本文主要是介绍TVP-VAR模型MATLAB代码【增加时间标签、三维脉冲响应图、sa2参数输出】(企研数据修改自Nakajima(2011)),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、TVP-VAR模型与常用代码简介
【代码已修改完善,详见评论区】TVP-VAR模型(Time-Varying Parameter Vector AutoRegression,时变参数向量自回归模型)是在VAR模型的基础上拓展而来的模型,其假定系数矩阵和协方差矩阵是时变的,使得模型可以捕捉经济结构随时间变化的过程。
日本学者中岛上智(Jouchi Nakajima)于2011年发表的Time-Varying Parameter VAR Model with Stochastic Volatility: An Overview of Methodology and Empirical Applications是TVP-VAR领域的经典文献,其同时在个人网站上(https://sites.google.com/site/jnakajimaweb/)分享了论文中估计TVP-VAR模型所用的Oxmetrics和MATLAB程序代码,由于OxMetrics软件较为小众,因此很多人会选择使用更为熟悉的MATLAB版本的代码。

中岛上智教授分享的代码上一次更新时间为2020年5月1日,然而MATLAB版本的代码相比OxMetrics存在部分美中不足的地方,即MATLAB版本的代码无法显示现实的时间点,只能显示其在样本数据中的顺序,且MATLAB的作图限制导致其最多允许四条曲线叠加,如果想同时观察四种以上不同情况,难度比较大。
二、我们的工作
针对上述情况,我们谨慎修改了中岛上智教授发布的MATLAB版本的TVP-VAR模型代码,允许用户补充时间标签数据并将其显示出来,同时添加了生成三维脉冲响应图形的功能;针对许多人反应的缺少sa2参数的问题,我们谨慎添加了sa2参数结果的汇报。需要声明的是,我们并未修改任何估计方法或参数,以确保结果的准确无误。
如需获取代码压缩包请私信
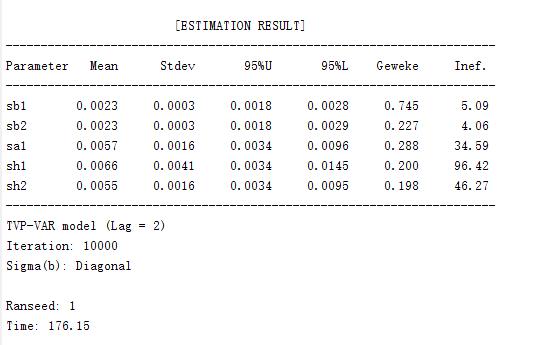
以下为增加了sa2参数的汇报结果对比:
效果对比1:

效果对比2:
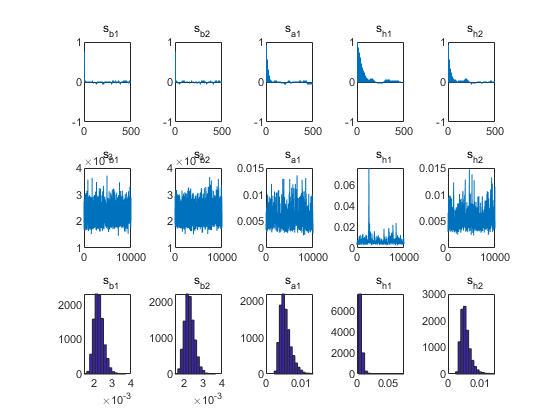
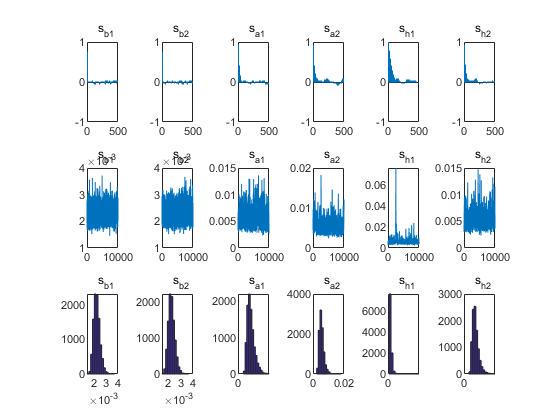
以下为原始输出结果和修改后输出结果的对比:
效果对比3:


