亿级专题

【JVM】亿级流量调优(二)
亿级流量调优 指针压缩 -XX:-UseCompressedOops指针压缩技术只有64位机器才有。jdk6以后引入的技术,默认是开启的 关闭指针压缩的情况下 通过HSDB用Memory Viewer查看该对象在内存中的分配地址发现类型指针占8字节,0x3其实是数组的长度,前面用一行来存储类型指针 开启指针压缩的情况下 通过HSDB用Memory Viewer查看该对象在内存

sphinx搭建亿级搜索
sphinx搭建亿级搜索 最近在做一些模糊搜索,大家知道MySQL单表如果超过100万条记录,查询就会变慢,如果用like语句做模糊搜索,那么索引就完全用不上,这样一来一次搜索就要遍历全表,没个1秒是出不来结果的,多的时候十几秒也是正常的。如果是MyISAM引擎,写表的时候是表级锁,立刻就跪了。一台小型机做100个并发,每个并发建立一个数据库长连接,机器负载很快就上去了。之前还做过

赋能AI未来,景联文科技推出高质量亿级教育题库、多轮对话以及心理大模型数据
当前,大模型正如雨后春笋般不断涌现,不断推动着大模型产业的应用实践进入加速发展的新阶段。 景联文科技是AI数据服务公司,提供海量优质大模型数据集,涵盖文本、图像、视频、音频等多类型数据,致力于为不同训练阶段的算法精准匹配高质量数据资源。 拥有高质量大模型文本数据集,其中包括教育题库、多轮对话以及心理大模型数据等。 教育题库 产品:K12教育题库1800万;大学题库1.

从100PV到1亿级PV网站架构演变(1)
一个网站就像一个人,存在一个从小到大的过程。养一个网站和养一个人一样,不同时期需要不同的方法,不同的方法下有共同的原则。本文结合我自已14年网站人的经历记录一些架构演变中的体会。 1:积累是必不可少的 架构师不是一天练成的。 1999年,我作了一个个人主页,在学校内的虚拟空间,参加了一次主页大赛,几个DREAMWEAVER的页面,几个TABLE

【Mongodb-01】Mongodb亿级数据性能测试和压测
mongodb数据性能测试 一,mongodb数据性能测试1,mongodb数据库创建和索引设置2,线程池+批量方式插入数据3,一千万数据性能测试4,两千万数据性能测试5,五千万数据性能测试6,一亿条数据性能测试7,压测8,总结 一,mongodb数据性能测试 如需转载,请标明出处:https://zhenghuisheng.blog.csdn.net/article/de
景联文科技:打造亿级高质量教育题库,赋能教育大语言模型新未来
随着人工智能技术的持续进步,从广泛的通用大语言模型到针对各行业的垂直大语言模型,已成为人工智能大语言模型技术深化演进的必然趋势。 教育大语言模型是适用于教育场景、具有庞大规模参数、融合了广泛的通用知识和专业知识训练形成的人工智能模型。能为人们提供更加智能、高效和个性化的学习体验。 景联文科技作为AI基础数据行业的头部企业,推出高质量教育题库,为教育大语言模型赋能。 高质量
512M读取亿级数据时候,进行优化显示结果1亿五千万链表时候出现溢出
需要使用分布式或者多线程:单机运行结果只能怪到1亿这个数量级 并发编程系列监测结果----读取开始 main D:\root\WriteBillionNum\billion.txt2020-01-23 13:14:58.00273[Throwable]并发编程系列监测结果---1000000000个数据全部读取完成耗时 147078255个出现异常 [Throwable]并发编程
亿级数据运行时在内存设置512M的时候JVM的监控日志
亿级数据的JVM的监控:记录仅仅作为一个参考 并发编程系列监测结果----写入开始 main D:\root\WriteBillionNum\billion.txt2020-01-22 16:19:36.00949[GC (Allocation Failure) [PSYoungGen: 33280K->1502K(38400K)] 33280K->1510K(125952K), 0.007
【Mongodb】Mongodb亿级数据性能测试和压测
一,mongodb数据性能测试 如需转载,请标明出处:https://zhenghuisheng.blog.csdn.net/article/details/139505973 mongodb数据性能测试 一,mongodb数据性能测试1,mongodb数据库创建和索引设置2,线程池+批量方式插入数据3,一千万数据性能测试4,两千万数据性能测试5,五千万数据性能测试6,一亿条数据性能测试7
Java架构-亿级网站大数据量下的高并发同步讲解
【原创】 陌霖Java架构 2019-05-06 12:10:00 对于我们开发的网站,如果网站的访问量非常大的话,那么我们就需要考虑相关的并发访问问题了。而并发问题是绝大部分的程序员头疼的问题, 但话又说回来了,既然逃避不掉,那我们就坦然面对吧~今天就让我们一起来研究一下常见的并发和同步吧。 为了更好的理解并发和同步,我们需要先明白两个重要的概念:同步和异步 ** 1、同步和异步的区别和
《亿级流量网站架构核心技术》概要
《亿级流量网站架构核心技术》目录一览 本书暂定名称为《亿级流量网站架构核心技术——跟开涛学搭建高可用高并发系统》,如有好的书名建议欢迎留言,必当重谢。内容已交由出版社编辑,相信很快就会和大家见面。主要内容结构和目录如下所示: 第一部分概述 高并发原则 无状态 拆分 服务化 消息队列 数据异构 缓存银弹 并发化 高可用原则 降级 限流 切流量 可回
![[转载]亿级Web系统搭建——单机到分布式集群](http://images.cnitblog.com/news/24634/201411/251724147778223.jpg)
[转载]亿级Web系统搭建——单机到分布式集群
本文转载自徐汉彬前辈的博文,原文地址:点击打开链接 自己通过这篇博文学到了很多,谢谢原文作者,特此转发分享下 当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题。为了解决这些性能压力带来问题,我们需要在Web系统架构层面搭建多个层次的缓存机制。在不同的压力阶段,我们会遇到不同的问题,通过搭建不同的服

