本文主要是介绍从数据角度分析年龄与NBA球员赛场表现的关系【数据分析项目分享】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
好久不见朋友们,今天给大家分享一个我自己很感兴趣的话题分析——NBA球员表现跟年龄关系到底大不大?数据来源于Kaggle,感兴趣的朋友可以点赞评论留言,我会将数据同代码一起发送给你。
目录
- NBA球员表现的探索性数据分析
- 导入Python库和加载数据
- 数据简要概述
- 数据可视化
- 年龄与上场时间的比较
- 年龄与出场次数相比较
- 年龄与PER相比较
- 结论
NBA球员表现的探索性数据分析
美国国家篮球协会(NBA)中有各个年龄段的新秀和资深球员。本次数据分析将突出年龄和技能之间的关系,同时研究年龄在球员表现中的因素。
导入Python库和加载数据
首先,加载数据,并按球员名称进行索引,然后查看前5行数据,以了解数据的样式。
import pandas as pd
pd.plotting.register_matplotlib_converters()
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from sklearn.linear_model import LinearRegression as linregNBA = pd.read_csv('./nba.csv',index_col=1)
NBA.head() | Rk | Pos | Age | Tm | G | MP | PER | TS% | 3PAr | FTr | ... | Unnamed: 19 | OWS | DWS | WS | WS/48 | Unnamed: 24 | OBPM | DBPM | BPM | VORP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Player | |||||||||||||||||||||
| Alex Abrines\abrinal01 | 1 | SG | 24 | OKC | 75 | 1134 | 9.0 | 0.567 | 0.759 | 0.158 | ... | NaN | 1.3 | 1.0 | 2.2 | 0.094 | NaN | -0.5 | -1.7 | -2.2 | -0.1 |
| Quincy Acy\acyqu01 | 2 | PF | 27 | BRK | 70 | 1359 | 8.2 | 0.525 | 0.800 | 0.164 | ... | NaN | -0.1 | 1.1 | 1.0 | 0.036 | NaN | -2.0 | -0.2 | -2.2 | -0.1 |
