本文主要是介绍【MATLAB第92期】基于MATLAB的集成聚合多输入单输出回归预测方法(LSBoost、Bag)含自动优化超参数和特征敏感性分析功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【MATLAB第92期】基于MATLAB的集成聚合多输入单输出回归预测方法(LSBoost、Bag)含自动优化超参数和特征敏感性分析功能
本文展示多种非常用多输入单输出回归预测模型效果。
注:每次运行数据训练集测试集为随机,故对比不严谨,不能完全反映模型效果。
样本数据选用7变量1因变量。
%% 导入数据
res = xlsread('数据集.xlsx');%% 划分训练集和测试集
temp = randperm(103);P_train = res(temp(1: 80), 1: 7)';
T_train = res(temp(1: 80), 8)';
M = size(P_train, 2);P_test = res(temp(81: end), 1: 7)';
T_test = res(temp(81: end), 8)';
N = size(P_test, 2);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
一、LSBoost提升决策树
1、模型介绍
LSBoost是MATLAB中的一种监督学习算法,可用于对连续数值数据进行预测。它是最小二乘增强机器学习算法的一种实现,这是一种集成学习方法,它将多个较弱模型的预测相结合,以创建更强、更准确的模型。
LSBoost通过构建线性模型的集合来工作,其中每个模型都经过训练,以根据可用数据的子集进行预测。模型是按顺序增长的,每个模型都从上一个模型的错误中学习。通过取系综中所有模型的预测的加权平均值来进行最终预测。
LSBoost的一个关键优势是它能够有效地处理丢失的数据和大型数据集。它还有许多超参数,可以进行调整以提高模型性能,包括学习率、树的深度和正则化参数。
总体而言,LSBoost是MATLAB中用于回归任务的强大且广泛使用的工具,它已成功应用于各种现实世界的问题,如预测建模、时间序列预测和客户流失预测。
优点:对大数据集有效。LSBoost不需要归一化特征,如果数据是非线性、非单调的或具有分离的簇,则LSBoost可以很好地工作。
缺点:LSBoost可能会过度拟合数据,尤其是在模型过于复杂且数据嘈杂的情况下。
2、模型建立
模型参数:
(1)NumLearningCycles—集成学习周期数——100(默认)| 正整数
