本文主要是介绍Sequential model should have a single output tensor. For multi-output layers,use the functional API.,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这个错误的原因在于不知道啥叫序列化模型,keras的模型都是序列化堆叠的模型,如果你觉得不好用,你可以直接用tf的函数构建,不要嫌弃keras,人家本来就是高级API,你想知道更多,你用低级的API呗
非要用LSTM中的状态也可以,先了解下参数,啥都不了解就不要轻易下结论,不被人笑死??
input_data = tf.keras.layers.Input(shape=(12,3))
hidden_1, state_h, state_c = tf.keras.layers.LSTM(units=16, return_state=True, return_sequences=True)(input_data,)
hidden_2 = tf.keras.layers.LSTM(units=16, )(hidden_1, initial_state=[state_h, state_c])#, training=True
hidden_3 = tf.keras.layers.Dense(10, activation='relu')(hidden_2)
output = tf.keras.layers.Dense(1, activation='sigmoid')(hidden_3)
model = tf.keras.models.Model(inputs=input_data, outputs=output)这不就是状态的应用吗?注意:第2个units与第一个保持一致,否则出错。
但绝大多数都有一个疑问,为啥很多序列化模型根本不要这种状态的复用(作为下一层的输入)?
这是因为红字,如果不一致的话,其实这种状态的输入shape是不对的,下面小明哥举例说明,证实无论是否有状态的输入都是有效的,因为隐层的结果保留了,而状态值真的发挥作用了吗??以MNIST数据为例说明,(随时复盘,保持低调)
【我蒙蔽了,没GPU电脑70s,服务器100多s,,,什么鬼】
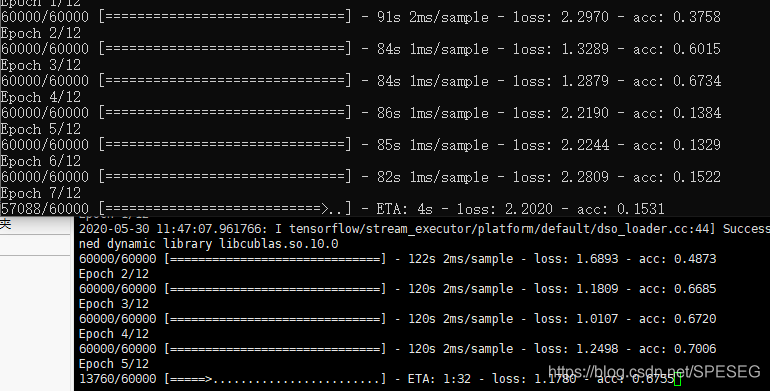
另外也没有收敛的迹象,因此可以断定,网络参数不对。
凡是第一层网络达不到acc0.2的都不对,如果units不太大,如32,16,一个epoch不可能1分钟,参数还是不对。
另外训练时,acc逐渐变小,参数仍是不对。这是显然的。所以尽量训练多次,看看是不是acc逐渐增加。如下这种就是不对。
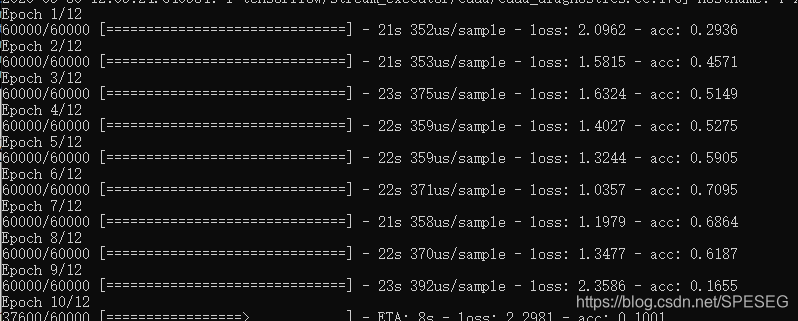
在上面代码的修改下我是无论如何也调不好的,状态作为输入真不好调,我还是尝试LSTMCell这种进行尝试
loss减小,acc也减小的也是错。
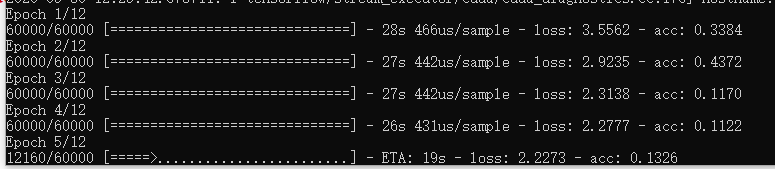
针对上面的奇怪现象老子搜了发现,最后一层的激活函数错了,不该用relu,这特么。。。改后如下
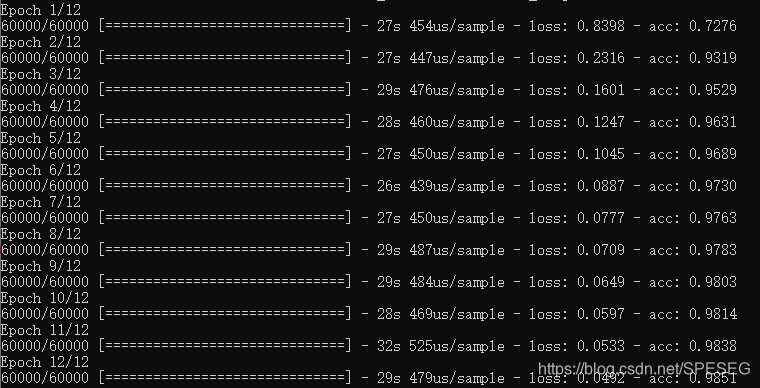
下面再次尝试将状态输入,发现需要训练的参数并没有减少,而是一样的,训练速度(收敛)也没有加快。网络对比


结果对比

请问状态值在这里面有用吗?是我参数还没设置正确,还没达到效果,抑或是因为图像里面的确没有什么用?我暂时也找不到好的语音分类的mnist,不评价
如果想用LSTMCell,请堆叠至少两层相同Cell,否则容易出错。模型参数是一样的,如下(训练结果也是一样的)
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28)] 0
_________________________________________________________________
rnn (RNN) (None, 32) 16128
_________________________________________________________________
dense (Dense) (None, 10) 330
=================================================================
Total params: 16,458
Trainable params: 16,458
Non-trainable params: 0这里深究下,里面状态是否作为下个Cell的输入?如下推断是否是正确的,暂时认为正确吧
>>> Cell=tf.keras.layers.LSTMCell(units=32,)
>>> Cell(input_data)
Traceback (most recent call last):File "<pyshell#165>", line 1, in <module>Cell(input_data)File "D:\python\lib\site-packages\tensorflow_core\python\keras\engine\base_layer.py", line 854, in __call__outputs = call_fn(cast_inputs, *args, **kwargs)
TypeError: call() missing 1 required positional argument: 'states'单层的Cell是需要states状态值的,说明里面的状态是作为下层的输入的,
综上,LSTM不需要考虑状态啥的,直接keras序列化模型即可,如有疑问,请给出过程和结果,为保持一致,数据提供如下:
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data(path='mnist.npz')
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train.astype(np.float32)
x_test = x_test.astype(np.float32)没有代码的交流都是扯淡,毫无意义!
Talk is cheap,show me the codes
For Video Recommendation in Deep learning QQ Group 277356808
For Speech, Image, Video in deep learning QQ Group 868373192
I'm here waiting for you
这篇关于Sequential model should have a single output tensor. For multi-output layers,use the functional API.的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