| Steven Adams\adamsst01 | 3 | C | 24 | OKC | 76 | 2487 | 20.6 | 0.630 | 0.003 | 0.402 | ... | NaN | 6.7 | 3.0 | 9.7 | 0.187 | NaN | 2.2 | 1.1 | 3.3 | 3.3 |
| Bam Adebayo\adebaba01 | 4 | C | 20 | MIA | 69 | 1368 | 15.7 | 0.570 | 0.021 | 0.526 | ... | NaN | 2.3 | 1.9 | 4.2 | 0.148 | NaN | -1.6 | 1.8 | 0.2 | 0.8 |
| Arron Afflalo\afflaar01 | 5 | SG | 32 | ORL | 53 | 682 | 5.8 | 0.516 | 0.432 | 0.160 | ... | NaN | -0.1 | 0.2 | 0.1 | 0.009 | NaN | -4.1 | -1.8 | -5.8 | -0.7 |
5 rows × 28 columns
*对于本次分析,我们其实只需要以下几个字段的数据。
- 球员的年龄, (Age)
- 出场场次 (G)
- 出场时间 (MP)
- 效率值Player Efficiency Rating (PER)
- 真实命中率 (TS%)
除了球员姓名外,其余列将被删除,并且任何包含缺失数据的列也将被删除。
nba_temp = NBA.loc[:, ['Age', 'G', 'MP','PER','TS%']]
nba = nba_temp.dropna(axis=0)
nba = nba[~nba.index.duplicated()]
nba.head()
| Age | G | MP | PER | TS% | |
|---|---|---|---|---|---|
| Player | |||||
| Alex Abrines\abrinal01 | 24 | 75 | 1134 | 9.0 | 0.567 |
| Quincy Acy\acyqu01 | 27 | 70 | 1359 | 8.2 | 0.525 |
| Steven Adams\adamsst01 | 24 | 76 | 2487 | 20.6 | 0.630 |
| Bam Adebayo\adebaba01 | 20 | 69 | 1368 | 15.7 | 0.570 |
| Arron Afflalo\afflaar01 | 32 | 53 | 682 | 5.8 | 0.516 |
为了更容易理解,列将被重新命名,以将它们转为非缩写形式。
