fastchat专题
![LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架]](https://img-blog.csdnimg.cn/img_convert/b10128f1222cfef40c49ec90fbdfded4.png)
LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架]
LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架] 训练后的模型会用于推理或者部署。推理即使用模型用输入获得输出的过程,部署是将模型发布到恒定运行的环境中推理的过程。一般来说,LLM的推理可以直接使用PyTorch代码、使用VLLM/XInference/FastChat等框架,也可以使用l
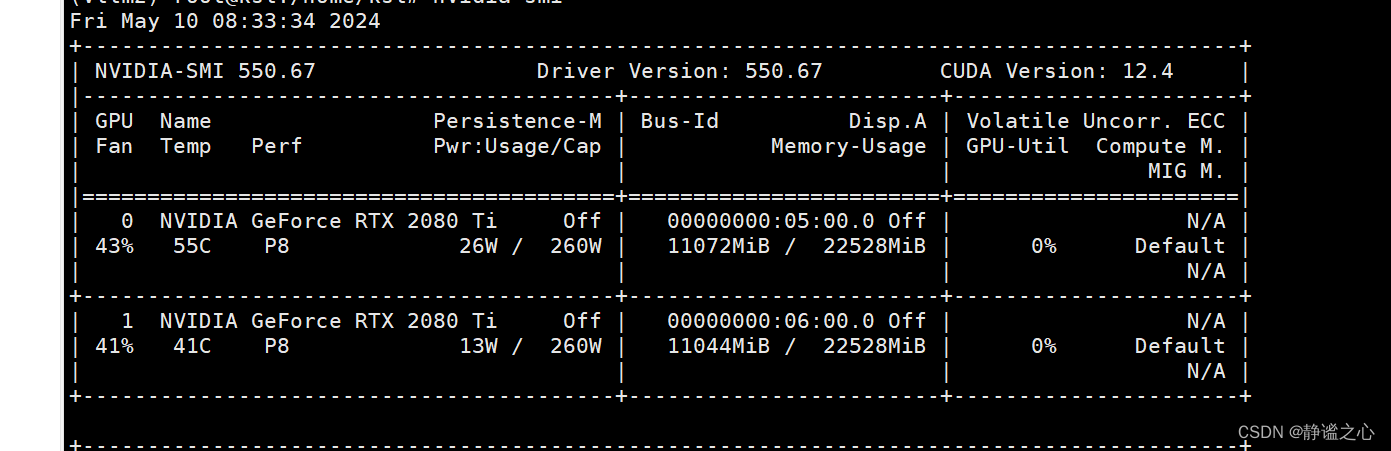
Fastchat + vllm + ray + Qwen1.5-7b 在2080ti 双卡上 实现多卡推理加速
首先先搞清各主要组件的名称与作用: FastChat FastChat框架是一个训练、部署和评估大模型的开源平台,其核心特点是: 提供SOTA模型的训练和评估代码 提供分布式多模型部署框架 + WebUI + OpenAI API Controller管理分布式模型实例 Model Worker是大模型服务实例,它在启动时向Controller注册 OpenAI API提供OpenAI兼容的A

详解FastChat部署大模型API的实战教程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了使用FastChat部署大模型API的实战教程,希望对学习大语言模型

