本文主要是介绍基于蝗虫优化的KNN分类特征选择算法的matlab仿真,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.程序功能描述
2.测试软件版本以及运行结果展示
3.核心程序
4.本算法原理
4.1 KNN分类器基本原理
4.2 特征选择的重要性
4.3 蝗虫优化算法(GOA)
5.完整程序
1.程序功能描述
基于蝗虫优化的KNN分类特征选择算法。使用蝗虫优化算法,选择最佳的特征,进行KNN分类,从而提高KNN分类的精度。
2.测试软件版本以及运行结果展示
MATLAB2022a版本运行


3.核心程序
..........................................................
[idx1,~,idx2]= dividerand(rows,0.8,0,0.2);
Ptrain = PP(idx1,:); %training data
Ptest = PP(idx2,:); %testing data
Ttrain = TT(idx1); %training TT
Ttest = TT(idx2); %testing TT
%KNN
idx_m = fitcknn(Ptrain,Ttrain,'NumNeighbors',5,'Standardize',1);
Tknn = predict(idx_m,Ptest);
cp = classperf(Ttest,Tknn);
err = cp.ErrorRate;
accuracy1 = cp.CorrectRate;dim=size(PP,2);
lb=0;
ub=1;%GOA优化过程
Pnum = 50; %种群个数
iteration = 100; %迭代次数
[~,Target_pos,ybest]= func_GOA(Pnum,iteration,lb,ub,dim,Ptrain,Ptest,Ttrain,Ttest);[~,accuracy2,~] = func_Eval(Target_pos,Ptrain,Ptest,Ttrain,Ttest); figure;
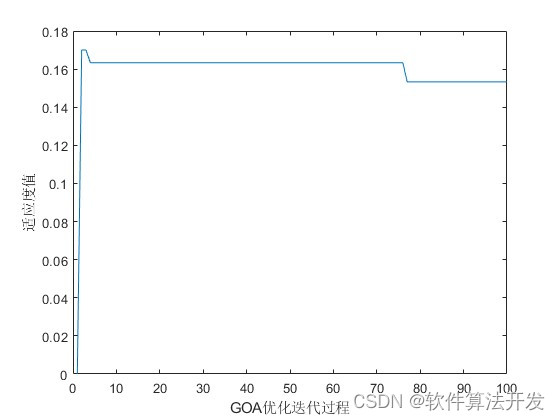
plot(ybest);
xlabel('GOA优化迭代过程')
ylabel('适应度值' )figure
bar([accuracy1,accuracy2])
xlabel('1.Predicted by All featrure, 2.Predcited by GOA select featrure')
ylabel('accuracy' )figure
bar([size(Ptest,2),numel(find(Target_pos))])
title('特征选择个数')
xlabel('1.Total Features, 2.Features after GOA Selection');
22 4.本算法原理
基于蝗虫优化的KNN(K-最近邻)分类特征选择是一种结合了蝗虫优化算法(Grasshopper Optimization Algorithm, GOA)和KNN分类器的特征选择方法。该方法旨在通过蝗虫优化算法选择最优特征子集,从而提高KNN分类器的分类性能。
4.1 KNN分类器基本原理
何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:分析一个人时,我们不妨观察和他最亲密的几个人。同理的,在判定一个未知事物时,可以观察离它最近的几个样本,这就是KNN(k最近邻)的方法。简单来说,KNN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑出离这个数据最近的K个点,看看这K个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
KNN分类器是一种基于实例的学习算法,其工作原理是找到一个新数据点在训练数据集中的K个最近邻居,并根据这些邻居的类别来进行投票,从而确定新数据点的类别。
①初始化距离为最大值;
②计算未知样本和每个训练样本的距离dist;
③得到目前K个最临近样本中的最大距离maxdist;
④如果dist小于maxdist,则将该训练样本作为K-最近邻样本;
⑤重复步骤2、3、4.直到所有未知样本和所有训练样本的距离都算完;
⑥统计K-最近邻样本中每个类标号出现的次数;
⑦选择出现频率最大的类标作为未知样本的类标号。
4.2 特征选择的重要性
在实际应用中,数据集往往包含许多特征,但并不是所有特征都对分类任务有用。冗余和不相关的特征可能会降低分类器的性能,增加计算复杂度。因此,特征选择是一个重要的预处理步骤,它旨在从原始特征集中选择出最有代表性的特征子集。
4.3 蝗虫优化算法(GOA)
蝗虫优化算法是一种模拟蝗虫群体行为的优化算法。在GOA中,每个蝗虫代表一个解(即一个特征子集),蝗虫的位置通过模拟蝗虫群体的社会交互和自适应行为进行更新。
在基于蝗虫优化的KNN分类特征选择中,蝗虫的位置代表一个特征子集,适应度函数通常定义为KNN分类器在验证集上的分类准确率。算法的基本步骤如下:
- 初始化蝗虫群体的位置(即特征子集)。
- 计算每个蝗虫的适应度值(即KNN分类器的分类准确率)。
- 根据适应度值更新蝗虫的位置。
- 如果满足停止条件(如达到最大迭代次数或解的质量满足要求),则停止算法;否则,转到步骤2。
最终,算法将返回具有最高适应度值的蝗虫的位置,即最优特征子集。
5.完整程序
VVV
这篇关于基于蝗虫优化的KNN分类特征选择算法的matlab仿真的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






