本文主要是介绍本地化部署大模型方案二:fastchat+llm(vllm),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 引言
- 一、上一节内容
- 二、FastChat 介绍
- 三、FastChat 实战
- 3.1支持模型
- 3.2 准备环境(这里我准备了一个autodl的新服务器)
- 3.3 安装魔搭环境,下载大模型
- 3.4 安装并使用FastChat
- 3.4.1 安装FastChat
- 3.4.2 使用FastChat
- 第一步启动controller
- 第二步启动model_worker(llm)
- 第二步代替方案(vllm)
- 第三步openai服务启动
- 第四步验证
引言
本次是对上一节内容的补充,因为有的大模型是没有提供openai的类似api接口项目,只孤零零的提供了一个模型,所以通过上一节的部署方式是行不通的。为了解决这个问题使用了FastChat项目。多说一句话网上比较成熟的Langchain-Chatchat项目也是基于FastChat对接的大模型,大家有兴趣可以看看。后面有机会我专门来聊一下这个项目。
一、上一节内容
LangChain学习一:入门-本地化部署-接入大模型
http://t.csdnimg.cn/zS1sR
二、FastChat 介绍
FastChat 是一个开放平台,用于训练、服务和评估基于大型语言模型的聊天机器人。
- FastChat 为 Chatbot Arena ( https://chat.lmsys.org/ ) 提供支持,为 50 多名法学硕士提供超过 600 万个聊天请求。
- Arena 从并列的 LLM 比赛中收集了超过 10 万个人投票,编制了在线LLM Elo 排行榜。
FastChat 的核心功能包括:
- 最先进模型的训练和评估代码(例如,Vicuna、MT-Bench)。
- 具有 Web UI 和 OpenAI 兼容 RESTful API 的分布式多模型服务系统。
三、FastChat 实战
这个巨坑要看好哈------->选择cuda 至少要11.8 以上的版本
3.1支持模型
FastChat所支持的大模型
3.2 准备环境(这里我准备了一个autodl的新服务器)

3.3 安装魔搭环境,下载大模型
apt update
pip3 install -U modelscope
# 对于中国的用户,您可以使用以下命令进行安装:
# pip3 install -U modelscope -i https://mirror.sjtu.edu.cn/pypi/web/simple
这里用百川13B模型为例
from modelscope.hub.snapshot_download import snapshot_downloadlocal_dir_root = "/root/autodl-tmp/models_from_modelscope"
snapshot_download('baichuan-inc/Baichuan2-13B-Chat', cache_dir=local_dir_root)
命名为load.py,执行
python load.py

3.4 安装并使用FastChat
AutoDL平台有代理加速
source /etc/network_turbo
3.4.1 安装FastChat
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip install .
