本文主要是介绍智能风控体系之divergence评分卡简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
评分卡模型的出现据说最早是在20世纪40年代,Household Finance and Spiegel和芝加哥邮购公司第一次尝试在贷款决策过程中使用信用评分.但是这两家公司都终止了这项业务。后来,在20世纪50年代末,伊利诺伊州的美国投资公司(AIC)聘请两位数学家比尔·法尔(Bill Fair)和厄尔·艾萨克 (Earl Isaac)通过审查一个小型贷款样本(其中一些支付信用良好,其中一些较差)来确认是否可以获得可用的数据模型。我们通常见到的银行内的风险模型通常是基于逻辑回归开发的,在美国开发的fico score是基于divergence算法开发。
▍FICO最大化分离度(Divergence)评分模型开发
采用了FICO Model Builder专利的最大化分离度(Divergence)算法去开发评分模型,通常除了分析每个变量的IV之外,还需要分析/检查每个变量的MC(Marginal Contribution-边际贡献度)。按照费埃哲的60年的经验般变量的MC小于0.001会不予考虑选为模型变量,同时比较每个变量选入和选出模型对应总体模型表现(好坏区分度Divergence)的影响,最终选出最优的变量组合,形成评分模型。
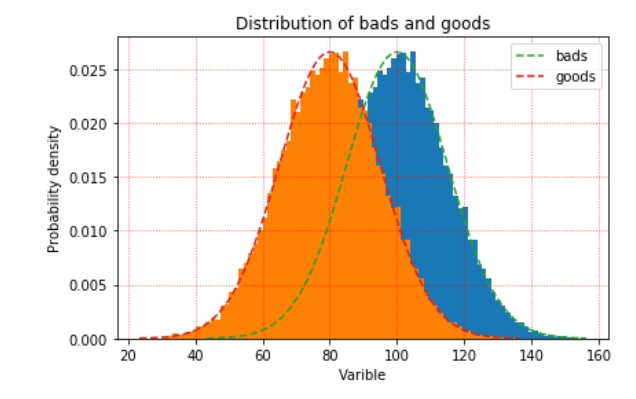
最大分离度算法假设好用户的评分和坏用户的评分服从两个不同的正态分布,然后最大化两个分布的差异。这个假设和优化目标都非常直观且符合逻辑。正常的建模完成后,好用户和坏用户的评分基本都长下图的样子,两个分布越是分离的远,模型ks值越高。
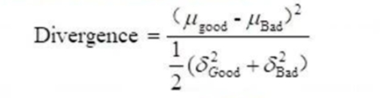
u:数学期望或均值,是最有可能出现的结果。
σ2:方差,数据的分散程度。


▍从样本距离看区分度-好坏客户的距离
在机器学习模型和统计学模型中,"距离”是频繁使用的度量之一,用以衡量单个样本或者样本集的差异。同样的,在评分模型中我们也可以计算好坏样本的距离来检验分数的区分度。Divergence越大,两类样本的距离越大,好坏样本差异越大:
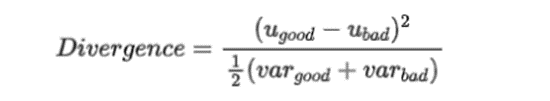
ugood和ubad分别表示好坏样本的评分均值,vargood和varbad分别表示好坏样本的评分的方差。注意:a.Divergence与好坏样本的比例无关。当对好坏样本进行抽样处理后,不会显著影响Divergence的值;b.当好坏样本的分数分布比较接近正态分布时,Divergence最能真实刻画区分度;c.Divergence没有参照的阈值。可以用来比较不同模型在同一样本上的表现,或者同一模型在不同样本上的表现。
如果两个分布的重叠部分越小,代表正负样本的差异性越大,自变量就能更好的将正负样本区分开来。
这篇关于智能风控体系之divergence评分卡简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








