本文主要是介绍CC00031.elasticsearch——|HadoopElasticSearch.V31|——|ELK.v31|集群|QueryDSL|聚合分析.V2|,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、指标聚合:max min sum avg
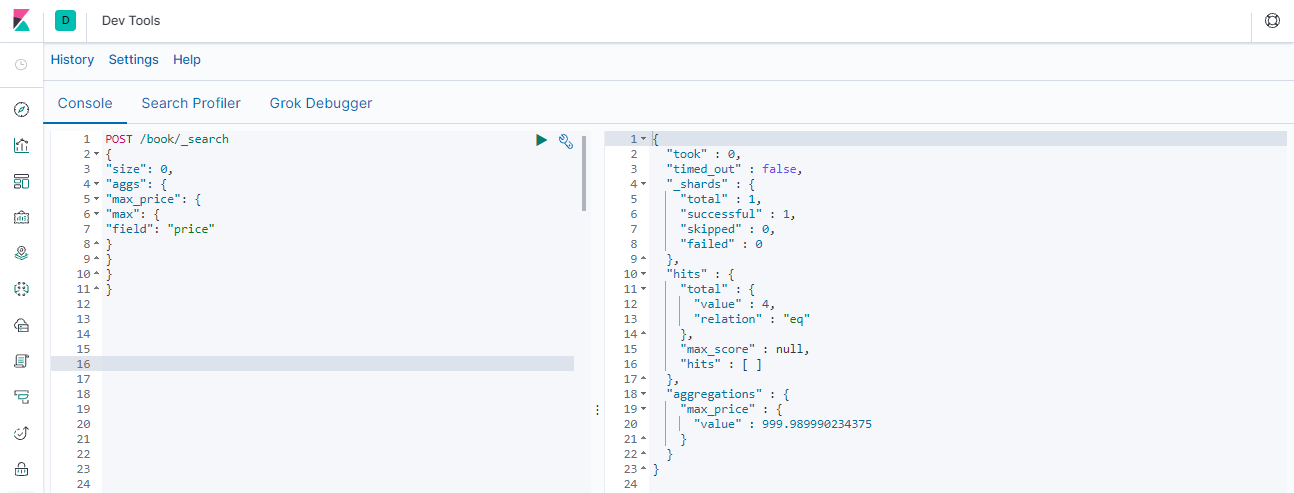
### --- 示例一:查询所有书中最贵的POST /book/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}
二、文档计数count
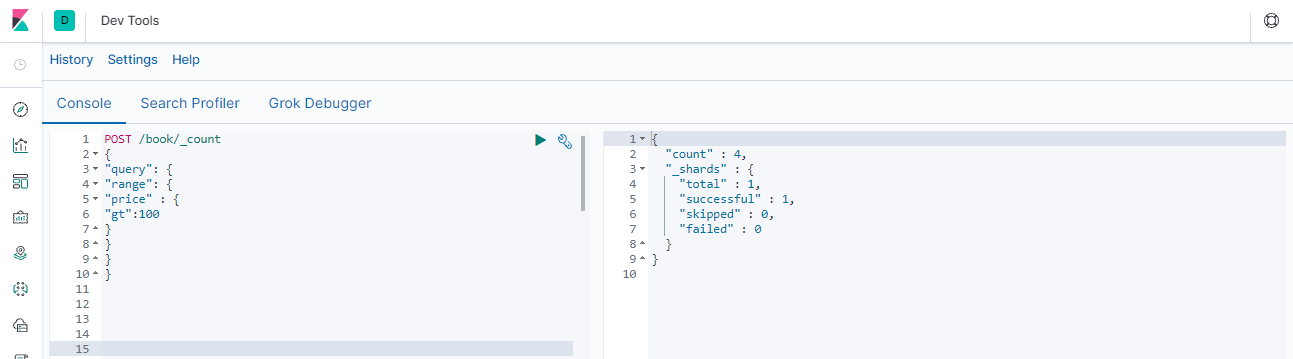
### --- 示例: 统计price大于100的文档数量POST /book/_count
{
"query": {
"range": {
"price" : {
"gt":100
}
}
}
}
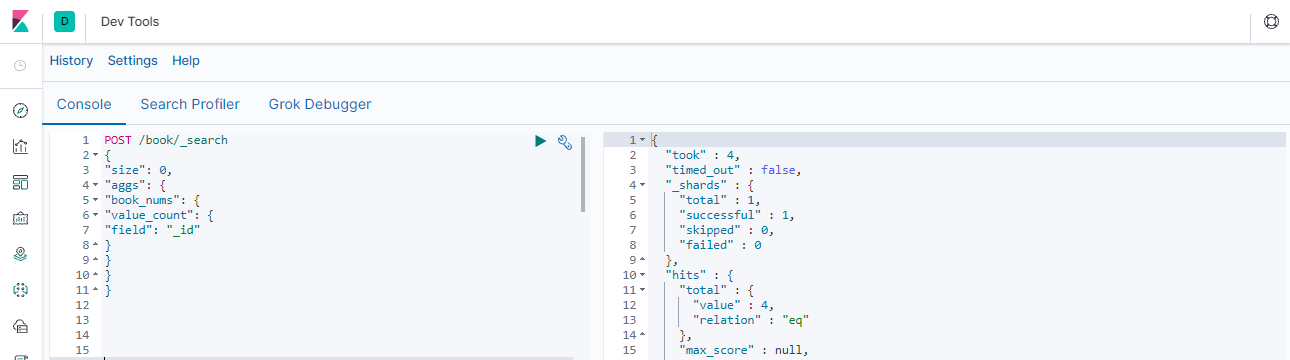