'NumLearningCycles’集成学习周期数,指定为由和 正整数组成的逗号分隔对组。在每个学习周期中,都会为 中的每个模板对象训练一个弱学习器Learners。因此,该软件可以训练 NumLearningCycles*numel(Learners)个 学习者。并将其存储在Mdl.Trained.
(2)Learners—在集成中使用弱学习器——‘tree’(默认) | 树模板对象| 树模板对象的单元向量
在集成中使用的弱学习器,其中包含’Learners’和 ‘tree’、树模板对象或树模板对象的单元向量。
(3)NPrint—打印输出频率——“off”(默认)| 正整数
打印输出频率,指定为正整数或"off"。
(4)NumBins—数值预测变量的箱数——[](空)(默认) | 正整数标量
其中包含’NumBins’和 正整数标量。如果该’NumBins’值为空(默认),则不会对任何预测变量进行分箱。
如果将该’NumBins’值指定为正整数标量 ( numBins),则将每个数值预测变量分入最多等numBins概率的分箱,然后在分箱索引而不是原始数据上生长树。
numBins如果预测变量的numBins唯一值少于该值,则箱的数量可能会较少。
当您使用大型训练数据集时,此分箱选项可以加快训练速度,但可能会导致准确性潜在下降。您可以’NumBins’,50先尝试,然后根据准确性和训练速度更改该值。经过训练的模型将 bin 边缘存储在BinEdges属性中。
(5)FResample—要重新采样的训练集的分数——1(默认)| (0,1] 中的正标量
对每个弱学习器重新采样的训练集的分数,指定为 (0,1] 中的正标量。要使用’FResample’,请设置 Resample为’on’。
(6)Replace—指示替换样本的标志——‘on’(默认)|‘off’
‘Replace’指示替换采样的标志,指定为由and’off’或组成的逗号分隔对’on’。
对于’on’,软件对训练观察值进行替换采样。
对于’off’,软件对训练观察结果进行采样而不进行替换。如果设置Resample为’on’,则软件会假设权重均匀,对训练观测值进行采样。如果您还指定了增强方法,则软件会通过重新加权观测值来增强。
除非您设置Method为’bag’或设置为Resample,'on’否则Replace没有任何效果。
(7)Resample—指示重新采样的标志——‘off’|‘on’
‘Resample’指示重新采样的标志,指定为由and’off’或组成的逗号分隔对’on’。
