本文主要是介绍从大模型中蒸馏功能性重排列任务的先验知识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

导读
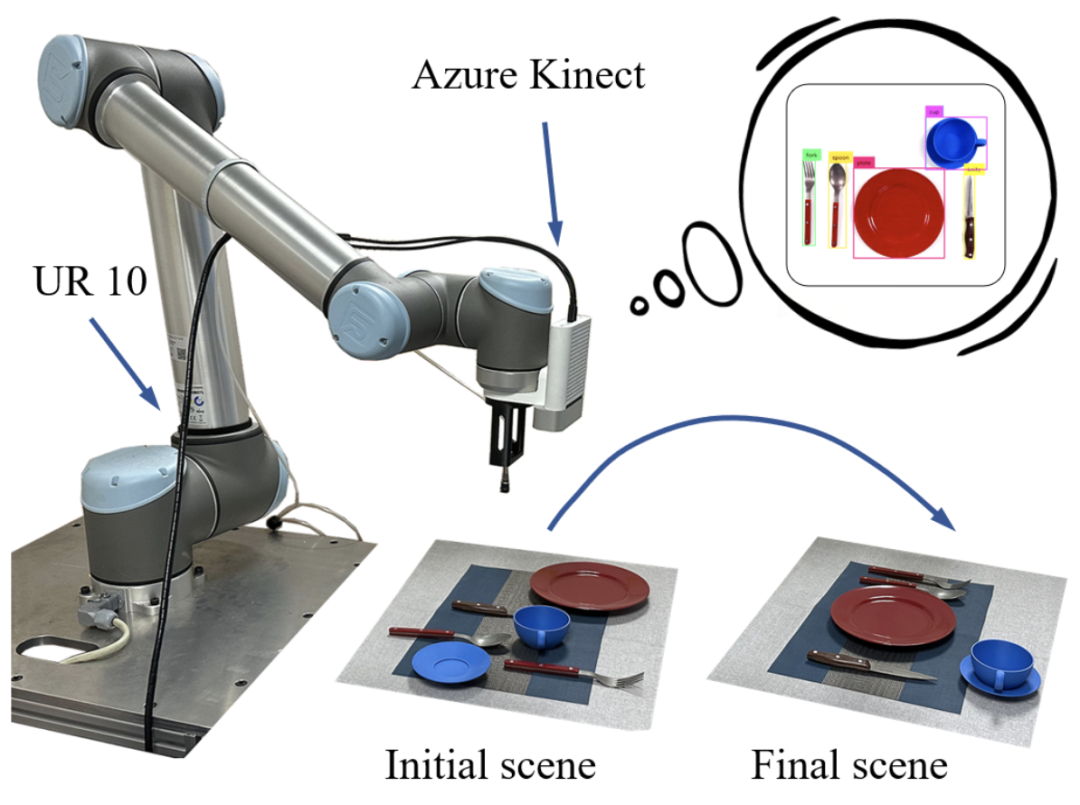
本文是VCC朱家辉同学对论文 Distilling Functional Rearrangement Priors from Large Models 的解读,该工作来自北京大学和中山大学,并已被发表在国际机器人顶会ICRA 2024上。
项目主页:
https://sites.google.com/view/lvdiffusion/
该工作提出了一种结合大语言模型和图像生成模型来获得功能性重排列任务的先验知识的方法。该方法专注于生成符合功能要求的物体目标位置,这些位置在随后的机器人操控任务中具有重要意义。通过这种结合,算法不仅能更精准地生成目标位置,还能有效解决图像生成模型中提示词与生成结果不一致的问题。
I 引言
近年来,基于图像生成模型的机器人重排列任务引起了广泛关注。这种方法的核心在于,通过使用预训练的图像生成模型,根据物体的初始状态输出重排列目标图像。与传统生成方法(例如,从零开始人工标注数据集或设计奖励函数)相比,这种方法能够灵活生成各种场景下的目标图像。尽管最新的生成模型能较好地生成符合功能性要求的图像,但由于模型的随机性,所以常常无法精确地复现初始场景中相同种类和数量的物体。因此,这类方法在测试阶段通常需加入过滤模块,以筛选出符合数量要求的图像。