~~~ # 统计条数(value_count统计某个字段有值的数量)POST /book/_search
{
"size": 0,
"aggs": {
"book_nums": {
"value_count": {
"field": "_id"
}
}
}
}
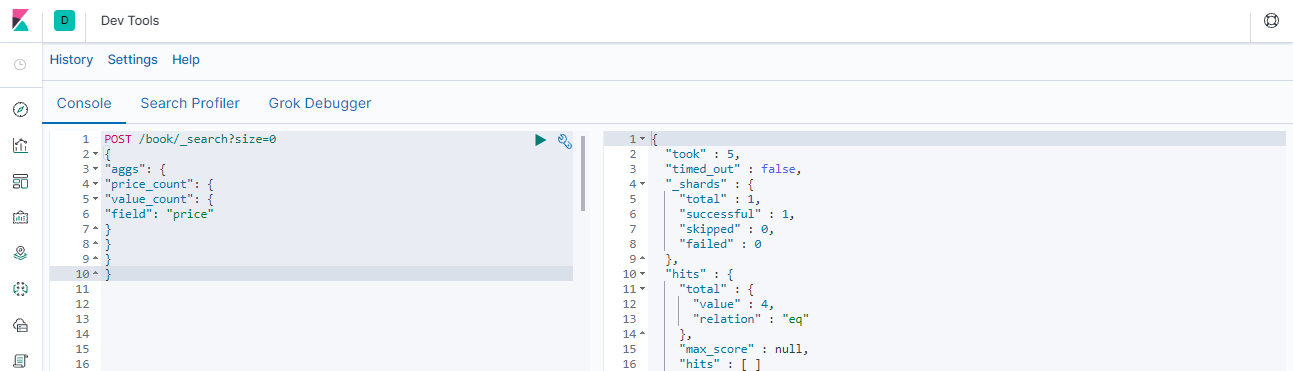
### --- value_count 统计某字段有值的文档数POST /book/_search?size=0
{
"aggs": {
"price_count": {
"value_count": {
"field": "price"
}
}
}
}
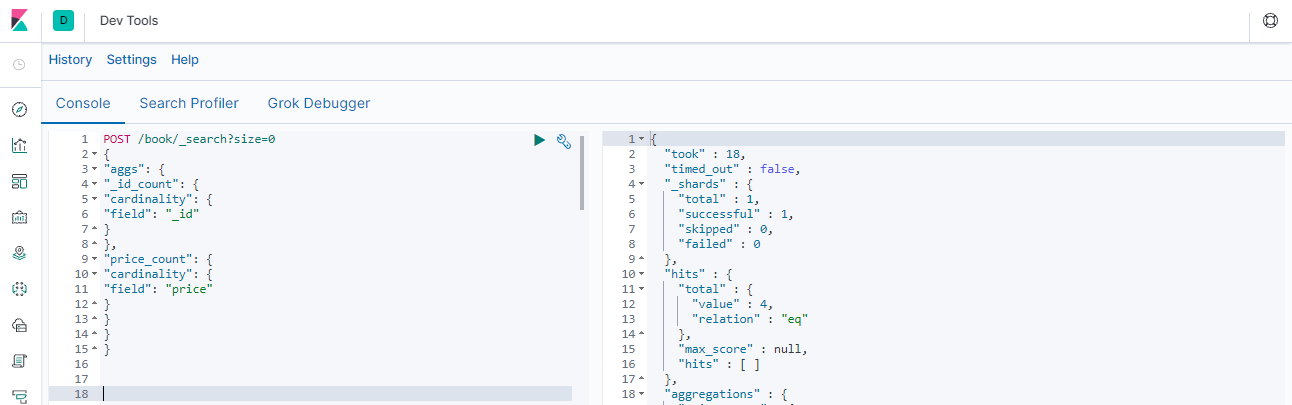
### --- cardinality值去重计数 基数POST /book/_search?size=0
{
"aggs": {
"_id_count": {
"cardinality": {
"field": "_id"
}
},
"price_count": {
"cardinality": {
"field": "price"
}
}
}
}
