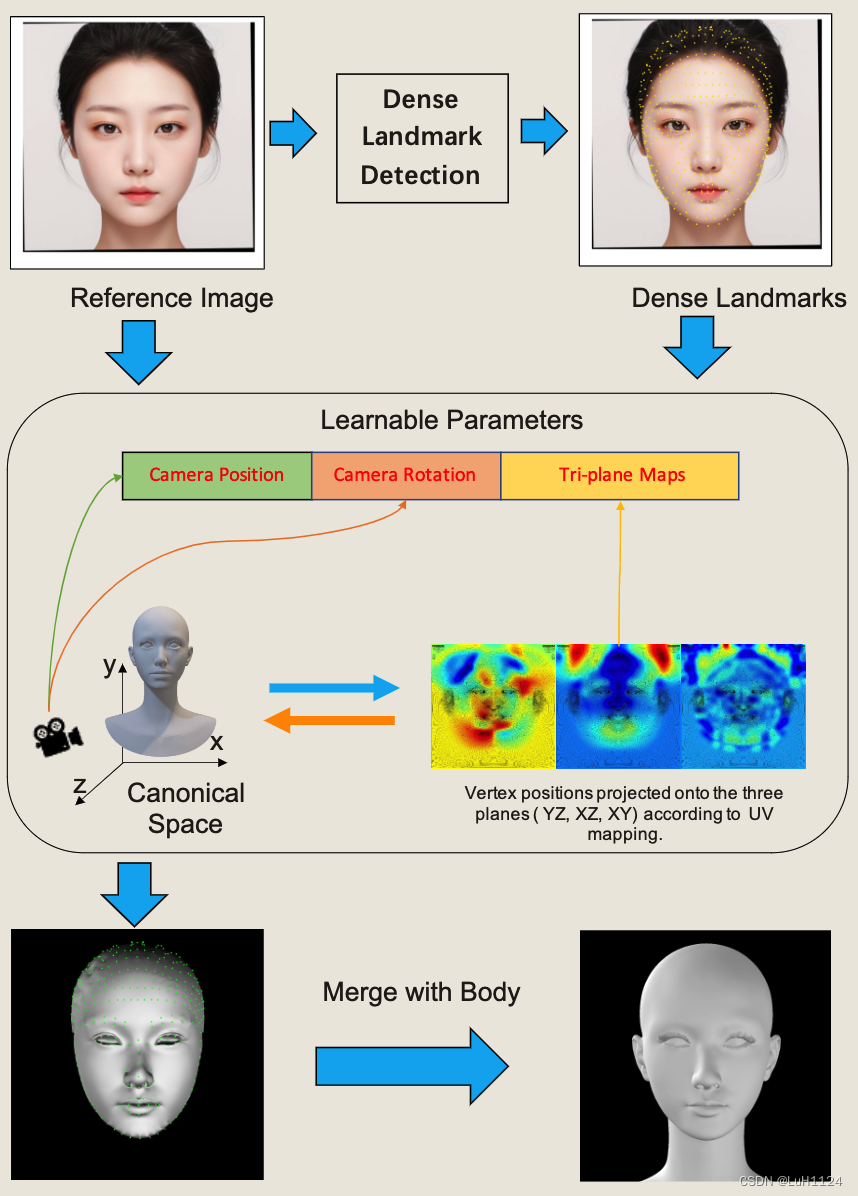
给定参考人像图像和相应的密集面部地标,在这些地标的指导下重建头部几何形状。
在3D网格和2D映射之间建立转换机制,根据每个顶点的UV坐标将每个顶点的位置映射到三个正交平面(即Y-Z、X-Z和X-Y平面)来实现(不同的基底base可能会遇到信息损失,或几何缺失),用3通道图像来表示3D网格,称为三平面(我理解是旋转人头到三个平面,然后通过UV映射转为position map,)。
在三平面和图像标注点层面迭代优化人头模型的生成(我理解是迭代优化,以得到精确的人头模型)

分别是2D关键点loss,三个平面的对衬性loss和总变差loss(Total Variation Loss,衡量了图像中相邻像素之间的差异,帮助减少图像中的噪点和增强图像的边缘和细节。总变差损失通常被用于图像去噪、图像超分辨率和图像重建等任务中)。
纹理生成
纹理提取
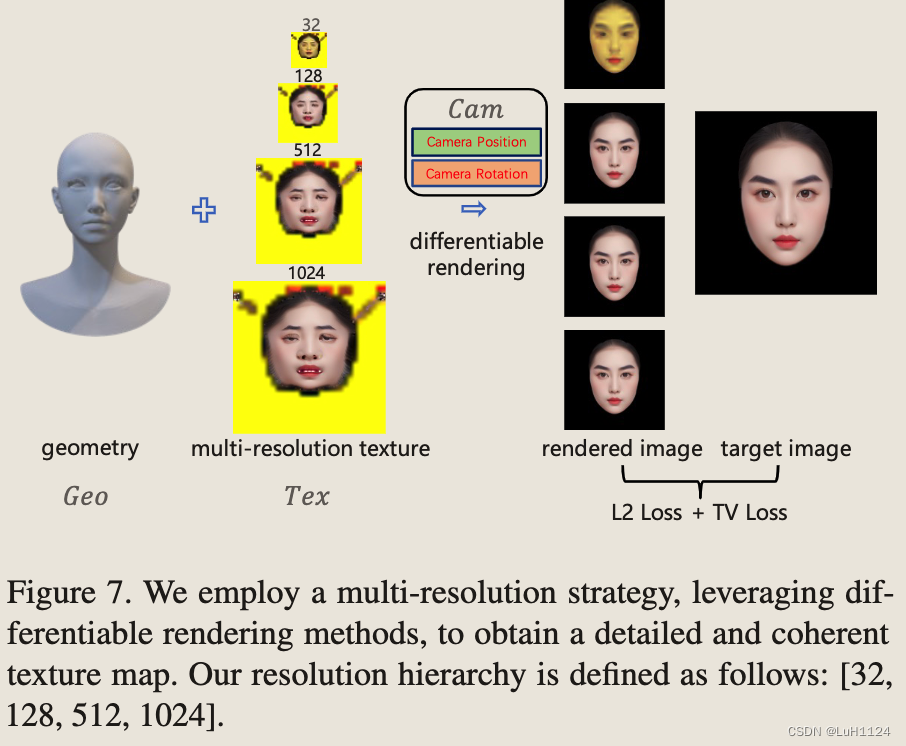
得到几何后,基于differential render得到所需的纹理图像。由于像素位置和UV坐标之间并不总是一一对应的,采用了一种多分辨率的纹理生成方法,通过逐步生成从低分辨率到高分辨率的纹理来生成纹理。