本篇导读论文介绍了一种新方法,通过蒸馏大模型来获取功能性重排列的先验知识。该方法结合了大语言模型和图像生成模型,用于收集各种不同排列的示例数据集(包括物体的类别和位置)。随后,通过训练扩散模型,使其符合数据集的分布。在测试阶段,扩散模型能根据物体的类别和初始位置生成每个物体的目标位置。这种通过蒸馏的方法比以往方法更精确地生成目标位置,并能将生成过程从数分钟缩短至数秒,极大满足了机器人重排列任务对实时性的需求。
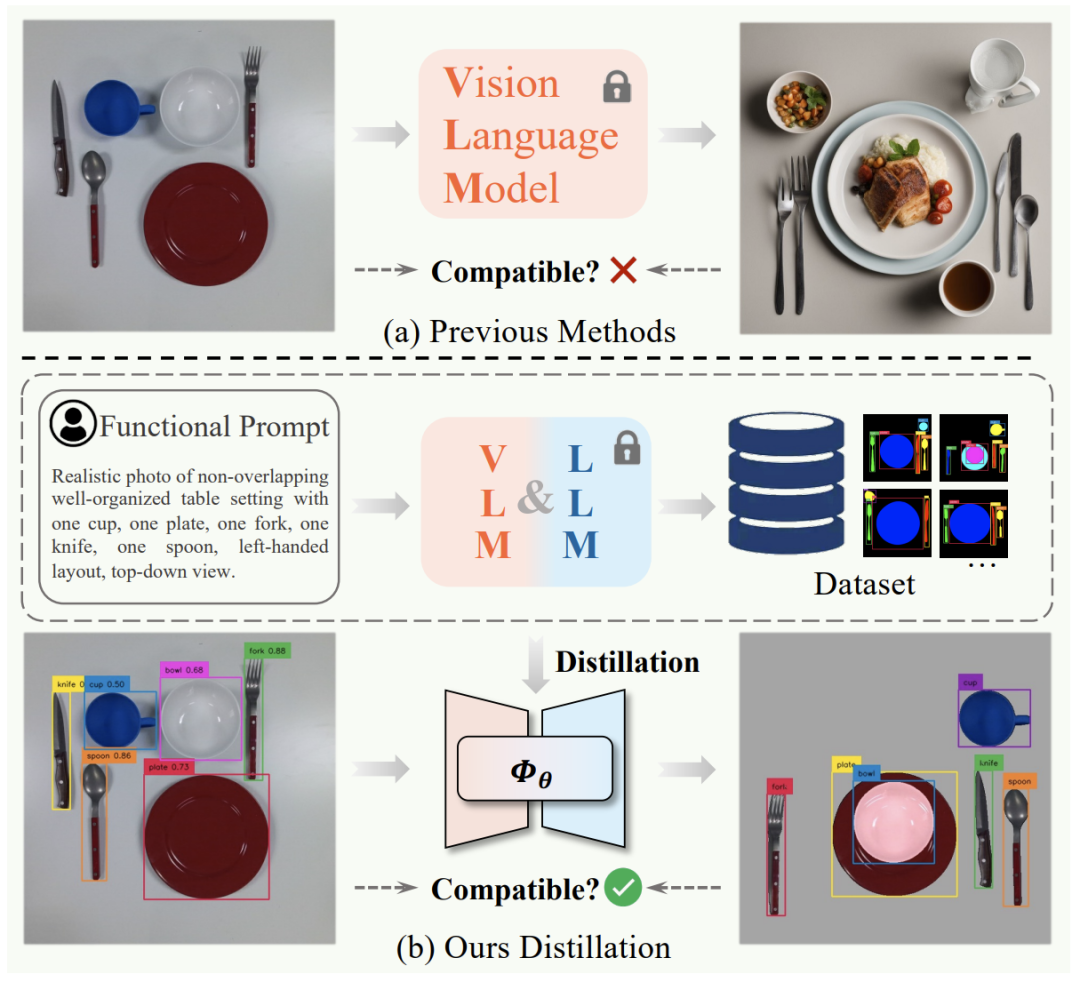
图1 之前方法跟本论文方法的总览图
技术贡献
本工作主要贡献如下:
-
提出了一种新的框架,从大语言模型和图像生成模型中蒸馏功能性重排列的先验知识,用于训练扩散模型,以满足功能性重排列的要求;
-
提出了利用大语言模型帮助缓解图像生成模型在提示词与生成结果不一致的问题;通过大量实验验证了该方法在生成目标位置和真实机器人操控任务中的有效性。

图2 机器人生成目标图像并执行动作过程
III 方法介绍
本方法的关键在于训练一个能够生成与初始物体数量相同且符合功能性要求的扩散模型。整个方法分为三个主要步骤:第一,数据收集:首先,利用大语言模型和图像生成模型收集数据集。数据集中包含物体的二维位置、大小和类别标签,这些信息共同定义了物体的数据分布。第二,模型训练:接着,使用这个数据集来训练基于分数的扩散模型。该模型旨在对条件分布进行建模,从而能够精确地生成目标位置。第三,推理:在推理阶段,目标检测器从当前图片中提取物体的初始位置和类别信息,并将这些信息输入到训练好的扩散模型中。