### --- stats 统计 count max min avg sum 5个值POST /book/_search?size=0
{
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}
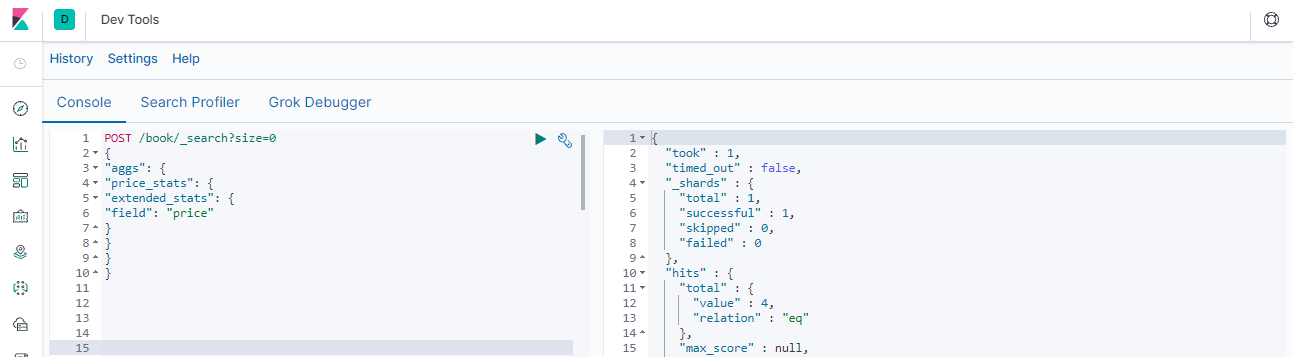
### --- Extended stats:高级统计,
~~~ 比stats多4个统计结果: 平方和、方差、标准差、平均值加/减两个标准差的区间POST /book/_search?size=0
{
"aggs": {
"price_stats": {
"extended_stats": {
"field": "price"
}
}
}
}
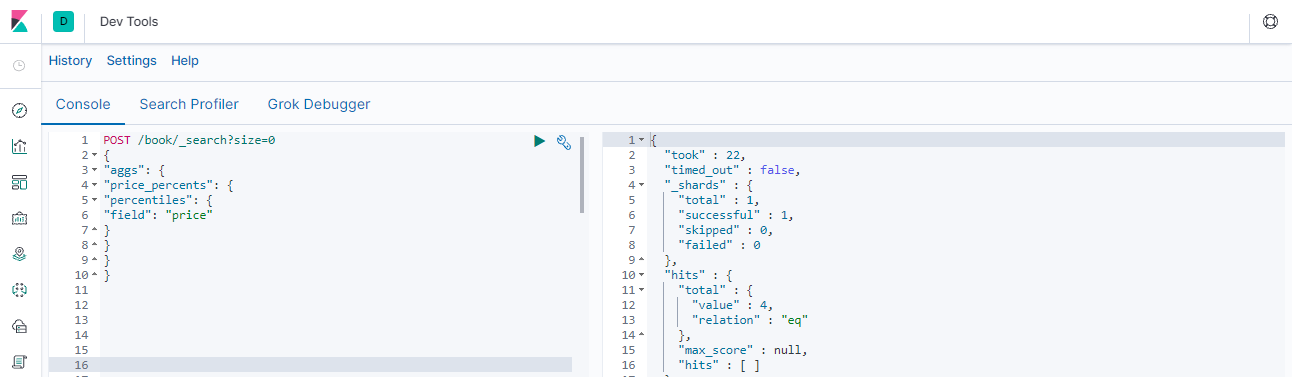
### --- Percentiles 占比百分位对应的值统计POST /book/_search?size=0
{
"aggs": {
"price_percents": {
"percentiles": {
"field": "price"
}
}
}
}