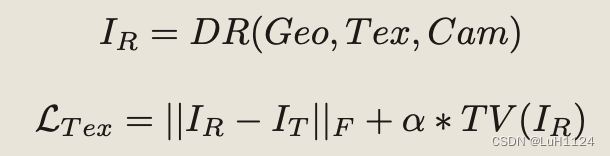
漫反射反照率(Diffusion Albedo)估计
从原图中直接提取的纹理包含光照影响,理想的纹理图应该是去掉光照的,从而支持在渲染软件中进行灯光设置和新的渲染。
- 引入了一种神经去照明方法,从纹理图像中去除不需要的照明,得到渲染的漫反射反照率。值得注意的是,我们的去照明算法适用于纹理图像,而不是肖像图像。这是一个有意的选择,因为纹理图像不受遮挡的影响,并且在肖像的不同姿势和表情之间保持一致,使得数据采集和算法学习更容易处理。(可以理解为残缺纹理的补全和去光照任务)
- 我们在均匀光照下捕获了193个人的面孔(包括100名女性和93名男性,年龄在20-60岁之间)。通过重建几何图形,我们获得了未折叠的高分辨率漫反射反照率,如图 8 (a) 所示。
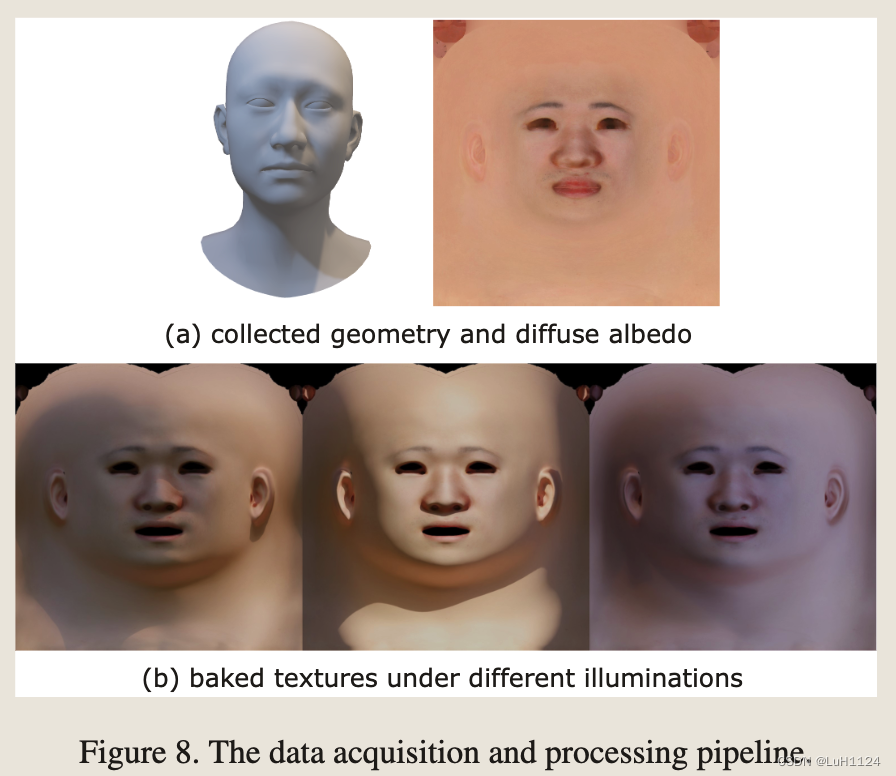
- 训练数据生成。通过将灯光烘烤到地面真实漫反射反照率来合成不同光照下的纹理。为了涵盖广泛的自然照明条件,我们为每个地面实况数据烘烤 100 个高动态范围 (HDR) 灯(包括室内/室外、白天/夜场景)。