模型随后生成符合功能性要求的物体目标位置。值得注意的是,这里的生成内容是物体的目标位置而非目标图像,如图3所示,在推理阶段生成的是“Goal Poses”,图中只是将每个物体的目标位置进行了可视化处理。最终,机器人根据这些信息将物体从初始位置移动到目标位置,完成重排列任务。
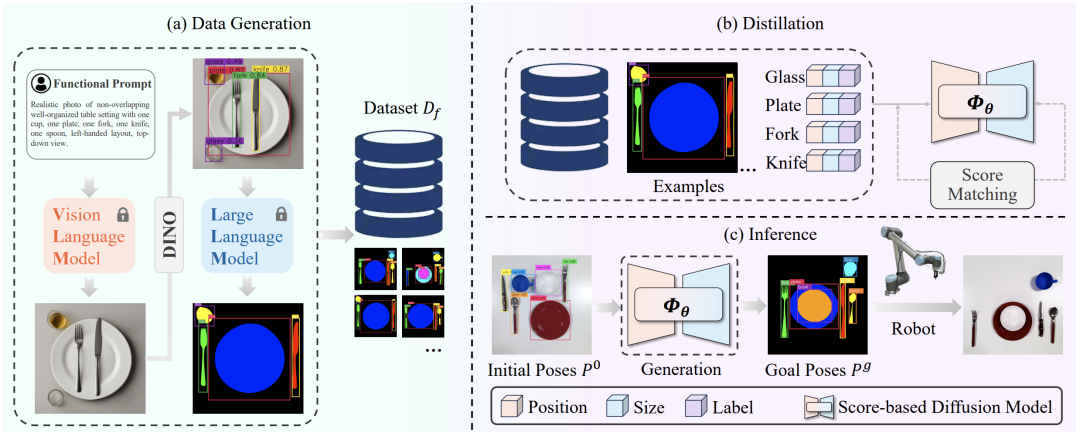
图3 算法三大步骤
接下来分别介绍每一步的具体做法:
通过大语言模型和图像生成模型来收集数据
数据收集第一阶段:使用图像生成大模型(例如Stable Diffusion XL)生成初始物体摆放示例。这涉及使用特定的提示词模板,如“Realistic photo of [adjective] [setting description] with [num1] [object1], [num2] [object2], ..., [functional layout], [view point]”,图3中左上角展示了一个具体示例。然后,使用目标检测器(如GroundingDino)来获取物体的位置和类别信息。由于图像生成模型的随机性,需要过滤掉那些不符合提示词要求(如物体数量过多或物体类别未知)的图像。
数据收集第二阶段:优化初始重排列示例。首先,向大语言模型(如GPT-4)输入任务描述、用户习惯、以及目标检测器提供的物体包围盒和类别信息。目的是生成符合个人偏好的功能性排列要求。接着,让大语言模型推断出符合功能性要求的物体类别和数量,删除多余物体,并重新摆放剩余物体,以生成符合要求的物体位置。这一阶段使用思维链策略进行提问,并在第二次提问时加入具体示例,以确保获得统一格式和符合要求的物体位置。这些信息用于构建数据集。