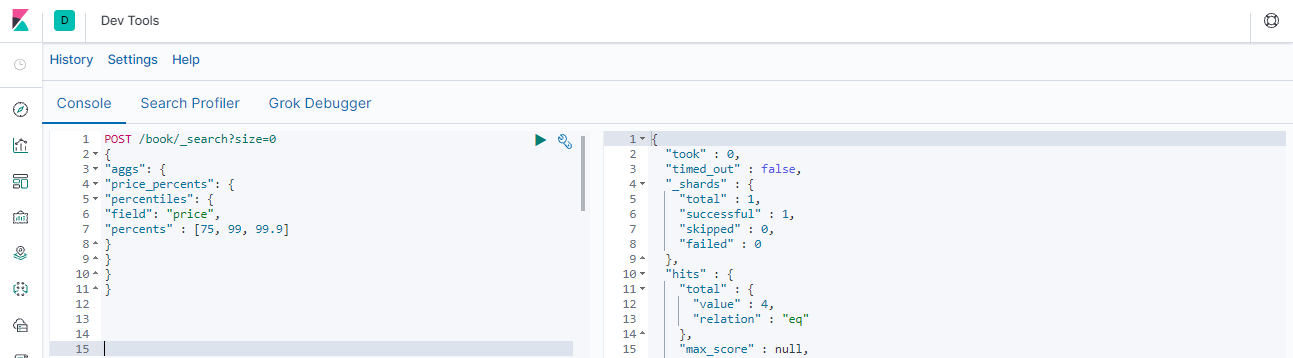
### --- 指定分位值POST /book/_search?size=0
{
"aggs": {
"price_percents": {
"percentiles": {
"field": "price",
"percents" : [75, 99, 99.9]
}
}
}
}
### --- Percentiles rank 统计值小于等于指定值的文档占比
~~~ 统计price小于100和200的文档的占比POST /book/_search?size=0
{
"aggs": {
"gge_perc_rank": {
"percentile_ranks": {
"field": "price",
"values": [
100,200
]
}
}
}
}
这篇关于CC00031.elasticsearch——|HadoopElasticSearch.V31|——|ELK.v31|集群|QueryDSL|聚合分析.V2|的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





