本文主要是介绍【亿级数据专题】「分布式消息引擎」 盘点本年度我们探索服务的HA高可用解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
盘点本年度我们探索服务的HA高可用解决方案
- 前言介绍
- HA高可用
- 高可用性评估
- 可用性是平均故障间隔时间
- HA技术架构的特性分析
- Master/Slave架构
- 主从复制模式
- 主从复制的特性分析
- 高可用案例
- RocketMQ的主从架构
- 责任划分
- 同步机制动态化
- RocketMQ高可用架构中有限状态机的转换
- 总结
- Master/Slave架构
- RocketMQ
注意:特此声明:本文首发在掘金:https://juejin.cn/post/7330521390510178367,未经允许,请勿进行侵权私自转载。
昔之善战者,先为不可胜,以待敌之可胜。不可胜在己,可胜在敌。故善战者,能为不可胜,不能使敌之必可胜。故曰:胜可知,而不可为。
前言介绍
根据专栏的前一篇文章的分析和介绍,有了容量保障的“三大法宝”作为基础,但随着消息引擎集群规模的持续扩大,一旦达到某个阈值,集群中机器发生故障的风险也会随之上升,这无疑会严重削弱消息的可靠性和系统的可用性。此外,采用多机房部署的集群模式也可能遭遇机房断网问题,进一步影响了消息系统的可用性。
为了有效应对这些问题,出现了基于多副本的高可用解决方案。这个方案能够动态识别机器故障、机房断网等潜在的灾难场景,并实现故障自动恢复。这一过程完全无需用户干预,从而显著增强了消息存储的可靠性,确保了整个集群的高可用性。
HA高可用
高可用性是分布式系统设计时必须着重考虑的核心特性。基于CAP原则(一致性、可用性和分区容错性无法在分布式系统中同时满足,且最多只能满足其中两个),业界已经提出了一些通用的高可用解决方案。这些方案旨在确保系统在面对各种故障和挑战时仍能保持稳定和可用,如下图所示:
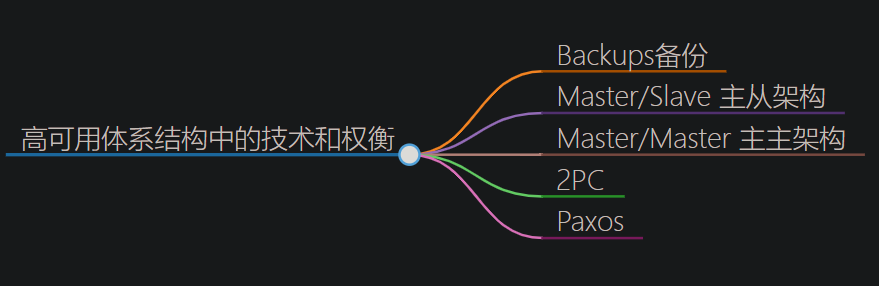
这些方案通过一系列机制和技术,如负载均衡、容错处理、数据冗余等来提高系统的可用性和容错能力。这些方案在实际应用中得到了广泛验证,并取得了显著的效果。
高可用性评估
高可用性评估是衡量一个信息系统提供持续服务能力的核心指标,它代表着在特定环境中系统或其某一能力在给定时间区间内能够正常工作的概率。
可用性是平均故障间隔时间
可用性是可用性是平均故障间隔时间(MTBF)除以平均故障间隔时间(MTBF)和平均故障修复时间(MTTR)之和所得的结果。这意味着,可用性越高,系统的服务能力和可靠性越强。

-
MTBF:平均故障间隔时间,是指设备或系统在正常运行过程中,相邻两次故障之间的平均时间。MTBF 值越大,表示设备的可靠性越高,故障发生的频率越低。通过分析 MTBF,可以了解设备的运行状况、寿命以及潜在的故障风险,从而为维护和改进提供依据。
-
MTTR:平均故障修复时间,是指设备或系统从发生故障到恢复正常运行所需的平均时间。MTTR 值越小,表示维修团队对故障的处理速度越快,系统的可用性越高。通过分析 MTTR,可以评估维护团队的工作效率,以及设备维修的难易程度,从而为优化维修流程和提高系统可用性提供参考。
Availability = MTBF / (MTBF + MTTR)
目前,我们通常使用"N个9"来描述系统的可用性。例如,99.9%的可用性被称为"3个9",这意味着系统在一年的不可用时间不超过8.76小时。而99.999%的可用性则被称为"5个9",这要求系统在一年的不可用时间必须控制在5.26分钟以内。如果一个系统没有故障自动恢复机制,那么它很难达到"5个9"的高可用性标准。