如果Method是 boosting 方法,则:
‘Resample’,‘on’指定使用更新的权重作为多项式采样概率来对训练观测值进行采样。
‘Resample’,‘off’(默认)指定在每次学习迭代时重新加权观测值。
如果Method是’bag’,那么’Resample’一定是’on’。FResample该软件会在有或没有替换的情况下对训练观测值的一部分(请参阅 )进行重新采样(请参阅Replace)。
如果您指定使用 重新采样Resample,那么最好对整个数据集重新采样。即,使用默认设置 1 FResample。
(8)LearnRate—收缩的学习率——1(默认)| (0,1] 中的数字标量
收缩的学习率,指定为逗号分隔的对组,由 'LearnRate’和 区间 (0,1] 中的数字标量组成。
例如,要使用收缩来训练集成,设置LearnRate为小于 的值是一种流行的选择。使用收缩来训练集成需要更多的学习迭代,但通常可以获得更好的准确性。
通常默认情况集成聚合算法是’LSBoost’。
由于集成聚合方法是一种增强算法,因此最多允许 10 个分裂的回归树组成集成。
一百棵树组成了这个整体。
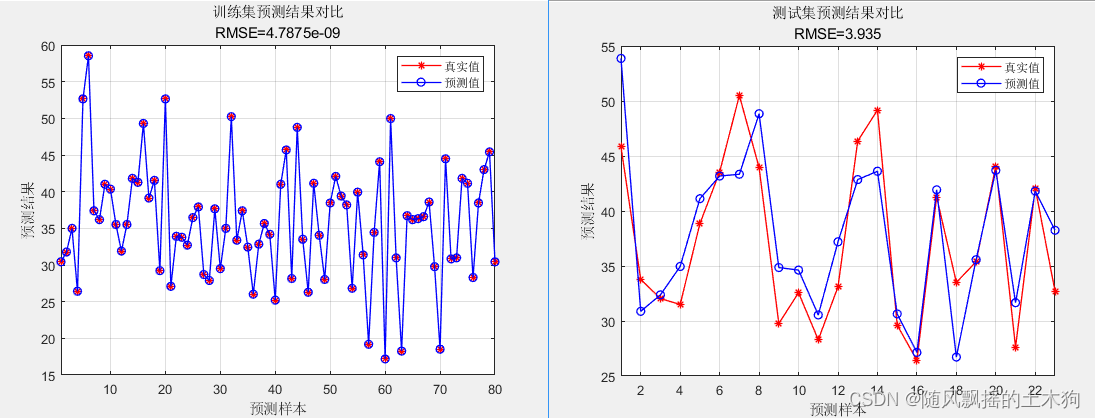
训练集数据的R2为:1
测试集数据的R2为:0.7032
训练集数据的MAE为:3.4726e-09
测试集数据的MAE为:3.112
训练集数据的MBE为:7.9936e-16
测试集数据的MBE为:0.77045
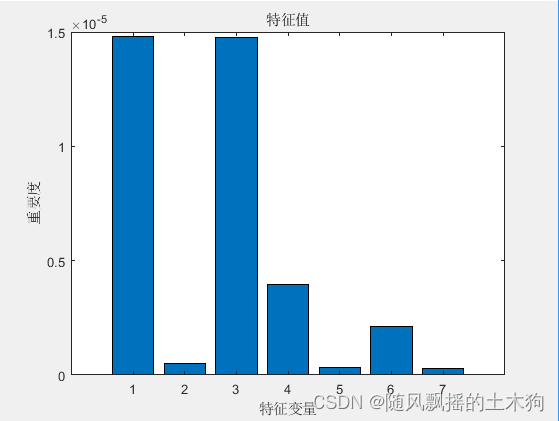
3、模型优化
一般来说搜索最佳参数步骤:
(1)交叉验证一组集成。将后续集成的树复杂度级别从决策树桩(一次拆分)指数级增加到最多n - 1 次拆分。n是样本量。此外,将每个集成的学习率在 0.1 到 1 之间变化。
(2)估计每个集合的交叉验证均方误差 (MSE)。
(3)对于树复杂度级别j,j = 1 。。。J,通过根据学习周期数绘制它们来比较集成的累积、交叉验证的 MSE。在同一张图上为每个学习率绘制单独的曲线。
(4)选择达到最小MSE的曲线,并记下相应的学习周期和学习率。
但也可以通过使用自动超参数优化来找到可最大限度减少五倍交叉验证损失的超参数。
OptimizeHyperparameters—要优化的参数
‘none’(默认)| ‘auto’| ‘all’| 合格参数名称的字符串数组或元胞数组| 对象向量optimizableVariable