亿级流量系统架构设计与实战
💂 个人网站:【 摸鱼游戏】【神级代码资源网站】【工具大全】🤟 一站式轻松构建小程序、Web网站、移动应用:👉注册地址🤟 基于Web端打造的:👉轻量化工具创作平台💅 想寻找共同学习交流,摸鱼划水的小伙伴,请点击【全栈技术交流群】 亿级流量系统架构设计与实战 在现代互联网时代,处理亿级流量的系统架构设计成为技术人员面临的重要挑战之一。本文将从架构原则、关键技术、实战案例三个方面
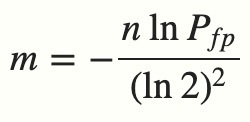
5 分钟搞懂布隆过滤器,亿级数据过滤算法你值得拥有!
在程序的世界中,布隆过滤器是程序员的一把利器,利用它可以快速地解决项目中一些比较棘手的问题。如网页 URL 去重、垃圾邮件识别、大集合中重复元素的判断和缓存穿透等问题。 布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有

亿级像素阵列相机“计算光学成像的探索者”-中关村企业借你一双慧眼
亿级像素阵列相机“计算光学成像的探索者”-中关村企业借你一双慧眼 目前,上亿像素大阵列复眼成像技术的公司,全球范围内仅3家公司。而在北京中关村,就有这样一家公司叫泰邦泰平,他们被称为“计算光学成像的探索者”。这个成立于2013年的年轻企业,不仅是2016年首批中关村前沿技术企业,而且是国家高新技术企业,拥有两项世界首创技术,多项国内外发明专利技术。可能有很多人对计