为了提高数据的多样性和避免过拟合,根据个体类型学角度(ITA)对地面真实漫反射反照率的肤色进行了增强。图 8 (b) 说明了不同照明下的烘烤纹理。
- 去光照网络。将纹理delight问题表述为图像到图像的转换问题。用从粗到细的pix2pixHD网络,将合成的照明纹理作为输入,生成视觉上吸引人的高分辨率漫反射反照率。损失函数定义为GAN损失和VGG特征匹配损失的加权组合。我们使用默认参数以 1024 的分辨率训练网络。
纹理矫正和补全
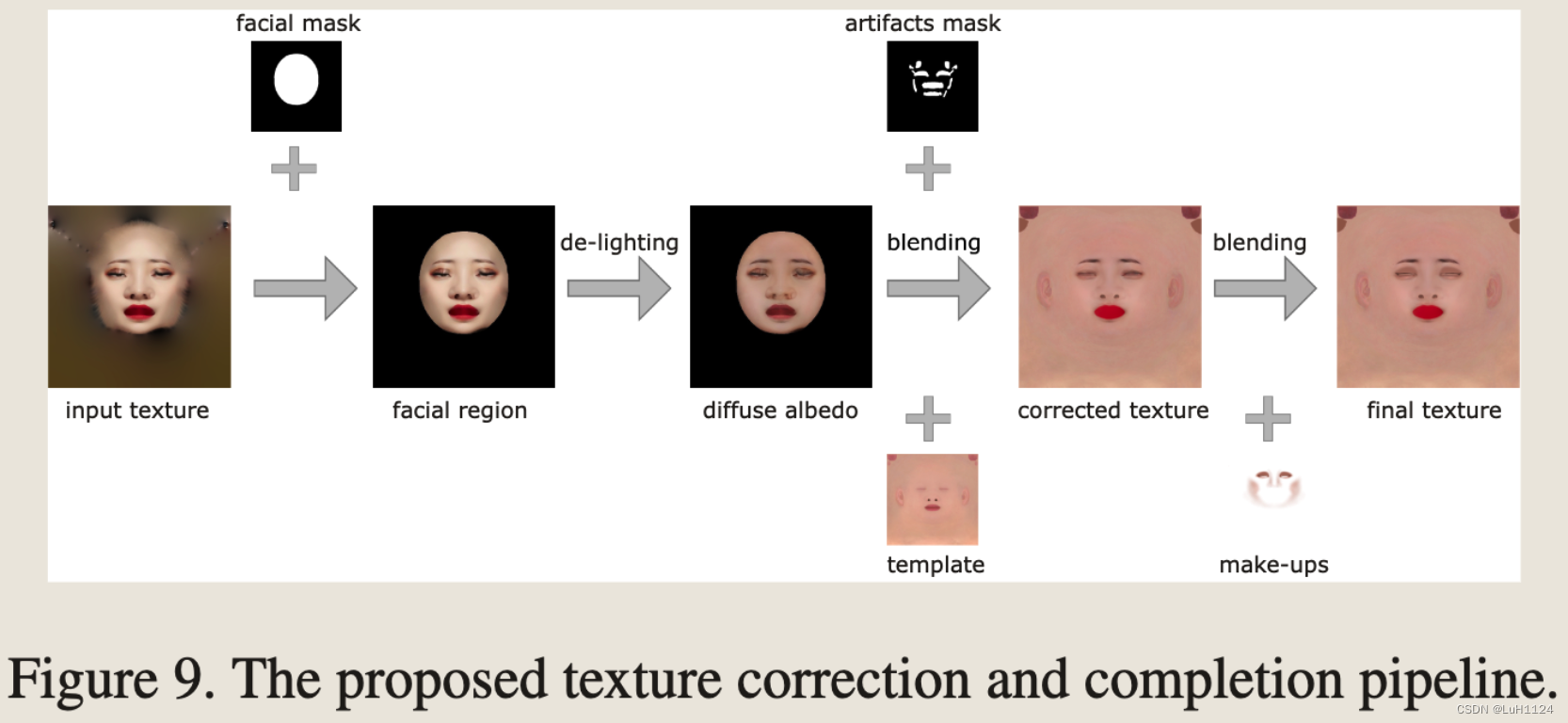
在去光照后,生成的漫反射反照率可能在眼睛、嘴巴和鼻部区域附近仍然有伪影。这是单正面肖像图像的固有局限性的结果,它只提供有关人脸的有限纹理信息。
当映射到 3D 人脸几何时,不完美的漫反射反照率会在眼睛、嘴巴和鼻部区域附近引入未对齐的语义特征,从而导致审美上令人不快的结果。
- 利用现成的人脸解析算法来提取这些容易出错区域的掩码,使用泊松方法仔细扩展并与模板漫反射反照率合并。
- 将嘴巴和眉毛的颜色从肖像图像中转移,以保持面部特征。
- 最后,将面部区域与模板漫反射反照率混合,得到耳朵和颈部的纹理。