要优化的参数,指定为逗号分隔的对组,其中包含’OptimizeHyperparameters’以下各项之一:
‘none’— 不优化。
‘auto’— {‘Method’,‘NumLearningCycles’,‘LearnRate’} 与指定的默认参数一起 使用Learners:
Learners= ‘tree’(默认)— {‘MinLeafSize’}
‘all’— 优化所有符合条件的参数。
常优化参数包括:
Method— 符合条件的方法是 'Bag’或 ‘LSBoost’。
NumLearningCycles— 在正整数中搜索,默认情况下以 range 为对数缩放 [10,500]。
LearnRate— 在正实数之间搜索,默认情况下以 range 为对数缩放 [1e-3,1]。
MinLeafSize— 在范围 内对数缩放的整数中进行搜索 [1,max(2,floor(NumObservations/2))]。
MaxNumSplits— 在范围 内对数缩放的整数中进行搜索 [1,max(2,NumObservations-1)]。
NumVariablesToSample— 在范围 内的整数中搜索[1,max(2,NumPredictors)]。
在此示例中,为了再现性,设置随机种子并使用’expected-improvement-plus’采集函数。此外,为了随机森林算法的可重复性,请指定树学习器的’Reproducible’名称-值对参数true。
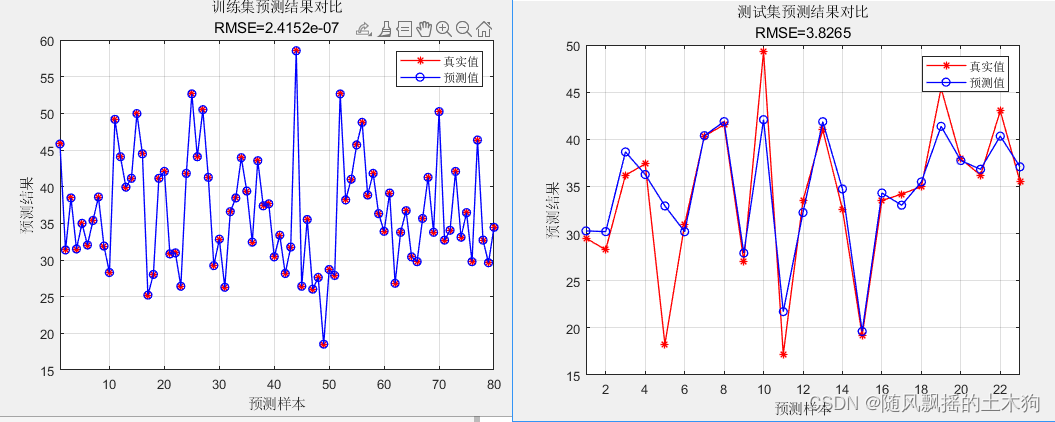
训练集数据的R2为:1
测试集数据的R2为:0.77452
训练集数据的MAE为:2.0746e-07
测试集数据的MAE为:2.2166
训练集数据的MBE为:6.7502e-15
测试集数据的MBE为:0.61126
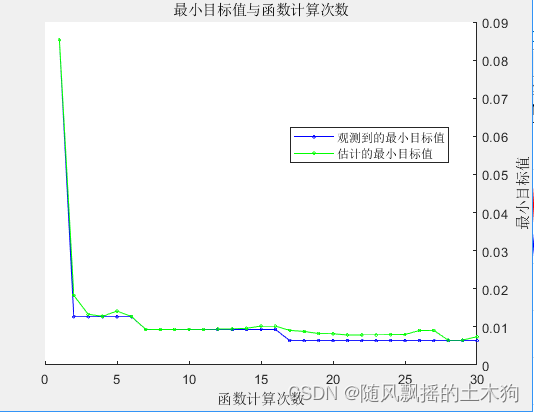
Method NumLearningCycles LearnRate MinLeafSize
_______ _________________ _________ ___________
LSBoost 500.00 0.07 8.00
二、Bag袋装决策树
Bag采用Bootstrap聚合(装袋,例如随机森林),在默认情况下,在每个分割(随机森林)中使用带有随机预测器选择的装袋。要在不进行随机选择的情况下使用装袋,请使用 ‘NumVariablesToSample’值为的树学习器’all’。