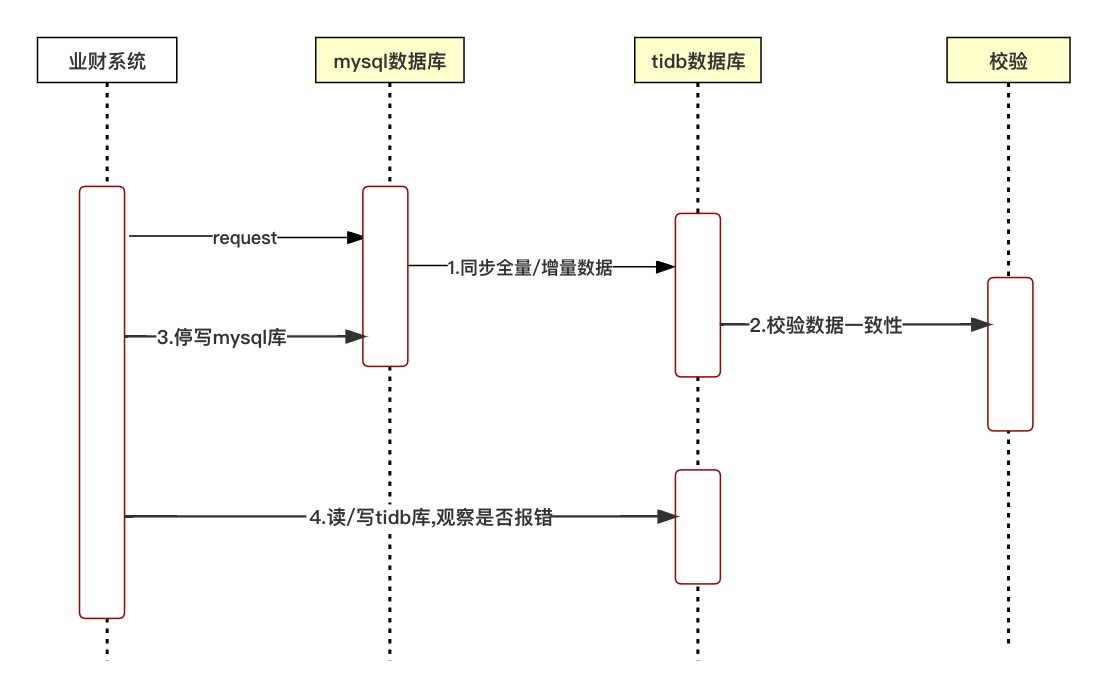
突破数据存储瓶颈!转转业财系统亿级数据存储优化实践
1.背景 1.1 现状 目前转转业财系统接收了上游各个业务系统(例如:订单、oms、支付、售后等系统)的数据,并将其转换为财务数据,最终输出财务相关报表和指标数据,帮助公司有效地进行财务管理和决策。 转转业财系统于2021年开始构建,前期为了满足需求短时间内上线,选择了主动接收上游业务系统的数据。然而随着时间的推移,数据量在不断增长,系统已经达到无法承载的边缘,引发了许多问题。因此,我们需要

亿级流量架构服务限流
为什么要限流 日常生活中,有哪些需要限流的地方? 像我旁边有一个国家景区,平时可能根本没什么人前往,但是一到五一或者春节就人满为患,这时候景区管理人员就会实行一系列的政策来限制进入人流量, 为什么要限流呢?假如景区能容纳一万人,现在进去了三万人,势必摩肩接踵,整不好还会有事故发生,这样的结果就是所有人的体验都不好,如果发生了事故景区可能还要关闭,导致对外不可用,这样的后果就是所有人都觉得体验糟
半小时训练亿级规模知识图谱,亚马逊AI开源知识图谱嵌入表示框架
来源:AI 科技大本营 本文约2300字,建议阅读9分钟 亚马逊 AI 团队开源了一款专门针对大规模知识图谱嵌入表示的新训练框架 DGL-KE,能让研究人员和工业界用户方便、快速地在大规模知识图谱数据集上进行机器学习训练任务。 知识图谱 (Knowledge Graph)作为一个重要的技术,在近几年里被广泛运用在了信息检索,自然语言处理,以及推荐系统等各种领域。学习知识图谱的嵌入表示 (Kno

深入浅出 -- 系统架构之日均亿级吞吐量的网关架构(DNS轮询解析)
在前篇关于《Nginx》的文章中曾经提到:单节点的Nginx在经过调优后,可承载5W左右的并发量,同时为确保Nginx的高可用,在文中也结合了Keepalived对其实现了程序宕机重启、主机下线从机顶替等功能。 但就算实现了高可用的Nginx依旧存在一个致命问题:如果项目的QPS超出5W,那么很有可能会导致Nginx被流量打到宕机,然后根据配置的高可用规则,Keepalived会对Nginx重

