本文主要是介绍AI算力专题:算力系列之四-各省算力规划建设梳理-绿色低碳高质量发展-部署算力建设AI产业研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天分享的是AI算力系列深度研究报告:《AI算力专题:算力系列之四-各省算力规划建设梳理-绿色低碳高质量发展-部署算力建设AI产业研究》。
(报告出品方:中泰证券)
报告共计:40页
数据中心能耗情况
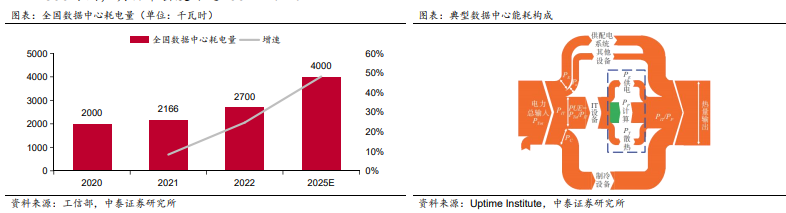
随着越来越多以GPU为核心的智算中心落地,数据中心的能耗、散热问题日益凸显。以运行PUE为1.57的数据中心为 例,IT设备能耗占比达63.7%,为数据中心最大,其次就是制冷系统能耗,占比可达27.9%。
• 数据中心是新能耗大户,电力消耗巨大,节能减排迫在眉睫。2022年全年,全国数据中心耗电量达到2700亿千瓦时, 占全社会用电量约3%,预计 2025 年数据中心耗电量将占全社会耗电量的 5%以上。
• 服务器技术演进带来能耗挑战。随着服务器从普通机架式向小型机、刀片式的转变,机柜能耗从 2-4KW 猛增至 6- 15KW,导致数据中心能耗居高不下。此外,传统数据中的服务器采用专用方式分配,资源的利用率一般在 30%下, 一部分处于空闲状态的服务器每时每刻都在浪费电能、侵蚀 IDC 利润空间。
• 后摩尔定律时代下,随着数据中心的计算能力和功率密度的增加、芯片算力与功耗的大幅提升,数据中心的能耗和发 热量不断攀升。目前主流系列处理器仅CPU功耗已高达350~400TDP/W,而GPU的功耗远远高于CPU,以英伟达 H800为例,其功率密度可达700TDP/W。
福建省算力建设规划