读懂 FastChat 大模型部署源码所需的异步编程基础
原文:读懂 FastChat 大模型部署源码所需的异步编程基础 - 知乎 目录 0. 前言 1. 同步与异步的区别 2. 协程 3. 事件循环 4. await 5. 组合协程 6. 使用 Semaphore 限制并发数 7. 运行阻塞任务 8. 异步迭代器 async for 9. 异步上下文管理器 async with 10. 参考 本文是读懂 FastChat 大模
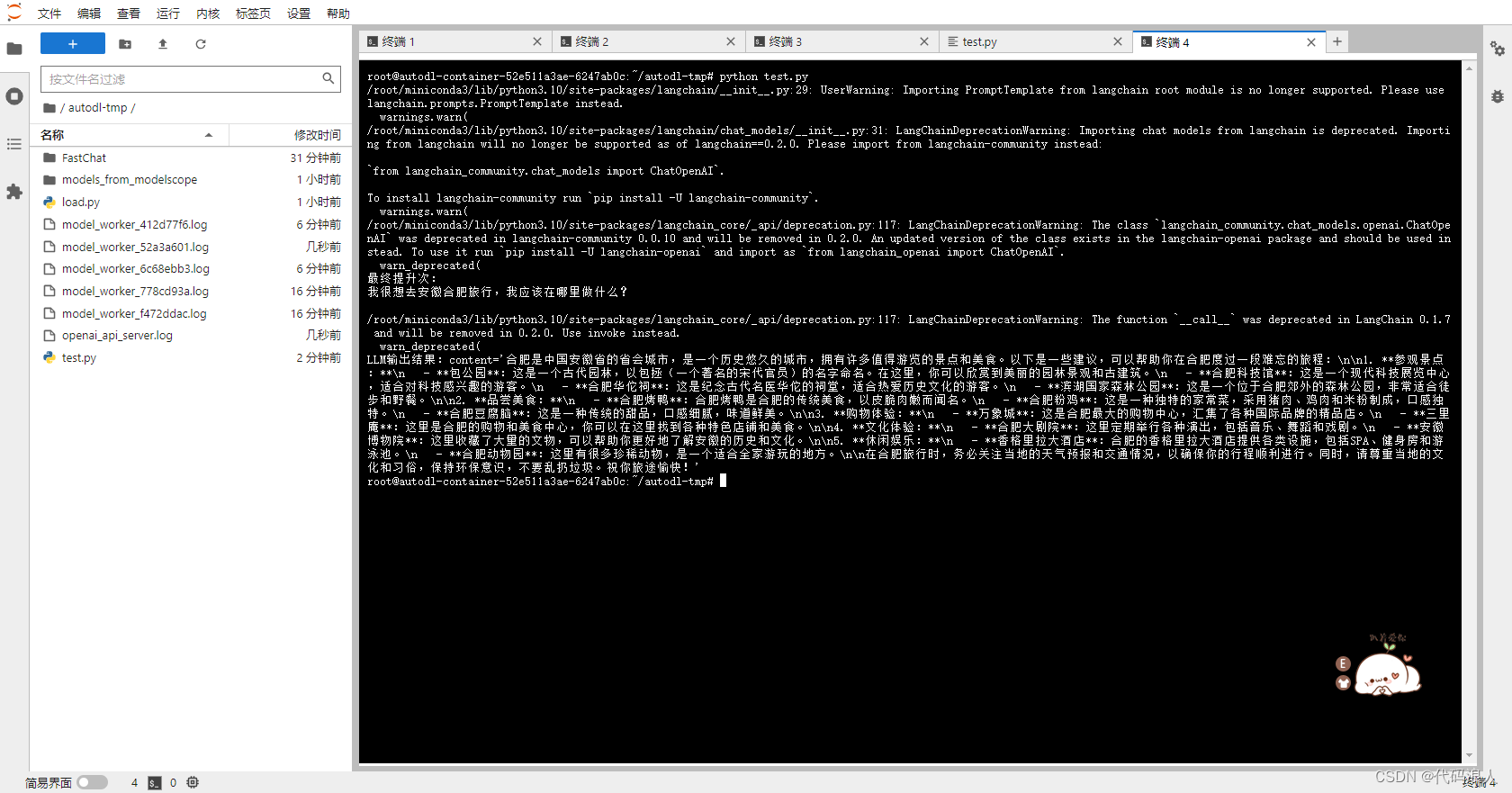
本地化部署大模型方案二:fastchat+llm(vllm)
文章目录 引言一、上一节内容二、FastChat 介绍三、FastChat 实战3.1支持模型3.2 准备环境(这里我准备了一个autodl的新服务器)3.3 安装魔搭环境,下载大模型3.4 安装并使用FastChat3.4.1 安装FastChat3.4.2 使用FastChat第一步启动controller第二步启动model_worker(llm)第二步代替方案(vllm)第三步ope
【大模型研究】(1):从零开始部署书生·浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行
1,演示视频 https://www.bilibili.com/video/BV1pT4y1h7Af/ 【大模型研究】(1):从零开始部署书生·浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行 2,书生·浦语2-对话-20B https://modelscope.cn/models/Shanghai_AI_La

fastchat出现TypeError: unsupported operand type(s) for -: ‘NoneType‘ and ‘int‘解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。 本文主要介绍了Sfastchat出现TypeE