nba =nba.rename(index=str, columns={'G' : '# Games','MP': 'Minutes Played','PER': 'Player Efficiency Rate'})数据简要概述
print(nba.shape) # 看下数量级
nba.describe()
(537, 5)
| Age | # Games | Minutes Played | Player Efficiency Rate | TS% | |
|---|---|---|---|---|---|
| count | 537.000000 | 537.000000 | 537.000000 | 537.000000 | 537.000000 |
| mean | 26.104283 | 48.605214 | 1105.862197 | 12.951769 | 0.531965 |
| std | 4.174854 | 27.312191 | 855.195522 | 8.749476 | 0.124523 |
| min | 19.000000 | 1.000000 | 1.000000 | -41.100000 | 0.000000 |
| 25% | 23.000000 | 21.000000 | 253.000000 | 9.700000 | 0.500000 |
| 50% | 25.000000 | 56.000000 | 1045.000000 | 12.800000 | 0.541000 |
| 75% | 29.000000 | 73.000000 | 1810.000000 | 16.400000 | 0.582000 |
| max | 41.000000 | 82.000000 | 3026.000000 | 133.800000 | 1.500000 |
- 在2017-18赛季,大约有537球员出场打比赛。
- 根据以往赛季的年龄平均值,预计2017-18赛季的NBA球员平均年龄约为26岁。
- 有趣的是,联盟中最年长的球员是41岁,比最年轻的球员大22岁!(最大的没记错的话应该是卡特,最小的没啥印象)
- 平均每位球员在赛季中打了43场比赛,而其真实命中率约为53%
数据可视化
正如之前注意到的,球员年龄范围广泛,但各年龄的分布人数情况又如何呢?
sns.set_style("dark")
plt.figure(figsize=(10,10))
plt.ylabel('# of Players')
sns.histplot(data=nba, x='Age')
plt.show()
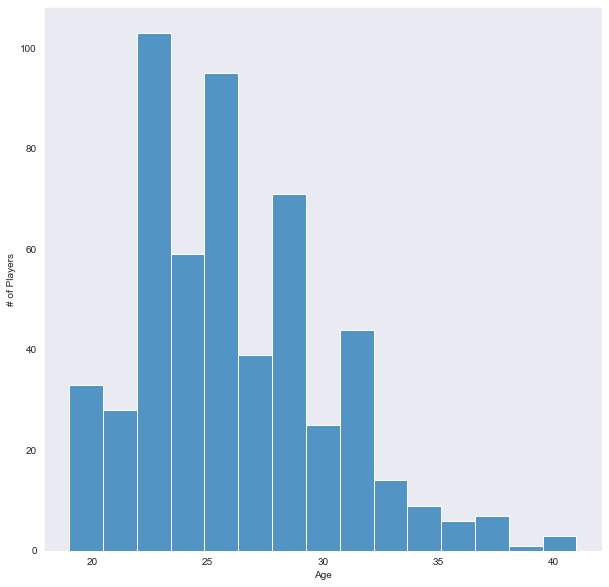