深入浅出 -- 系统架构之日均亿级吞吐量的网关架构(CDN内容分发)
亿级吞吐第二战-CDN内容分发 CDN(Content Delivery Network)内容分发网络是一种构建在现有网络基础上的智能虚拟网络,依靠部署在全球各地的节点,通过负载均衡、内容分发、机器调度等功能,使用户的请求能够被分发到离自身最近的节点处理,就近获取所需的资源,最终达到提升用户访问速度以及降低服务器访问压力等目的。 CDN出现的本质是为了解决不同地区用户访问速度不一致
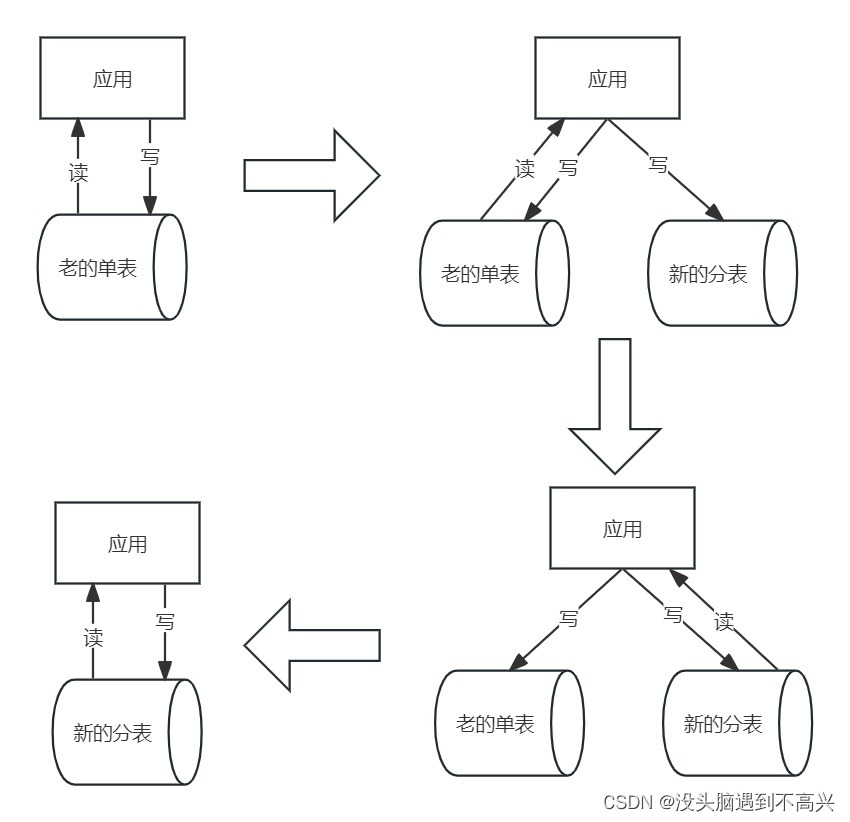
2.亿级积分数据分库分表:增量数据同步之代码双写,为什么没用Canal?
1.亿级积分数据分库分表:总体方案设计 上一篇博客中写了一下积分数据分库分表的总体方案设计,里面说了采用应用程序代码双写的方式实现的增量数据同步,本篇就对这一块进行一些细化的介绍,包括: 为什么不用Canal监听数据库binlog,有哪些优缺点吗? 为什么要用代码双写,有哪些优缺点吗?代码双写怎么实现的? Canal监听binlog 实现流程 Canal监听binlo
亿级Web系统的高容错性实践
原文地址:https://blog.csdn.net/linuxnews/article/details/51371338 背景介绍 大概三年前,我在腾讯负责的活动运营系统,因为业务流量规模的数倍增长,系统出现了各种各样的异常,当时,作为开发的我,7*24小时地没日没夜处理告警,周末和凌晨也经常上线,疲于奔命。后来,当时的老领导对我说:你不能总扮演一个“救火队长”的角色, 要尝试从系
NEO4J亿级数据全文索引构建优化
NEO4J亿级数据全文索引构建优化 一、数据量规模(亿级)二、构建索引的方式三、构建索引发生的异常四、全文索引代码优化1、Java.lang.OutOfMemoryError2、访问数据库时3、优化方案4、优化代码5、执行效率测试 如果使用基于NEO4J的全文检索作为图谱的主要入口,那么做好图谱搜索引擎的优化是非常关键的。 一、数据量规模(亿级) count(relat
存储过程实现上亿级图数据分块ETL
图重构-重复关系重构 图数据分块ETL函数与过程功能介绍完整实现案例 图数据分块ETL 图数据ETL的一个场景是需要将上亿条上百G的原始数据构建为图数据,在内存不够用的情况下保证数据构建过程可以平稳顺利运行,需要使用数据分块的方式进行构建。如下通过存储过程实现数据分块方案。该解决方案依赖于原始数据库的自增ID【超大CSV文件的构建可以导入MySQL之后构建】,经过测试可以在生

MySQL亿级数据表DDL解决方案及实战
MySQL亿级数据表DDL解决方案及实战 背景 随着业务的发展,用户对系统需求变得越来越多,这就要求系统能够快速更新迭代以满足业务需求,通常系统版本发布时,都要先执行数据库的DDL变更,包括创建表、添加字段、添加索引、修改字段属性等。 痛点:在数据量不大的情况下,执行DDL速度较快,对业务基本没啥影响,但是数据量大的情况,而且我们业务做了读写分离,接入了实时数仓,这时DDL变更就是一