将收集的数据集蒸馏到扩散模型中
这一步骤旨在将收集的数据用于训练条件扩散生成模型中,以对数据分布进行建模,该模型训练后能生成符合功能性要求的目标位置(不是图像)。这里采用基于分数的扩散模型来估计数据分布,更具体地,使用方差爆炸随机方程构建了一个连续扩散过程,并在训练过程中估计加噪声后数据分布的得分函数。通过降噪分数匹配(Denoising Score Matching)训练得分网络来估计噪声,这里估计的噪声相当于估计数据分布,具体公式请看原论文。得分网络的架构主要是一个图神经网络,适应不同数量物体的输入。所有物体构成一个完全连接的图,每个节点包含物体的位置、大小和类别,得分网络输入这个图,输出每个节点的得分。
使用训练后扩散模型重排列物体
在测试时,用目标检测器得到当前观察图片中物体的位置、大小和类别,然后通过训练好的得分网络生成目标位置。现在就可以计算出从初始位置到目标位置之间的平移,然后通过现成的SuctionNet来得到抓取物体的点,并根据前面得到的平移来计算放置物体的点,最后机器人对每个物体执行到达这个抓取点,抓取物体,到达放置点这些动作,直到完成任务。
IV 部分结果展示
在这部分,我们将展示本论文算法在整理桌面任务中的效果。考虑了从简单到复杂的六种不同场景(S1至S6),每个场景的复杂度逐渐增加。第一行展示的是初始的物体位置,第二行展示了基线DALL-E-Bot整理后的结果。可以观察到,本论文提出的方法在整理效果上显著优于基线模型。原因在于,基线DALL-E-Bot采用的DALL-E2图像生成模型具有较高的随机性,无法保证生成的物体数量与初始场景一致。当生成的图像中物体过多时,算法难以匹配当前场景中的物体与生成图像中的对应物体,因此只能按照相似度最高的方式进行整理。而本论文的方法专注于生成物体的目标位置,这些位置是根据功能性重排列数据集的分布生成的,且允许物体之间发生重叠,从而在整理桌面的舒适度上优于DALL-E-Bot。
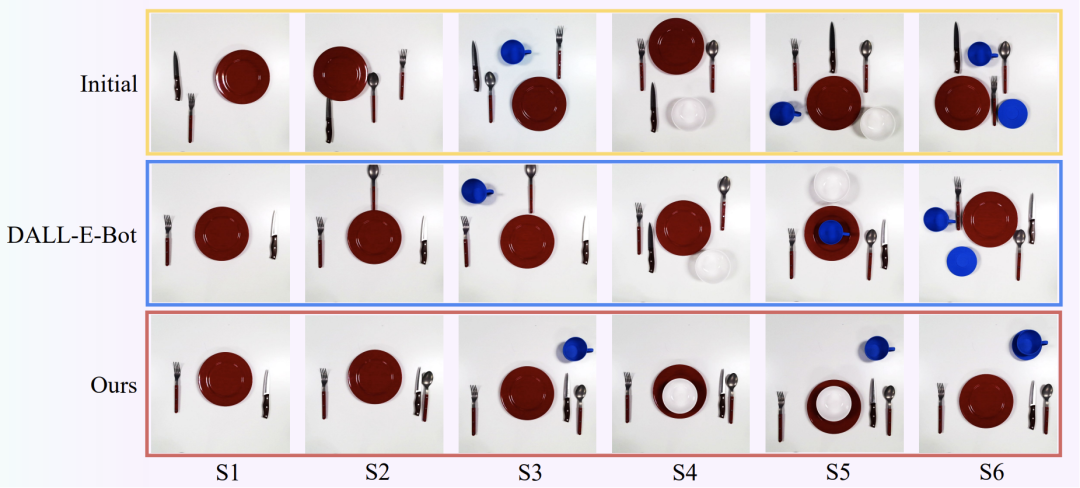
图4 相较于现有方法,本文在整理餐桌时舒适度有较大提高
此外,我们还比较了四种不同场景下,整理后的物体位置与真实物体位置之间的差距。差距越小意味着结果越接近真实摆放情况。与其他方法相比,本文结果最接近真实例子。关于其他消融实验和基线方法的具体实现,请参考原文。
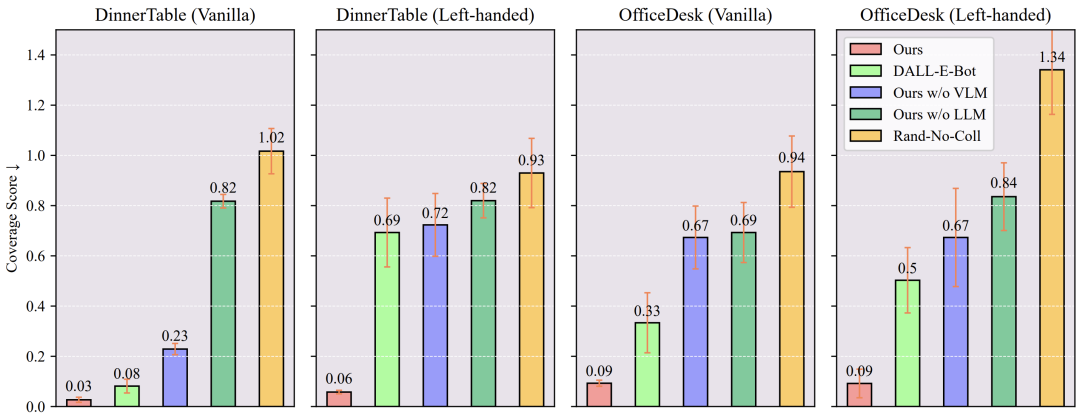
图5 本论文与现有方法的整理结果比较
V总结与展望
近年来,大语言模型和扩散模型的快速发展为机器人感知和操控领域带来了新的活力,如何有效地结合大语言模型和扩散模型至关重要。尽管现有方法主要使用扩散模型来生成目标图像,但仍有提升空间。本研究提出的结合大语言模型和扩散模型的方法,显著缩小了这一差距,使得生成符合功能性要求的目标位置成为可能。
未来的工作应当考虑物体可能发生的旋转,并探索如何提高算法在不同场景下的泛化能力。
VI 思考与讨论