福建省布局提升算力基础、加强关键技术攻关。预计到2025年,福建省新型基础设施建设取得突破性进展,福建省算 力达到8EFLOPS以上,高性能计算峰值算力超300PFLOPS,在用标准机架数达到15万个,新建大型、超大型数据中 心PUE不高于1.3,建成300个边缘数据中心,力争融入全国一体化大数据中心协同创新体系。
福建实施算力网络统筹布局行动,优化布局大数据中心。
• 福建省将加强全省算力资源跨区域统筹布局和统一调度,重点依托数字福建(长乐、安溪)产业园打造数据中心集群, 规模化、集约化建设存算一体的新型数据中心。
• 福建省建设提升智能计算中心。加快建设厦门数字工业计算中心、泉州先进计算中心等,扩展升级省超算中心、人工智能计算中心(福州)、厦门鲲鹏超算中心。建设省算力资源一体化服务平台,构建低成本公共算力服务体系。

山东省算力建设规划
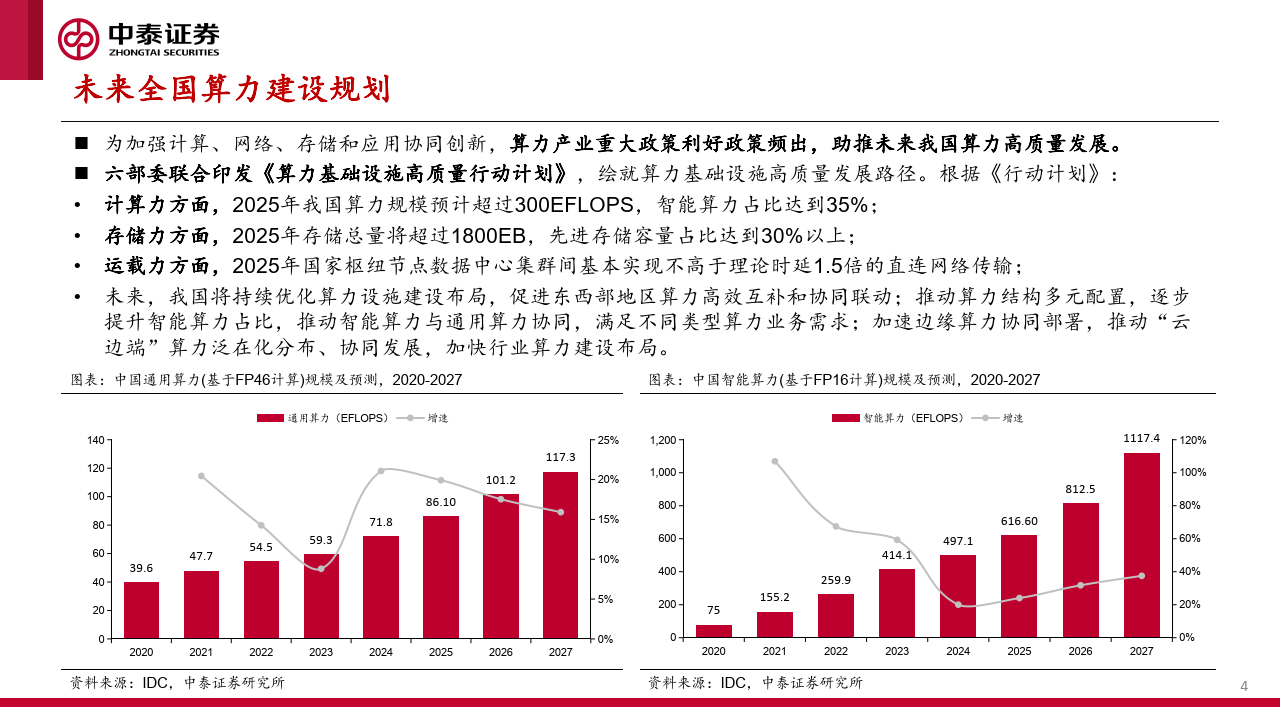
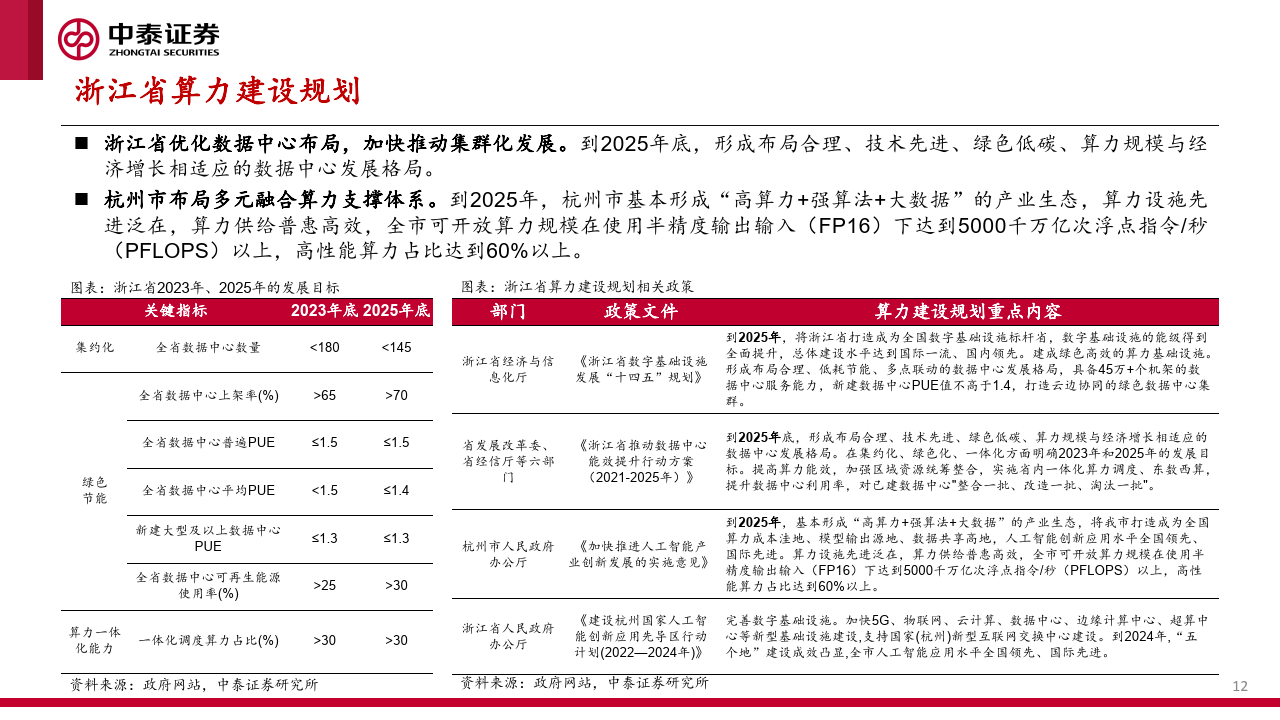
山东省明确持续统筹优化算力建设布局,筑强算力网络运力体系,提升算力网络赋能应用水平,推动算力网络产业创 新发展。到2025年,全省数据中心在用标准机架总数达到45万个,总算力达到 12.5EFLOPS,智能算力占比达到35%, 存力规模达到65EB,先进存储占比达到35%以上。打造 “全省存算力一张网”,提升数据中心云算力资源调度能力。
2024年,山东将以数字变革新赛道引领形成经济发展新动能。将部署高性能智能计算中心,统筹布局通用和垂直大模 型算力,累计建成5A级省级新型数据中心25个以上,智能算力比例达到30%,建成“山东算网”;将重点支持电源使用 效率高、服务能力强的大中型数据中心和算力时延低的边缘数据中心建设。











报告共计:40页
这篇关于AI算力专题:算力系列之四-各省算力规划建设梳理-绿色低碳高质量发展-部署算力建设AI产业研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








