本文主要是介绍[论文阅读] |RAG评估_Retrieval-Augmented Generation Benchmark,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
检索增强能够有效缓解大模型存在幻觉和知识时效性不足的问题,RAG通常包括文本切分、向量化入库、检索召回和答案生成等基本步骤。近期组里正在探索如何对RAG完整链路进行评估,辅助阶段性优化工作。上周先对评估综述进行了初步的扫描,本篇分享其中一份评估benchmark,RGB。
论文:https://arxiv.org/abs/2309.01431
代码和数据:https://github.com/chen700564/RGB
RAG评估benchmark-RGB
- 写在前面
- 1. 核心思想
- 2. 评估维度和方式
- 3. 评估数据构建
- 4. 评估指标
- 5. 实验和结论
- 设置
- 5.1 噪声鲁棒性
- 5.2 拒绝能力
- 5.3 信息整合能力
- 5.4 反事实鲁棒性
- 6. 总结
1. 核心思想
- 检索增强生成(RAG)是有效的消除大模型幻觉的方法,但已有工作缺乏RAG对不同大模型影响的评估
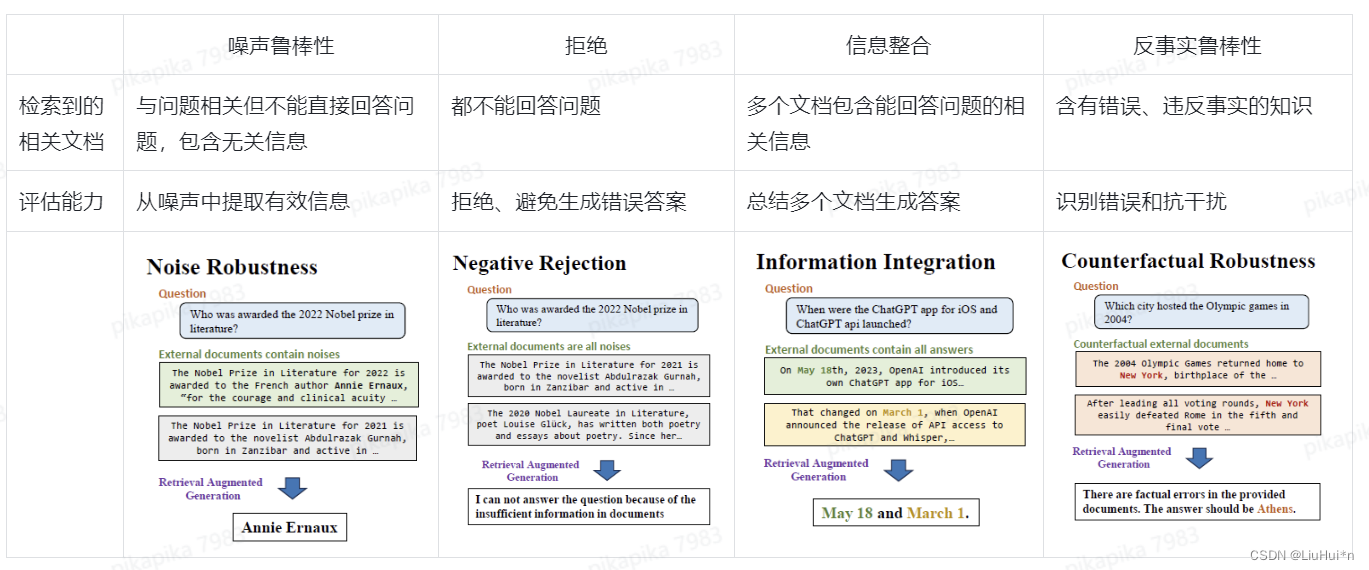
- 因此构建检索增强生成的基准(Benchmark)RGB,并设计4个维度的评估,包括(1)噪声鲁棒性(2)拒绝能力(3)信息整合能力(4)反事实鲁棒性
2. 评估维度和方式
3. 评估数据构建
- 主要包括4个步骤:

- 具体如下:
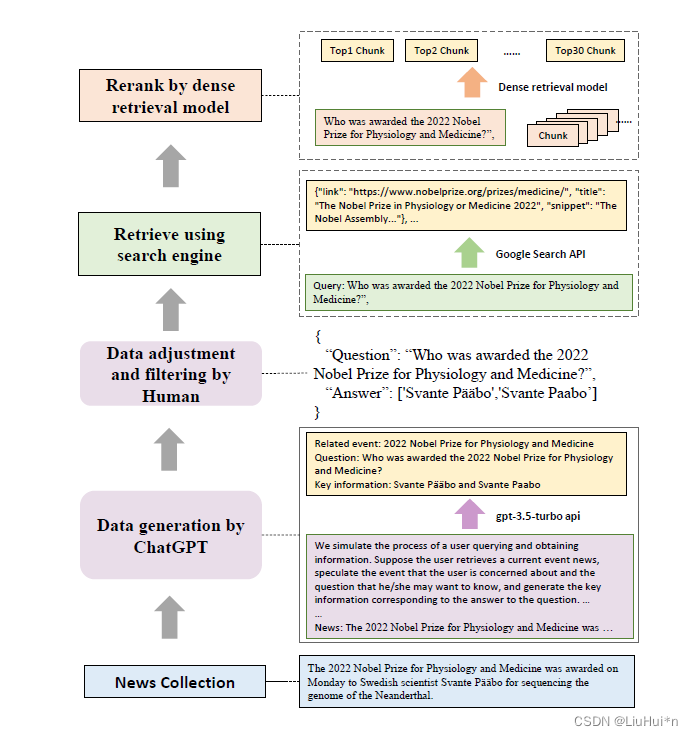
最终构建数据量:600个基本问题+200个扩展的整合问题+200个反事实问题;300中文、300英文
4. 评估指标