- 在眼睛和脸颊周围添加了化妆,以改善美学。图 9 展示了所提出的纹理校正和完成管道。
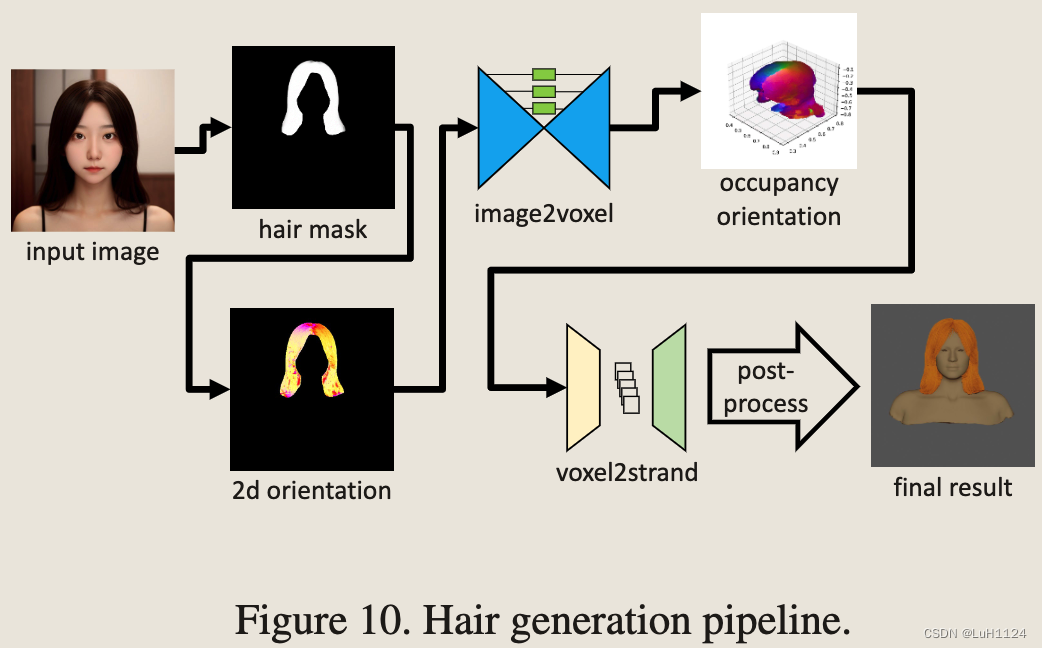
头发生成(牛了)
将头发渲染为单独的strands,而不是mesh。使用SD生成各式各样发型的2D图像,然后基于3D strand-based从2D图像重建头发的3D表示。
合并了 SOTA 研究,例如 NeuralHDHair(期待后期解读),并使用 USC-HairSalon数据集训练我们的模型。
- 基于输入的 2D 图像估计 3D 空间中头发的占用和方向场。
- 利用第一阶段生成的离散体素级数据,生成数万个头发的几何描述。完整的发型生成过程还包括人脸对齐、头发面具分割和二维方向识别等预处理操作。
- 此外,应用后处理操作来增强初始生成的头发结果,包括去除不合理的链,将头发拟合到目标头部网格,并执行几何变形以实现高质量的重建结果。整个管道如图 10 所示。
- 由于时间消耗,选择离线生成不同的发型资产,构建发型库。这些生成的头发资产与现有的元人头发一起被标记为发型类型、长度和crimp程度等描述性属性。此属性标记支持有效的匹配过程。

资产匹配
为了构建一个完全实现的 3D 字符,我们必须将生成的头部、头发、身体、服装和一些配件集成在一起。每个预先生成的资产都标有文本注释,无论是手动还是通过注释算法。为了选择与输入提示匹配最合适的资产,我们使用CLIP的文本编码器来计算输入提示的特征与资产标签之间的余弦相似度,然后选择相似度最高的资产。
实验

通过facial rig control system在虚幻引擎中实现驱动
未来工作
当前的版本侧重于生成视觉上吸引人的亚洲种族 3D 化身,因为我们选择的 SD 模型主要在亚洲面部图像上进行训练。未来,我们将尝试扩展对不同种族和风格的支持。值得注意的是,我们的去照明数据集仅由干净的人脸纹理组成,生成的化身可能会削弱涂鸦或贴纸等非自然面部模式。目前,我们的服装和身体部位是基于文本相似性预先制作和匹配的。然而,我们积极致力于开发文本提示驱动的布料、表情和运动生成技术。
这篇关于【论文阅读笔记】Make-A-Character: High Quality Text-to-3D Character Generation within Minutes的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