联盟过去和现在都倾向于年轻球员,这是可以预料的。球队通常会寻找年轻的潜力球员,在他们大学期间或之后选择他们。
然而,这个直方图只能提供有限的信息,我们仍然想知道年龄是否真的会影响球员的表现。所以让我们从年龄与参加比赛数量的关系开始看起吧
年龄与上场时间的比较
plt.figure(figsize=(20,10))
plt.ylabel('Minutes Played')
plt.xlabel('Age')
sns.regplot(data=nba, x='Age',y='Minutes Played')
plt.show()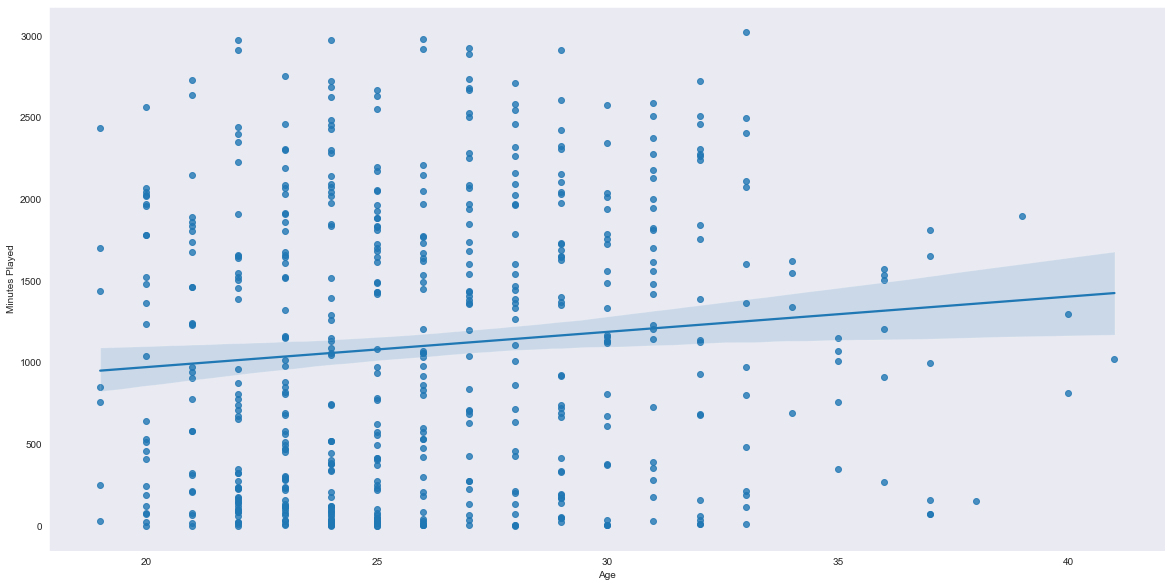
从上述散点图我们可以得知:
- 年龄在19岁至28岁之间的年轻球员比年龄在28岁至41岁之间的老年球员打的比赛更多。
- 年轻球员的上场时间范围总体上比老年球员更大。
- 总体上,老年球员的上场时间比年轻球员更长。
需要注意的是,这可能不是散点图的最佳线性拟合,然而,该图表大致说明年龄可能不会影响比赛中的上场时间。
年龄较大可能意味着更多的经验,从而在场上停留更长时间,但也有许多年轻的潜力球员比老将球员打得时间更长。
年龄与出场次数相比较
在我们进行年龄与参与游戏次数之间的比较之前,让我们先看一下参与游戏次数与比赛时间之间的关系。
plt.figure(figsize=(20,20))
plt.ylabel('Minutes')
plt.xlabel('Games')
sns.scatterplot(data=nba, x='# Games',y='Minutes Played')
plt.show()
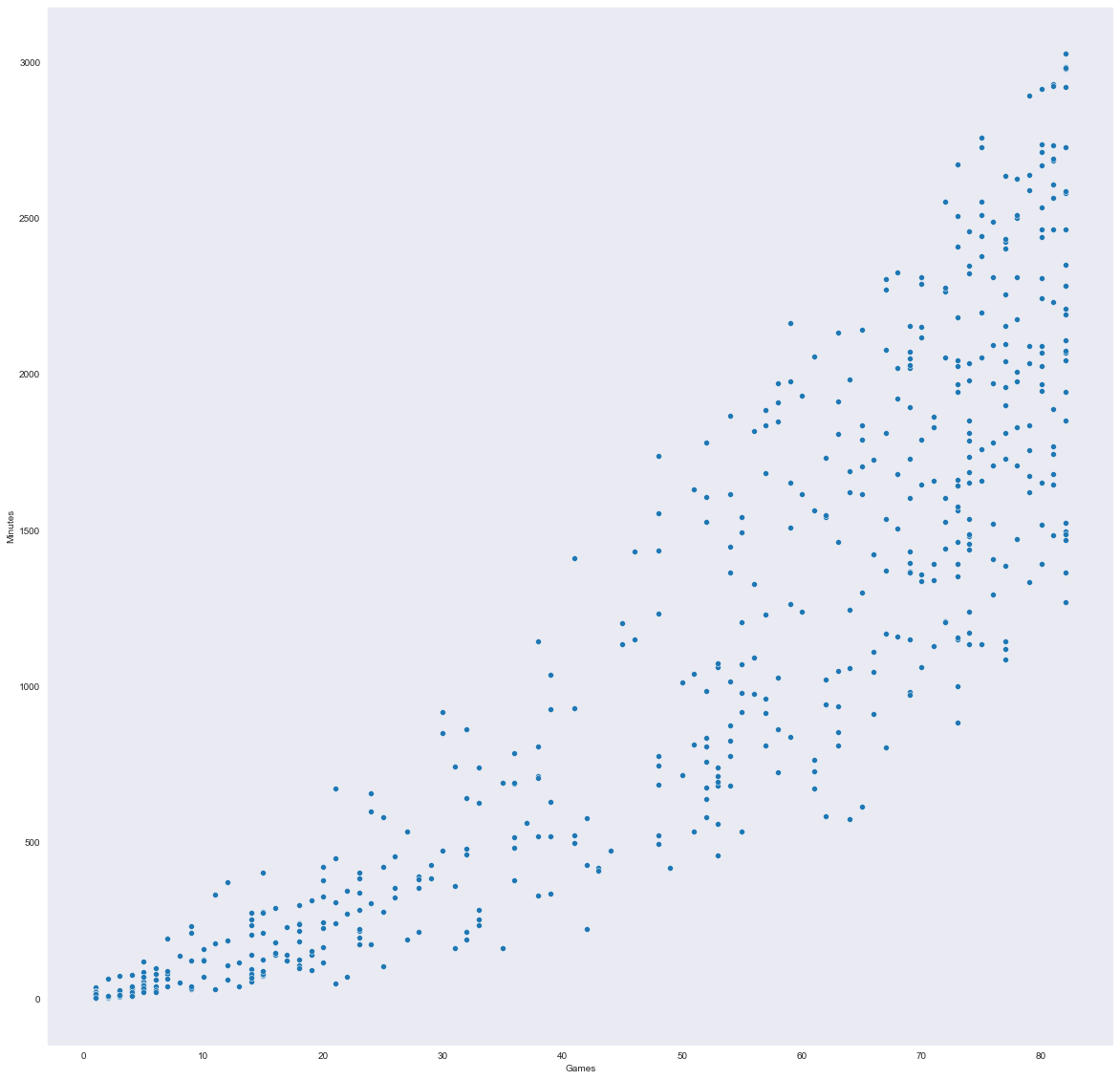
看起来,如果一个球员在赛季中参加的比赛越多,他们的平均比赛时间也会更长。
在这个基础上,让我们在这个比较中加入年龄。
plt.figure(figsize=(15,10))
plt.ylabel('Minutes')
plt.xlabel('Games')
sns.scatterplot(data=nba, x='# Games',y='Minutes Played', hue='Age')
plt.show()
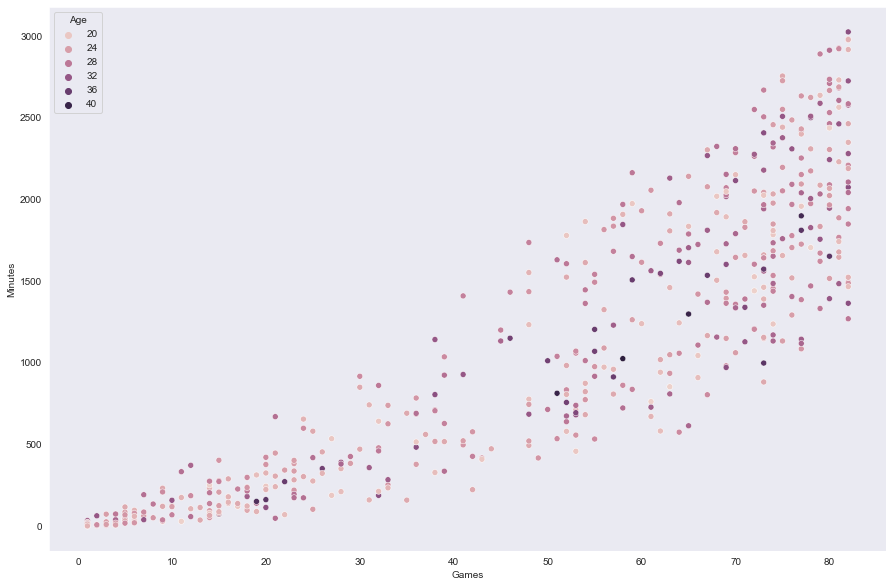
关于这个散点图需要注意的一些点:
- 这个散点图证实了我们关于年龄与比赛时间之间关系的结论,因为年龄大的和年龄小的人在各种时间段内都有参与比赛的情况。
- 年龄较小和较大的范围都分布在整个图中,这表明年龄可能不影响个体参与比赛的次数。
在表现方面,看起来年龄只是一个数字?也许是这样,但我们目前只关注了定量方面的因素,那么比赛中的实际技能呢?