3.4.2 使用FastChat
一共要启动三个服务分别是controller、model_worker(vllm 使用vllm_worker)、openai_api_server
- vllm 加快推理速度:就是快点给出问题的答案
pip install vllm
第一步启动controller
python -m fastchat.serve.controller --host 0.0.0.0
其他参数
--host参数指定应用程序绑定的主机名或IP地址。默认情况下,应用程序将绑定在本地回环地址(即localhost或127.0.0.1)上。
--port参数指定应用程序监听的端口号。默认情况下,应用程序将监听21001端口。
--dispatch-method参数指定请求调度算法。lottery表示抽奖式随机分配请求,shortest_queue表示将请求分配给队列最短的服务器。默认情况下,使用抽奖式随机分配请求。
--ssl参数指示应用程序是否使用SSL加密协议。如果指定了此参数,则应用程序将使用HTTPS协议。否则,应用程序将使用HTTP协议。
第二步启动model_worker(llm)
打开另个终端,启动,这里会报一个错,需要安装一下相关的包
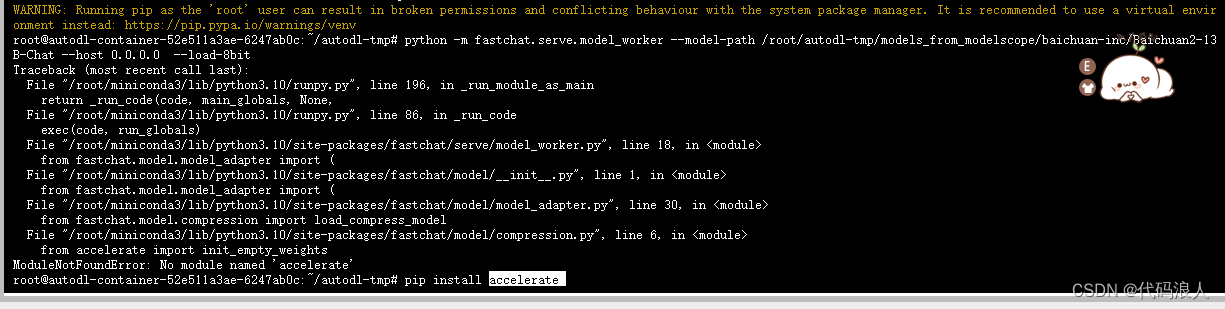
pip install accelerate
然后启动
python -m fastchat.serve.model_worker --model-path /root/autodl-tmp/models_from_modelscope/baichuan-inc/Baichuan2-13B-Chat --host 0.0.0.0 --load-8bit
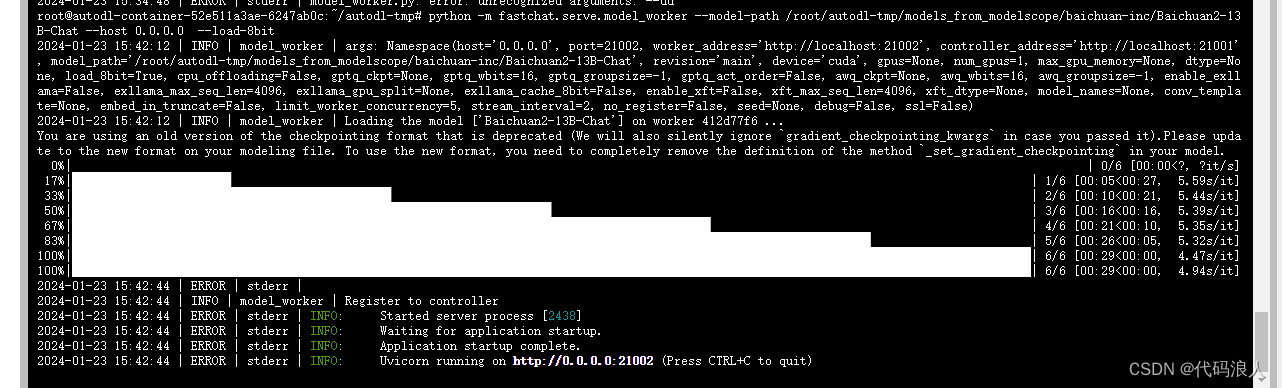
其他参数
--host:指定模型工作进程绑定的主机名或IP地址。--port:指定模型工作进程绑定的端口号。--worker-address:指定模型工作进程的地址。--controller-address:指定模型控制器的地址。--model-path:指定要加载的模型文件的路径。--revision:指定模型文件的版本。--device:指定模型运行的设备类型,可以是CPU、GPU等。--gpus:指定用于模型运行的GPU设备的数量。--num-gpus:指定用于模型运行的GPU设备的数量。--max-gpu-memory:指定用于模型运行的GPU设备的最大内存限制。--dtype:指定模型的数据类型,可以是float32、float16等。--load-8bit:启用8位量化模型。--cpu-offloading:启用CPU卸载。--gptq-ckpt:指定GPTQ检查点的路径。--gptq-wbits:指定GPTQ权重的位数。--gptq-groupsize:指定GPTQ分组大小。--awq-ckpt:指定AWQ检查点的路径。--awq-wbits:指定AWQ权重的位数。--awq-groupsize:指定AWQ分组大小。--enable-exllama:启用Exllama。--exllama-max-seq-len:指定Exllama的最大序列长度。--exllama-gpu-split:指定Exllama的GPU划分。--exllama-cache-8bit:启用Exllama的8位缓存。--enable-xft:启用XFT。--xft-max-seq-len:指定XFT的最大序列长度。