HA技术架构的特性分析
在分布式系统中,有多种通用的高可用解决方案,包括冷备、Master/Slave、Master/Master、两阶段提交以及基于Paxos算法的方案。这些方案在数据一致性、事务支持程度、数据延迟、系统吞吐量、数据丢失可能性以及故障自动恢复方式等方面各有特点。
借用了分布式架构官网的一个图片,针对于以上我们重点方向的HA技术架构的评估,它们的优劣势,如下图所示:
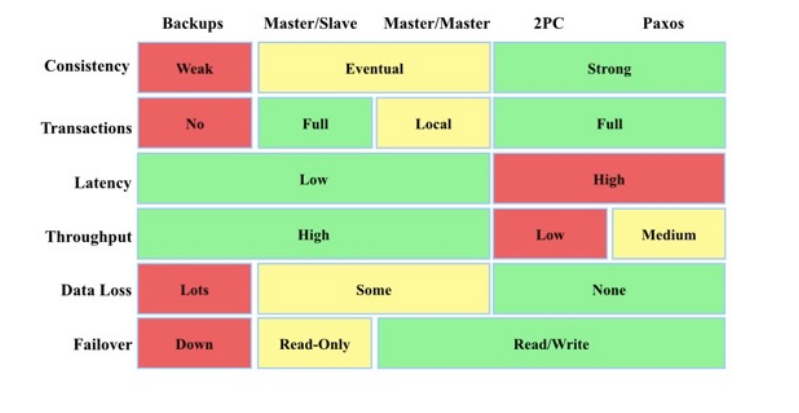
从图中可以明显看出,不同的高可用解决方案在各项指标上的表现各有千秋。基于CAP原则,设计一种能够同时达到所有指标最优的高可用方案是一项极具挑战性的任务。
Master/Slave架构
Master/Slave结构是分布式系统中的一种常见高可用解决方案。数据从Master节点复制到Slave节点,可以确保数据的最终一致性。
主从复制模式
主从复制根据同步方式的不同,主从复制可以分为两种类型:同步主从复制和异步主从复制。

-
异步复制模式:数据在Master节点写入成功后即可反馈给客户端,这降低了延迟并提高了系统的吞吐量。然而,这种模式下存在Master节点故障导致数据丢失的风险。
- 为了避免数据丢失,当Master节点发生故障时,Slave节点可以设置为只读模式,等待Master节点的恢复。但这会延长系统的故障恢复时间。
-
同步复制模式:增加数据写入的延迟并降低系统的吞吐量,但可以确保在机器故障时数据不会丢失。此外,由于数据的一致性得到了保证,系统的故障恢复时间也会降低。
主从复制的特性分析
以Master/Slave方案为例,它通常具备以下特性:
- 数据一致性:Master/Slave方案通常能够保证数据在主从节点之间的一致性,确保数据在多个节点上的副本之间保持同步。
- 事务支持程度:Master/Slave方案可以支持事务处理,保证数据的完整性和一致性。在主节点上进行事务操作,并将操作结果同步到从节点上,以保证数据的一致性。
- 数据延迟:Master/Slave方案中的数据延迟相对较低,因为主节点上的数据变更会实时同步到从节点上,从而减少数据不同步的问题。
- 系统吞吐量:Master/Slave方案可以通过读写分离来提高系统的吞吐量。读请求可以分发到从节点上,减轻主节点的负载,提高系统的整体性能。
- 数据丢失可能性:在Master/Slave方案中,从节点可以作为数据的备份节点,当主节点出现故障时,可以从从节点上恢复数据。因此,这种方案在一定程度上降低了数据丢失的可能性。
- 故障自动恢复方式:Master/Slave方案通常具备故障自动恢复功能。当主节点出现故障时,系统可以自动将一个从节点提升为新的主节点,继续提供服务,实现故障自动恢复。
高可用案例
RocketMQ高可用架构:RocketMQ 基于原有多机房部署的集群模式,利用分布式锁和通知机制,借助Controller(NameServer)组件,设计并实现了 Master/Slave 结构的高可用架构。

RocketMQ的高可用主从架构采用主从复制模式,将数据从一个主节点同步到多个从节点,以提高系统的可用性和可靠性。这种架构可以确保在主节点出现故障时,从节点可以接管主节点的职责,继续提供服务。
RocketMQ的主从架构
主节点负责接收数据并写入存储系统,同时将数据同步给多个从节点。当主节点出现故障时,系统会自动检测到故障并选择一个从节点提升为新的主节点,其他从节点仍然保持同步复制状态。这样可以在保证数据一致性的同时,提高系统的可用性和可扩展性。