Fastchat安装vicuna-7b-v1.3(小羊驼) ——超详细版
FastChat 是一个开放平台,用于训练、服务和评估基于大型语言模型的聊天机器人。核心功能包括: 最先进模型(例如,Vicuna)的权重、训练代码和评估代码。具有 Web UI 和 OpenAI 兼容 RESTful API 的分布式多模型服务系统。 Fastchat项目持续更新中,后续还未跟进,有兴趣请参看项目地址 项目地址:GitHub - lm-sys/FastChat: A
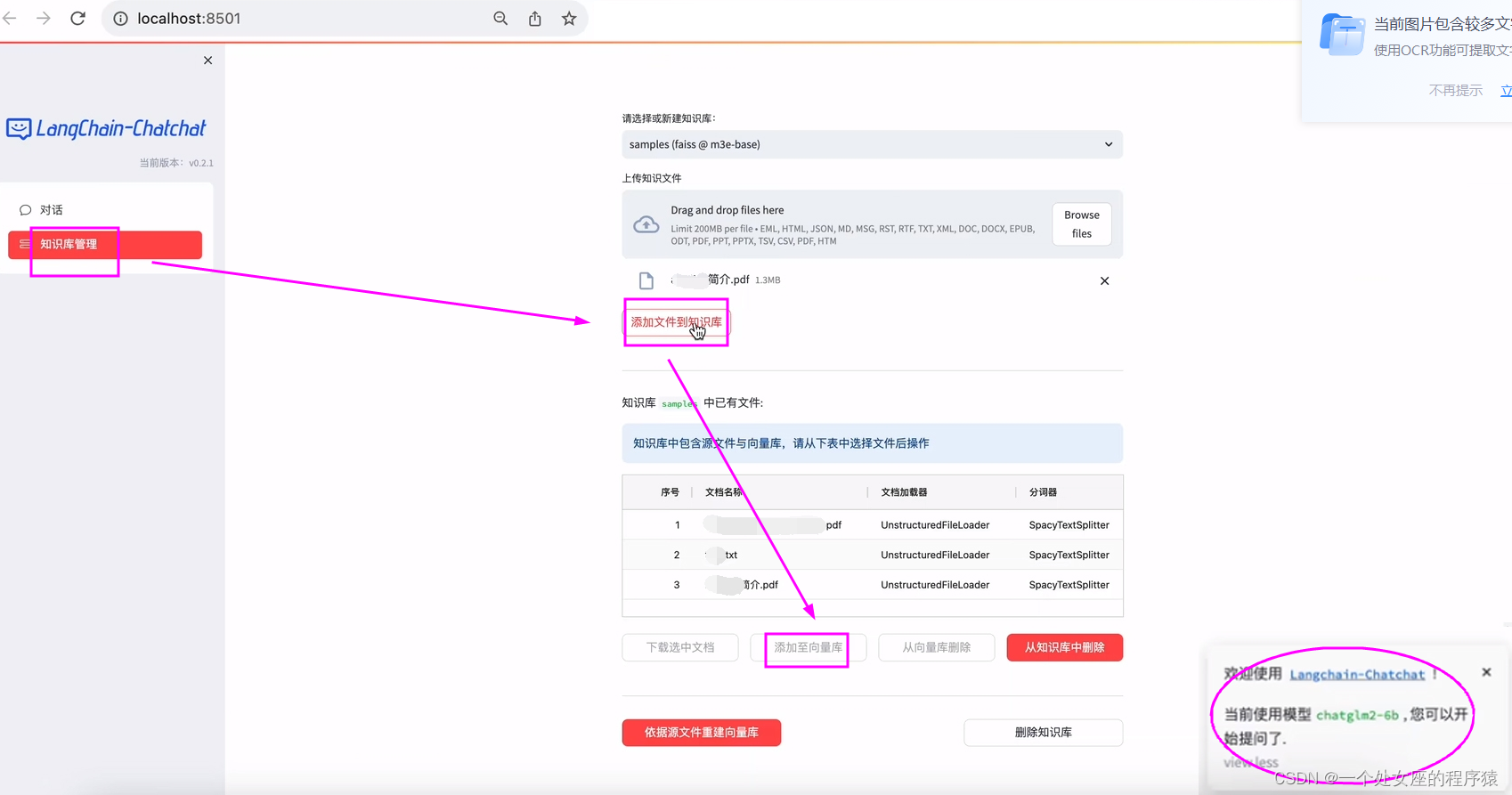
LLMs之RAG:LangChain-Chatchat(一款中文友好的全流程本地知识库问答应用)的简介(支持 FastChat 接入的ChatGLM-2/LLaMA-2等多款主流LLMs+多款embe
LLMs之RAG:LangChain-Chatchat(一款中文友好的全流程本地知识库问答应用)的简介(支持 FastChat 接入的ChatGLM-2/LLaMA-2等多款主流LLMs+多款embedding模型m3e等+多种TextSplitter分词器)、安装(镜像部署【AutoDL云平台/Docker镜像】,离线私有部署+支持RTX3090 ,支持FAISS/Milvus/PGVector

NLP(六十四)使用FastChat计算LLaMA-2模型的token长度
LLaMA-2模型部署 在文章NLP(五十九)使用FastChat部署百川大模型中,笔者介绍了FastChat框架,以及如何使用FastChat来部署百川模型。 本文将会部署LLaMA-2 70B模型,使得其兼容OpenAI的调用风格。部署的Dockerfile文件如下: FROM nvidia/cuda:11.7.1-runtime-ubuntu20.04RUN apt-get up