年龄与PER相比较
尽管可能有球员参加更多比赛或比赛时间更长,但这并不能准确地描绘这些个体的表现。因此,我们将根据年龄来评估这些散点图的真实性,考察球员的球员效率评分(PER)。
但是,什么是PER呢?PER简单来讲就是:它允许将篮球运动员的所有成就(得分、盖帽、抢断等)转化为一个单一的数字。PER也是一种每分钟的度量方式,可以比较任意两位选手,而不受比赛场次或比赛时间的限制。这也是为什么我们之前删除了一些列的原因,因为这样可以更简便地比较累积统计数据,如PER,而不需要处理每个个体方面的数据。
有了PER,我们现在可以从新的角度分析年龄对表现的影响。
plt.figure(figsize=(15,10))
sns.regplot(data=nba, x='Minutes Played',y='Player Efficiency Rate')
plt.show() 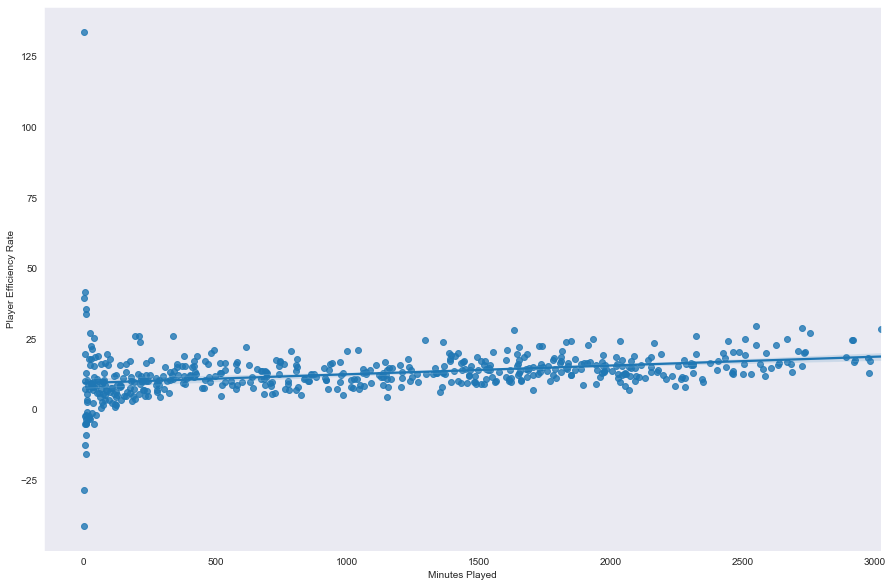
单看平均趋势的话,如果一个球员参与比赛的时间更长,他们的PER很可能比大多数人要高。
那接下来,我们来比较下比赛次数与PER之间的关系。
plt.figure(figsize=(15,10))
sns.regplot(data=nba, x='# Games',y='Player Efficiency Rate')
plt.show()
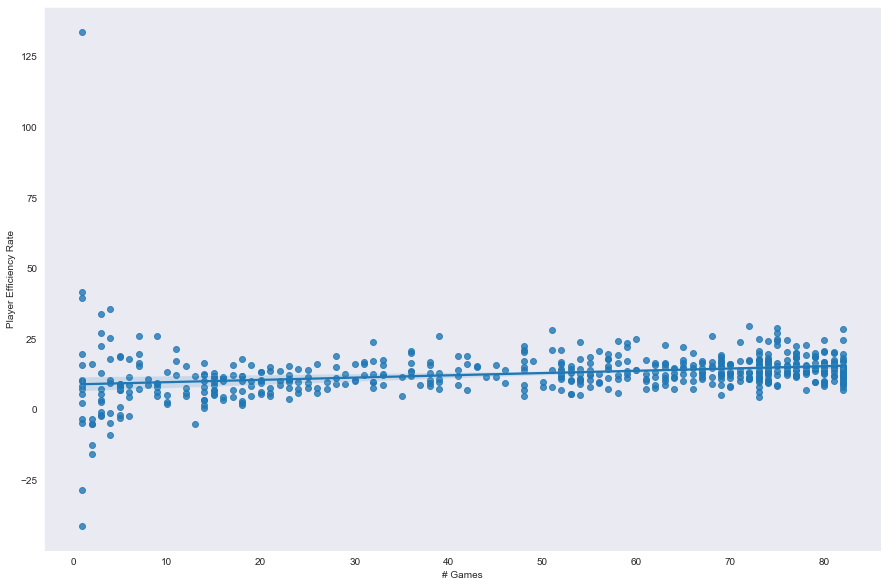
同样的情况,如果一个球员参加的比赛更多,他们的PER很可能更高。
所以到目前为止,一切似乎都符合预期,PER与球员在比赛中的参与程度呈正相关关系。
那现在,让我们开始将年龄与这两个变量进行比较。
plt.figure(figsize=(15,10))