--xft-dtype:指定XFT的数据类型。--model-names:指定要加载的模型文件的名称。--conv-template:指定卷积模板的路径。--embed-in-truncate:启用嵌入截断。--limit-worker-concurrency:限制工作进程并发性的数量。--stream-interval:指定流间隔。--no-register:不注册模型。--seed:指定随机种子。--debug:启用调试模式。--ssl:启用SSL。
第二步代替方案(vllm)
python -m fastchat.serve.vllm_worker --model-path /root/autodl-tmp/models_from_modelscope/baichuan-inc/Baichuan2-13B-Chat --host 0.0.0.0

--host HOST:指定该工作节点的主机名或 IP 地址,默认为 localhost。
--port PORT:指定该工作节点监听的端口号,默认为 8000。
--worker-address WORKER_ADDRESS:指定该工作节点的地址。如果未指定,则自动从网络配置中获取。
--controller-address CONTROLLER_ADDRESS:指定控制节点的地址。如果未指定,则自动从环境变量中获取。如果环境变量也未设置,则默认使用 http://localhost:8001。
--model-path MODEL_PATH:指定模型文件的路径。如果未指定,则默认使用 models/model.ckpt。
--model-names MODEL_NAMES:指定要加载的模型名称。该参数只在多模型情况下才需要使用。
--limit-worker-concurrency LIMIT_WORKER_CONCURRENCY:指定最大并发工作进程数。默认为 None,表示不限制。
--no-register:禁止在控制节点上注册该工作节点。
--num-gpus NUM_GPUS:指定使用的 GPU 数量。默认为 1。
--conv-template CONV_TEMPLATE:指定对话生成的模板文件路径。如果未指定,则默认使用 conversation_template.json。
--trust_remote_code:启用远程代码信任模式。
--gpu_memory_utilization GPU_MEMORY_UTILIZATION:指定 GPU 内存使用率,范围为 [0,1]。默认为 1.0,表示占用全部 GPU 内存。
--model MODEL:指定要加载的模型类型。默认为 fastchat.serve.vllm_worker.VLLMModel。
--tokenizer TOKENIZER:指定要使用的分词器类型。默认为 huggingface。
--revision REVISION:指定加载的模型版本号。默认为 None,表示加载最新版本。
--tokenizer-revision TOKENIZER_REVISION:指定加载的分词器版本号。默认为 None,表示加载最新版本。
--tokenizer-mode {auto,slow}:指定分词器模式。默认为 auto,表示自动选择最佳模式。
--download-dir DOWNLOAD_DIR:指定模型下载目录。默认为 downloads/。
--load-format {auto,pt,safetensors,npcache,dummy}:指定模型加载格式。默认为 auto,表示自动选择最佳格式。