责任划分
RocketMQ以Master/Slave 结构实现多机房对等部署,消息的写请求会命中 Master,然后通过同步或者异步方式复制到 Slave 上进行持久化存储;消息的读请求会优先命中 Master,当消息堆积导致磁盘压力大时,读请求转移至Slave。
同步机制动态化
从可用性计算公式中我们可以看到,要提高系统的可用性,需要在确保系统健壮性以延长平均无故障时间的同时,进一步增强系统的故障自动恢复能力,以缩短平均故障修复时间。
RocketMQ的高可用架构设计并实现了Controller组件,该组件能够按照单主状态、异步复制状态、半同步状态以及最终的同步复制状态的有限状态机进行转换。在最终的同步复制状态下,无论是Master还是Slave节点发生故障,其他节点都能在秒级时间内快速切换至单主状态,继续提供服务。
RocketMQ高可用架构中有限状态机的转换
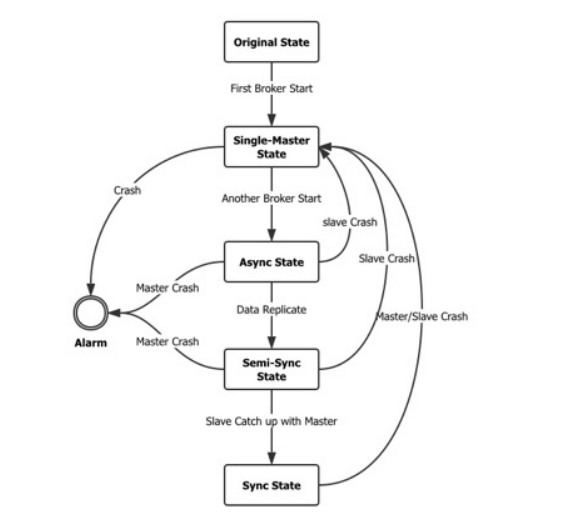
- 当第一个节点启动后,Controller(NameServer)将控制状态机切换至单主状态,并指示该节点以Master角色开始提供服务。
- 当第二个节点启动后,Controller(NameServer)将控制状态机切换至异步复制状态。在此状态下,Master会以异步方式向Slave复制数据。
- 当Slave的数据接近于Master时,Controller(NameServer)将控制状态机切换至半同步状态。在此状态下,对Master的写请求将被暂时挂起,直到Master以异步方式向Slave复制了所有差异的数据。
- 当半同步状态下Slave的数据与Master完全一致时,Controller将控制状态机切换至同步复制模式。在此模式下,Master会以同步方式向Slave复制数据。若在此状态下任一节点发生故障,其他节点能够在秒级内快速切换至单主状态,继续提供服务。
总结
Master/Slave架构
Master/Slave方案是一种在实际应用中广泛使用的高可用解决方案,它通过主从复制和读写分离等技术手段,实现了数据一致性、事务支持、数据延迟控制、系统吞吐量提升、数据安全保障以及故障自动恢复等功能。然而,在实际应用中,需要根据具体需求和场景来选择和设计适合的高可用方案,综合考虑各种指标和限制条件,以达到最优的效果。
- Slave是Master的备份,可以根据数据的重要程度设置Slave的个数。数据写请求命中Master,读请求可命中 Master 或者 Slave。
- 写请求命中Master之后,数据可通过同步或者异步的方式从Master复制到Slave上,其中同步复制模式需要保证Master和 Slave均写成功后才反馈给客户端成功;异步复制模式只需要保证Master写成功即可反馈给客户端成功。
RocketMQ
RocketMQ的高可用主从架构通过主从复制和故障转移机制,在充分考虑系统复杂性和消息引擎对CAP原则的适应后,RocketMQ的高可用架构设计采用了Master/Slave结构。这一结构不仅保证了低延迟、高吞吐量的消息服务,还通过主备同步复制方式,有效避免了故障发生时消息的丢失。在数据同步过程中,引入了一个递增的全局唯一SequenceID,以确保数据的一致性。
这篇关于【亿级数据专题】「分布式消息引擎」 盘点本年度我们探索服务的HA高可用解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