Bag与LSBoost原理大致相同,不多介绍。其中,Bag不含学习率参数,学习率为LSBoost特有参数。
其次,两者区别之一在于:
对于袋装决策树,决策分割的最大数量 ( ‘MaxNumSplits’) 为 n–1,其中n 是观测值的数量。为每个分割 ( ) 随机选择的预测变量数量’NumVariablesToSample’是预测变量数量的三分之一。所以,长出很深的决策树。可以种植较浅的树以减少模型复杂性或计算时间。
对于提升决策树, 'MaxNumSplits’是 10 , 'NumVariablesToSample’是 ‘all’。因此,生长浅决策树。可以种植更深的树以获得更高的准确性。
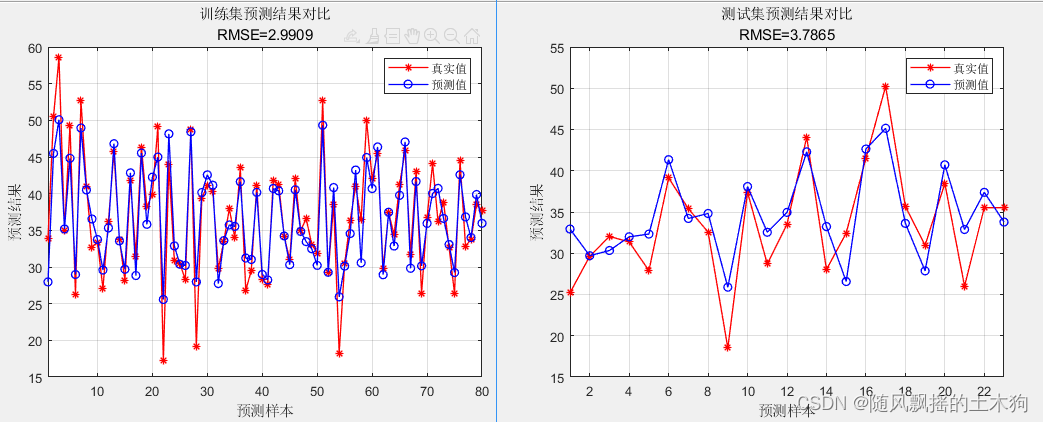
1、优化前运行结果:
训练集数据的R2为:0.85866
测试集数据的R2为:0.6728
训练集数据的MAE为:2.2035
测试集数据的MAE为:3.0626
训练集数据的MBE为:-0.097284
测试集数据的MBE为:1.1057
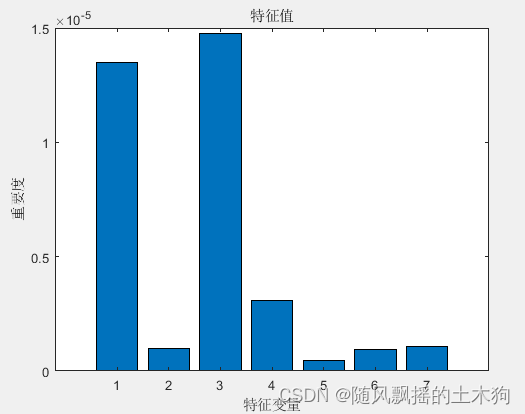
2、优化后运行结果:
估计的最佳可行点(根据模型):
NumLearningCycles MinLeafSize MaxNumSplits NumVariablesToSample
_________________ ___________ ____________ ____________________
11.00 2.00 11.00 6.00
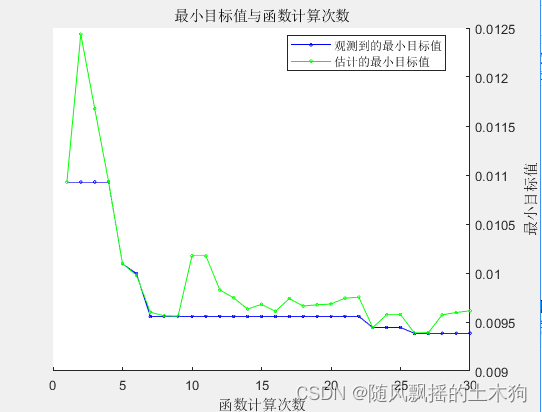
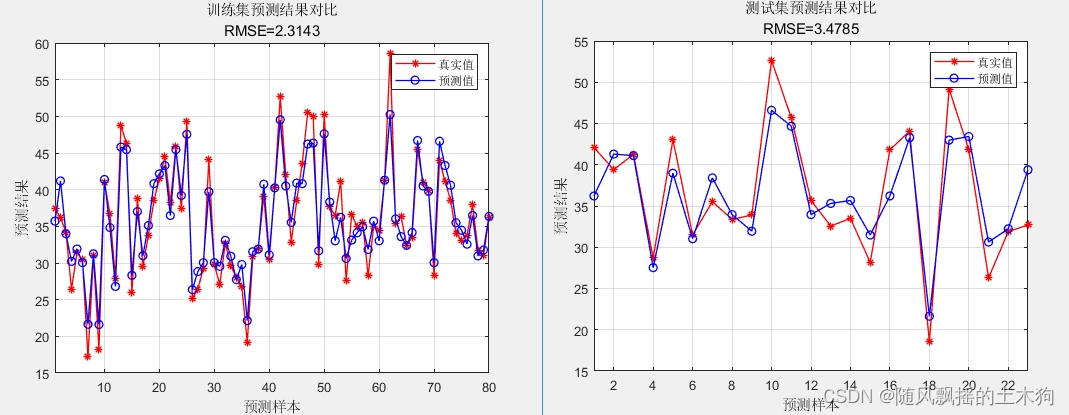
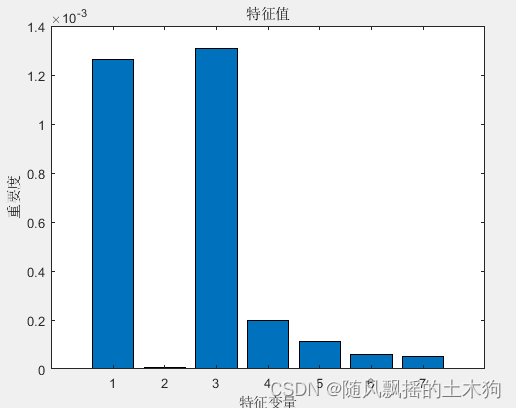
训练集数据的R2为:0.91202
测试集数据的R2为:0.79904
训练集数据的MAE为:1.7991
测试集数据的MAE为:2.8127
训练集数据的MBE为:0.080855
测试集数据的MBE为:-0.23307
三、代码获取
1.阅读首页置顶文章
2.关注CSDN
3.根据自动回复消息,回复“92期”以及相应指令,即可获取对应下载方式。
这篇关于【MATLAB第92期】基于MATLAB的集成聚合多输入单输出回归预测方法(LSBoost、Bag)含自动优化超参数和特征敏感性分析功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