--dtype {auto,half,float16,bfloat16,float,float32}:指定模型数据类型。默认为 auto,表示自动选择最佳类型。
--max-model-len MAX_MODEL_LEN:指定模型的最大长度。默认为 None,表示不限制。
--worker-use-ray:启用 Ray 分布式训练模式。
--pipeline-parallel-size PIPELINE_PARALLEL_SIZE:指定管道并行的大小。默认为 None,表示不使用管道并行。
--tensor-parallel-size TENSOR_PARALLEL_SIZE:指定张量并行的大小。默认为 None,表示不使用张量并行。
--max-parallel-loading-workers MAX_PARALLEL_LOADING_WORKERS:指定最大并发加载工作数。默认为 4。
--block-size {8,16,32}:指定块大小。默认为 16。
--seed SEED:指定随机种子。默认为 None。
--swap-space SWAP_SPACE:指定交换空间的大小。默认为 4GB。
--max-num-batched-tokens MAX_NUM_BATCHED_TOKENS:指定每个批次的最大令牌数。默认为 2048。
--max-num-seqs MAX_NUM_SEQS:指定每个批次的最大序列数。默认为 64。
--max-paddings MAX_PADDINGS:指定每个批次的最大填充数。默认为 1024。
--disable-log-stats:禁止记录统计信息。
--quantization {awq,gptq,squeezellm,None}:指定模型量化类型。默认为 None,表示不进行量化。
--enforce-eager:强制启用 Eager Execution 模式。
--max-context-len-to-capture MAX_CONTEXT_LEN_TO_CAPTURE:指定要捕获的上下文长度。默认为 1024。
--engine-use-ray:在引擎中启用 Ray 分布式训练模式。
--disable-log-requests:禁止记录请求信息。
--max-log-len MAX_LOG_LEN:指定最大日志长度。默认为 10240。
第三步openai服务启动
另起一个终端
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 8000
第四步验证
安装环境
pip install langchain
pip install openai
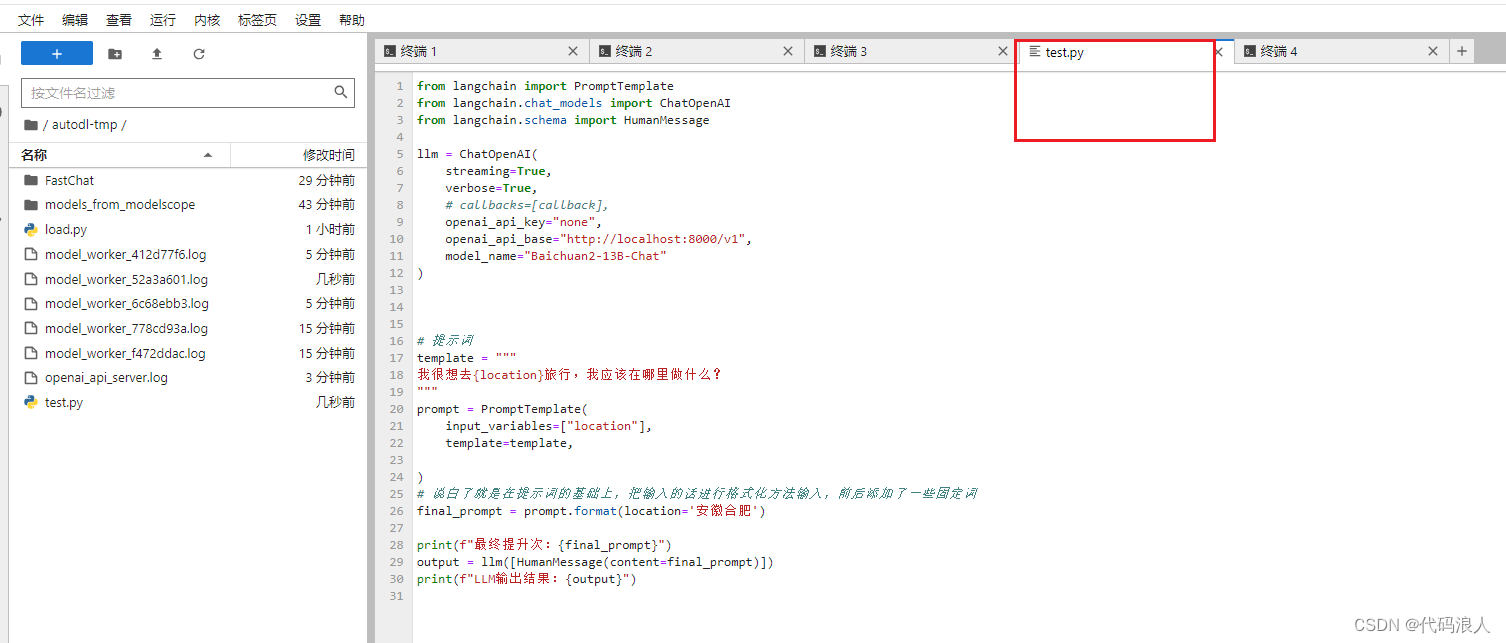
from langchain import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessagellm = ChatOpenAI(streaming=True,verbose=True,# callbacks=[callback],openai_api_key="none",openai_api_base="http://localhost:8000/v1",model_name="Baichuan2-13B-Chat"
)# 提示词
template = """
我很想去{location}旅行,我应该在哪里做什么?