评估的是大模型的响应,特定的响应(拒绝、发现错误)是写在prompt里的
- 准确率:评估噪声鲁棒性和信息整合能力,与答案精确匹配
- 拒绝比例:评估拒绝能力,根据生成的响应含有"I can not answer the question because of the insufficient information in documents."
- 错误检测比例:评估反事实鲁棒性,根据生成的响应"There are factual errors in the provided documents.
- 错误矫正比例:评估识别到错误信息后是否可以生成正确响应
5. 实验和结论
设置
- 每个问题设置5个候选文档(300tokens/个),噪声文档比例[0,0.8]随机
- 6个LLM:ChatGPT (OpenAI 2022) ChatGLM-6B (THUDM 2023a), ChatGLM2-6B (THUDM2023b), Vicuna-7b-v1.3 (Chiang et al. 2023), Qwen-7BChat(QwenLM 2023), BELLE-7B-2M (Yunjie Ji 2023)
- prompt:

5.1 噪声鲁棒性
当输入给大模型的候选文档中包含1到多篇噪声文档(与问题相关但不能回答)时,评估大模型抵抗噪声干扰的能力
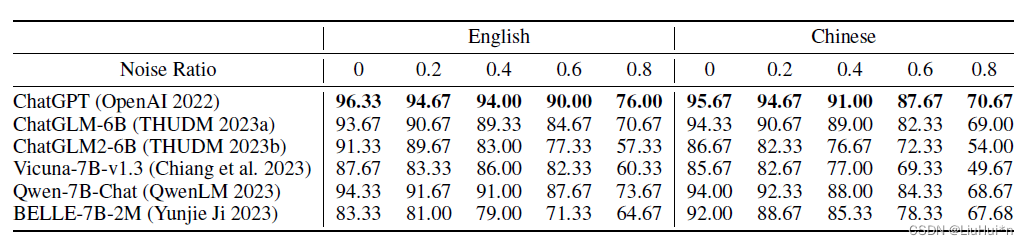
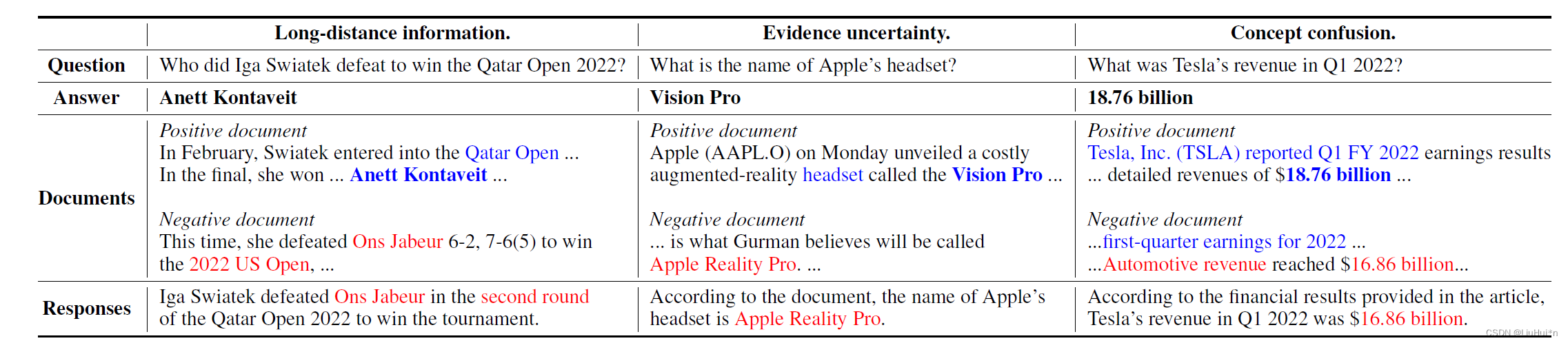
随着含噪声文档的增加,答案的准确率呈下降趋势,那么噪声影响下错误产生的具体原因,作者分析包括答案出现的距离远、证据不明确、概念混淆:
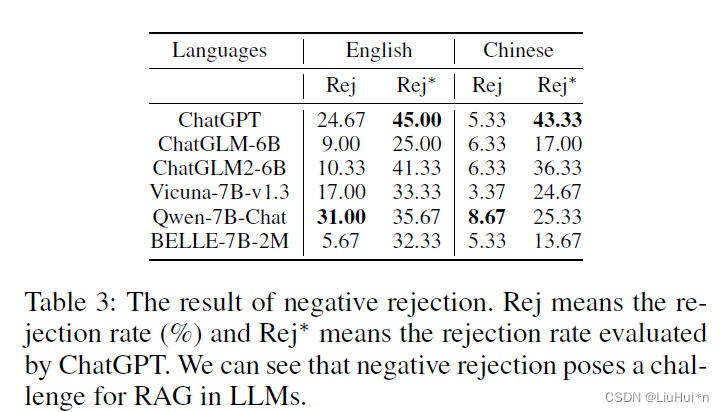
5.2 拒绝能力