sns.regplot(data=nba, x='Age',y='Player Efficiency Rate')
plt.show()
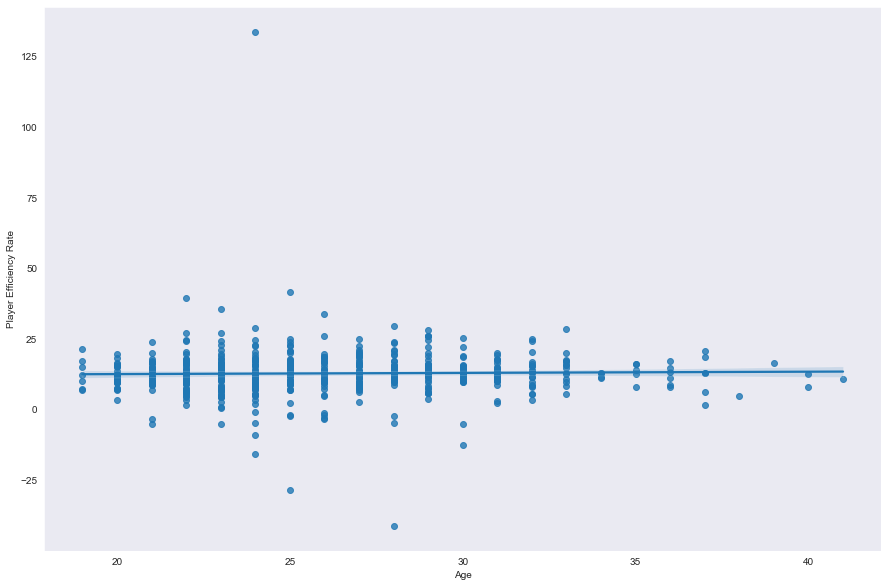
在回归斜率中几乎是一条直线,年龄几乎与PER没有关系。但这意味着什么呢?
这意味着年龄与球员效率评分之间几乎没有明显的关联。年龄对于一个球员的表现并不是决定因素,至少在这个数据集中。其他因素,如技能水平、体能和经验可能更重要。
结论
尽管我们对不少的变量同年龄进行了比较,并使用了不同的绘图方法,但年龄似乎从未对最终结果产生影响。年龄对于篮球运动员来说既不是负面特征,也不是优势。
根据这个分析,还可以得出一些其他的结论:
- 这些仅仅是一个赛季中少数球员的结果,因此我们不能轻易将此结论推广到NBA的每个赛季。
- 在NBA中,年龄是相对而言的。年龄范围在很大程度上分为年轻球员和年长球员,但可以重新进行分析,并尝试使用更小的年龄段,可能会得出新的见解。
- 这个分析纯粹基于可视数据,对于个人表现的每个方面,如领导能力和团队合作,并没有提供深入了解。
总的来说,这个分析我觉得是可以给到我们一个新的视角来了解NBA球员的水平,因为即使年龄不小了,他们也不会让年龄成为阻碍,努力成为最好的球员。
最后,很高兴在kaggle闲逛的时候有幸能看到一个我这么感兴趣的数据集,也仅以此篇,致敬詹库杜,致敬那些现在仍在奋斗着的NBA老将们。
推荐关注的专栏
👨👩👦👦 数据分析:分享数据分析实战项目和常用技能整理
这篇关于从数据角度分析年龄与NBA球员赛场表现的关系【数据分析项目分享】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