Q: Pormpt在LLM尤为重要,第一步的LLM的prompt具体是什么?
A: 在整理左撇子餐桌的例子。第一阶段的向LLM提出功能性要求,用户输入Prompt和LLM回答是:
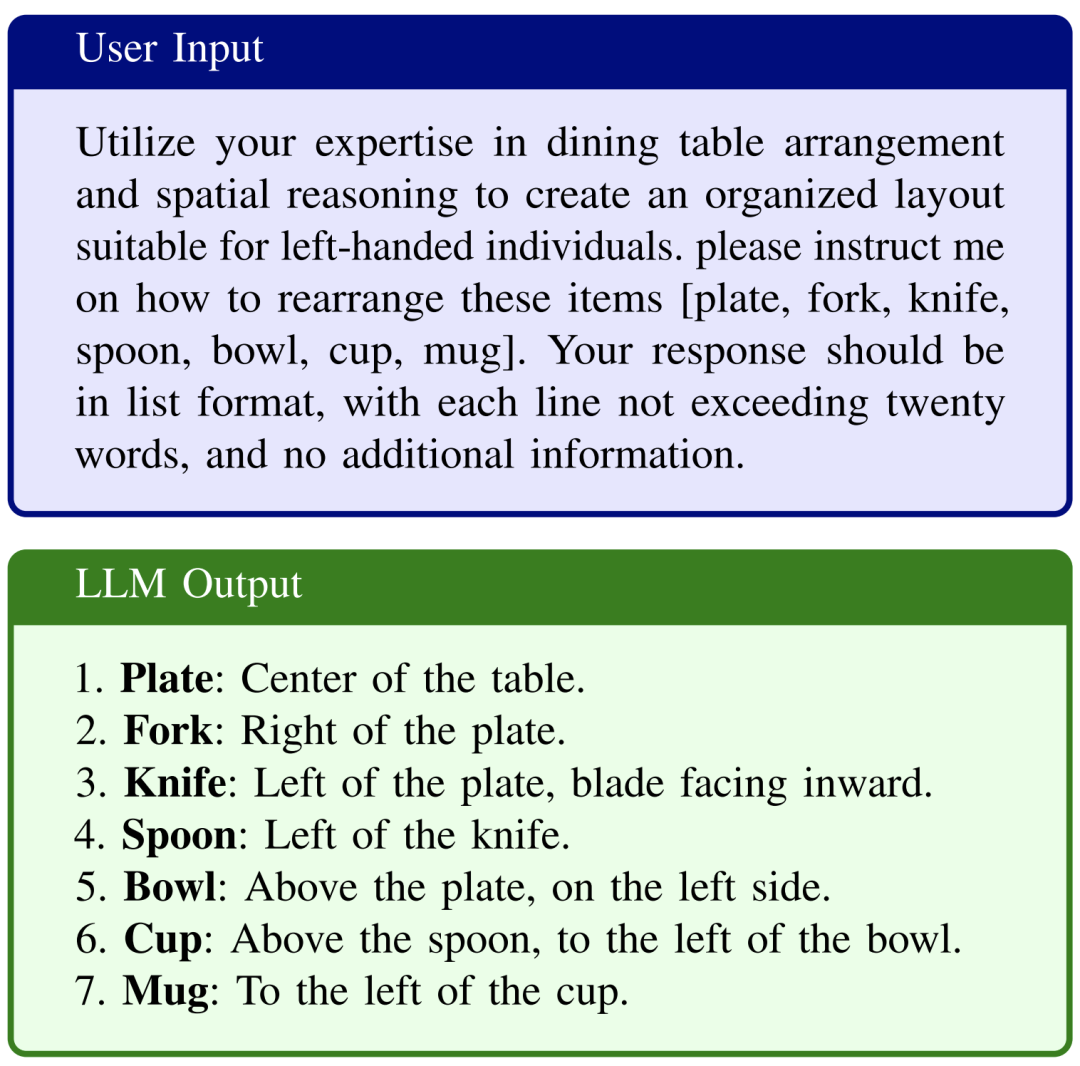
图6 第一阶段的prompt
第二阶段是提示LLM 推断符合上述功能性要求下场景所需的物体类型和数量,删除多余的物品,并重新定位剩余的物体以生成预期的坐标级布局,与第一阶段中确定的功能要求相一致。用户输入prompt是:

图7 第二阶段的prompt总览
由于篇幅原因,更具体的 Output format 和 In Context Example 的 prompt 请参考原论文。
Q: 得分网络的具体网络架构是怎样的?
A: 网络输入一个完全连接的图,其中第i个节点包含了物体的位置、大小和类别标签,经过两层MLP编码升维后,经过两次EdgeConv,能有效地捕捉图中节点间的关系,也就是更能理解物体的位姿和条件之间的关系,输出是每个节点上的得分。
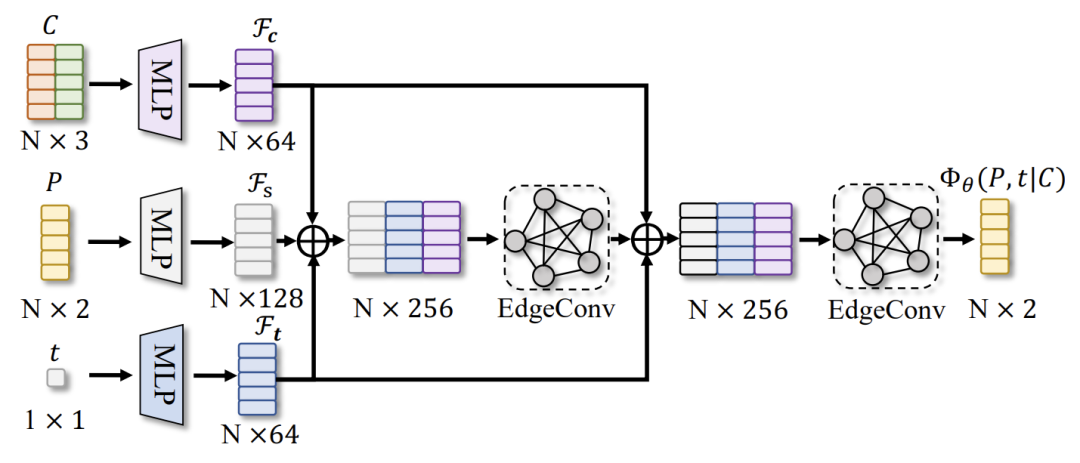
图8 得分网络架构
Q: 第二阶段训练后扩散模型只能生成数据集相关场景下的目标位置,如何让算法在其他未见过的场景中生成目标位置或图像,从而提高泛化到其他场景中的表现能力。
这篇关于从大模型中蒸馏功能性重排列任务的先验知识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






