本文主要是介绍redis集群cluster均匀命中--hash性一致算法--hash slot,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、redis cluster介绍
2、最老土的hash算法和弊端(大量缓存重建)
3、一致性hash算法(自动缓存迁移)+虚拟节点(自动负载均衡)
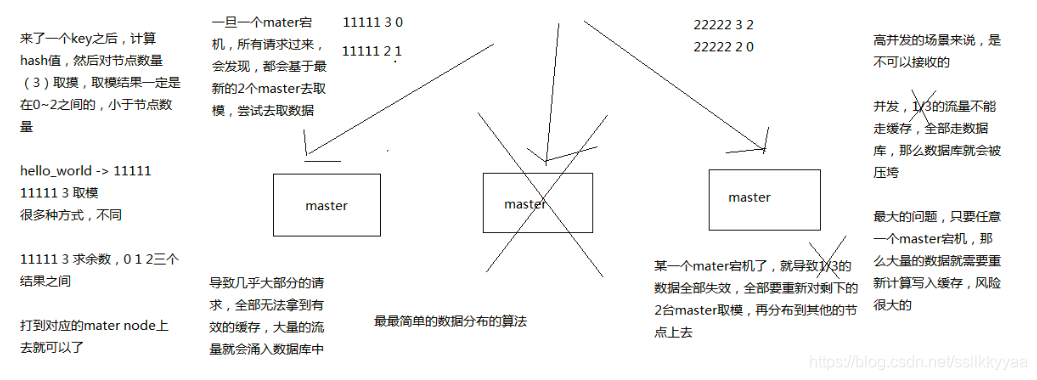
不用遍历 --》 hash算法: 缓存位置= hash(key)%n
新增/减少 节点 --》缓存位置失效--》hash环
hash环 节点少--》数据倾斜--》添加虚拟节点
http://www.zsythink.net/archives/1182
4、redis cluster的hash slot算法
讲解分布式数据存储的核心算法,数据分布的算法
hash算法 -> 一致性hash算法(memcached) -> redis cluster,hash slot算法
用不同的算法,就决定了在多个master节点的时候,数据如何分布到这些节点上去,解决这个问题
1、redis cluster介绍
redis cluster
(1)自动将数据进行分片,每个master上放一部分数据
(2)提供内置的高可用支持,部分master不可用时,还是可以继续工作的
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379
16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权
cluster bus用了另外一种二进制的协议,主要用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
2、最老土的hash算法和弊端(大量缓存重建)
为什么要用hash算法:增加节点命中率
新加节点 对 已有节点的影响一致
命中规则:
hash(key)% n =命中位置
增加一台,则有 n/n+1 的概率命不中。

3、一致性hash算法(自动缓存迁移)+虚拟节点(自动负载均衡)
做成一个圆环,解决命中率问题。
https://blog.csdn.net/bntX2jSQfEHy7/article/details/79549368
4、redis cluster的hash slot算法
redis cluster有固定的16384个hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot
redis cluster中每个master都会持有部分slot,比如有3个master,那么可能每个master持有5000多个hash slot
hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去
移动hash slot的成本是非常低的
客户端的api,可以对指定的数据,让他们走同一个hash slot,通过hash tag来实现
hash slot
这篇关于redis集群cluster均匀命中--hash性一致算法--hash slot的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