"""
prompt = PromptTemplate(input_variables=["location"],template=template,)
# 说白了就是在提示词的基础上,把输入的话进行格式化方法输入,前后添加了一些固定词
final_prompt = prompt.format(location='安徽合肥')print(f"最终提升次:{final_prompt}")
output = llm([HumanMessage(content=final_prompt)])
print(f"LLM输出结果:{output}")启动
python test.py
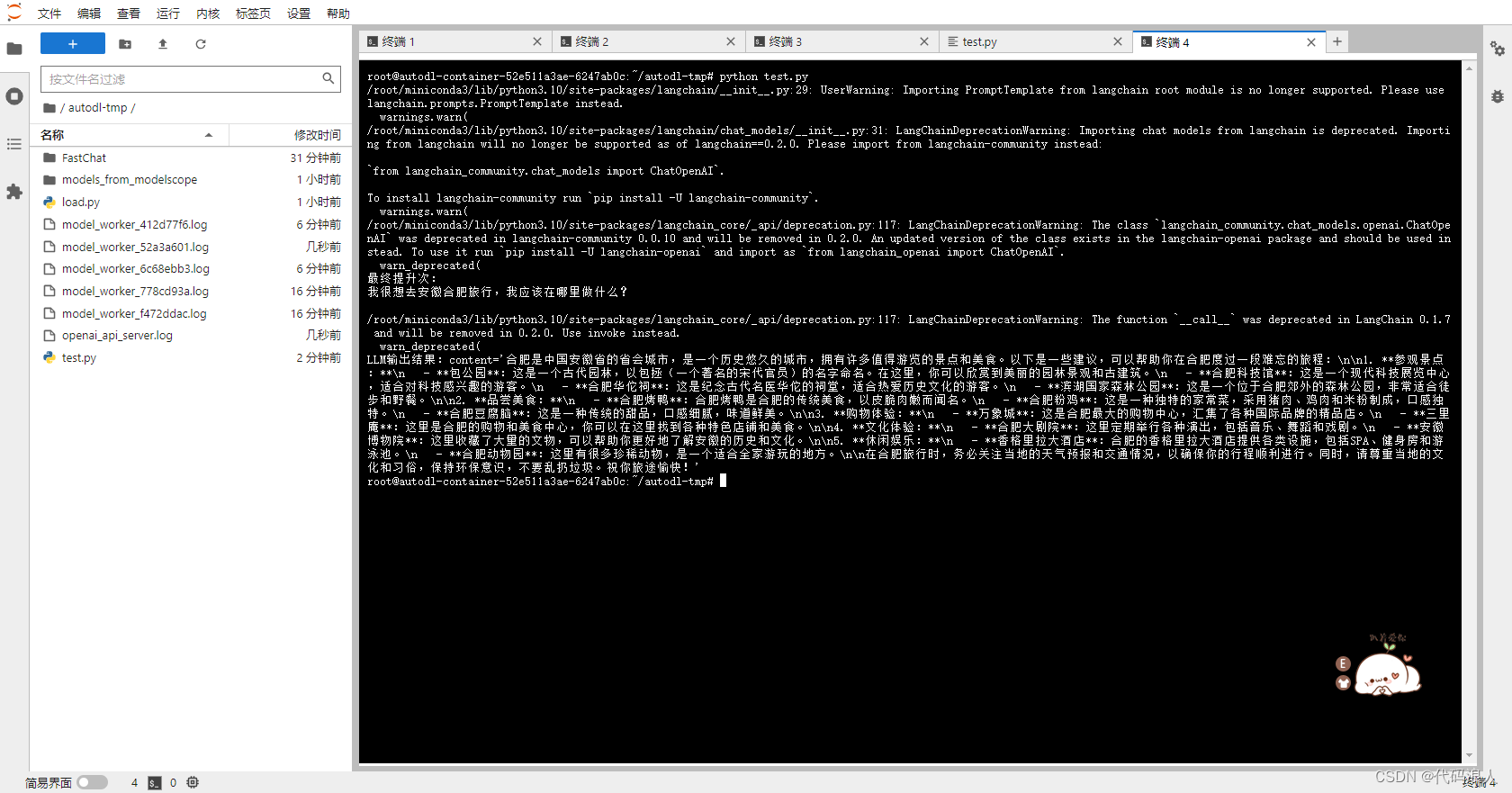
完结撒花
这篇关于本地化部署大模型方案二:fastchat+llm(vllm)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