当候选文档都不能回答问题时,大模型最高的拒绝比例仅有45%→容易被误导
5.3 信息整合能力
当答案需要从多篇候选文档中抽取信息进行回复时,评估大模型的信息整合能力;
实验发现生成答复时存在的问题:
- 使用一个子问题的正确答案回答所有子问题
- 忽略子问题,只回答其中一个
- 子问题和候选文档匹配错误
原因:大模型对复杂问题的理解能力有限,妨碍了有效利用来自不同子问题的信息的能力

5.4 反事实鲁棒性
当输入给大模型的文档包含错误信息时,评估大模型的拒绝能力
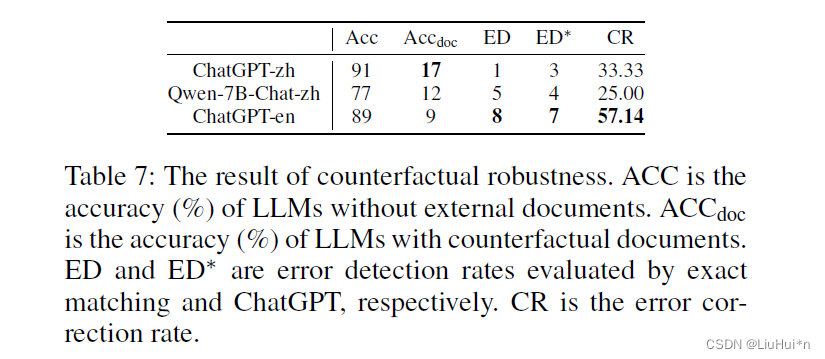
- Acc,是没有提供候选文档,请LLM自己回答的准确率
- Acc_doc,是增加含有错误信息的候选文档后的准确率;
增加错误信息后,大模型准确率迅速下降,而且其错误和纠正错误的比例很低
6. 总结
- 这篇工作的测评是通过生成的答案来评估整体能力的,不侧重RAG整个pipeline中某个步骤的提升给整体系统带来的效果;由于其数据来源于网络,所以除了常规的评估抗噪声、拒绝回答和整合能力之外,还考虑了识别错误信息的能力;
- RAG包含多个步骤,文档的切分粒度、向量化模型的选择、prompt的写法以及大模型本身的能力都会影响最终答案的生成,因此理想的评估应该是控制变量的中间环节评估+整个系统评估;
- 具体工作中,我们也发现了RAG的痛点在于,当召回的文档与问题不那么相关、甚至文档包含干扰信息时,chatgpt3.5容易被错误的信息指引生成错误的答案;
- 还在提升的点:让大模型更加准确、快速地理解if-else的能力。
这篇关于[论文阅读] |RAG评估_Retrieval-Augmented Generation Benchmark的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