效果对比4:
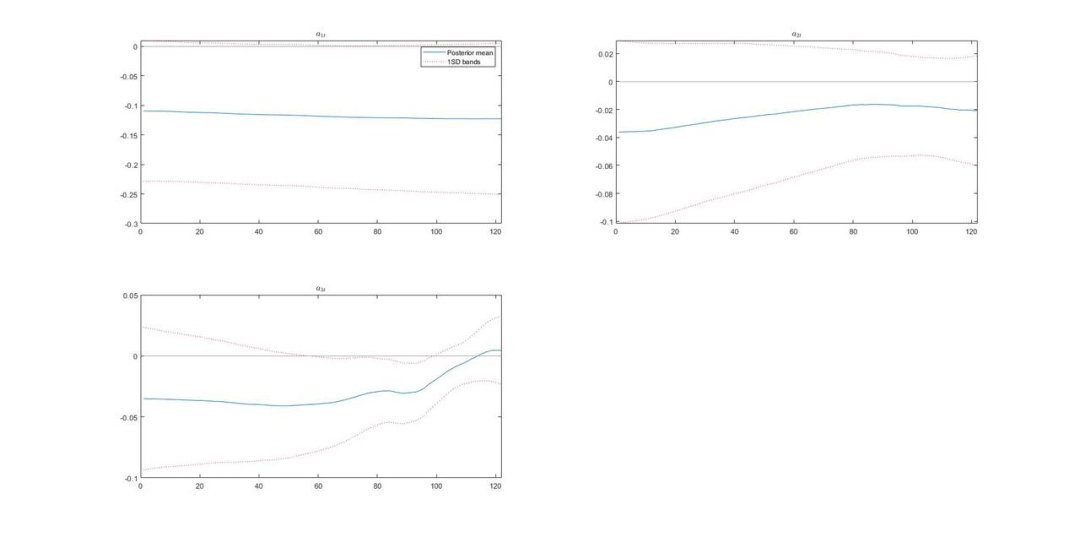

效果对比6:

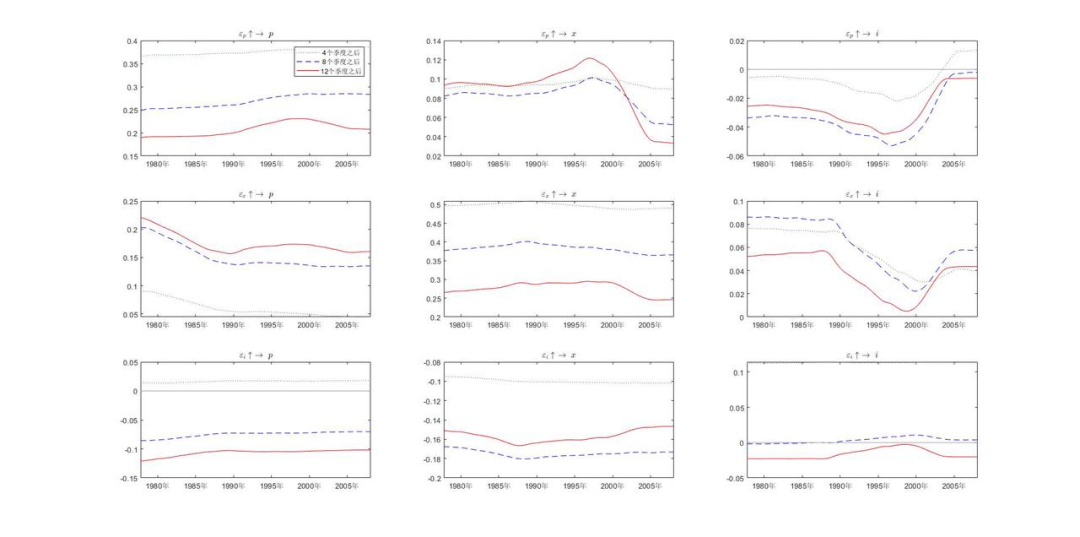
效果对比5:
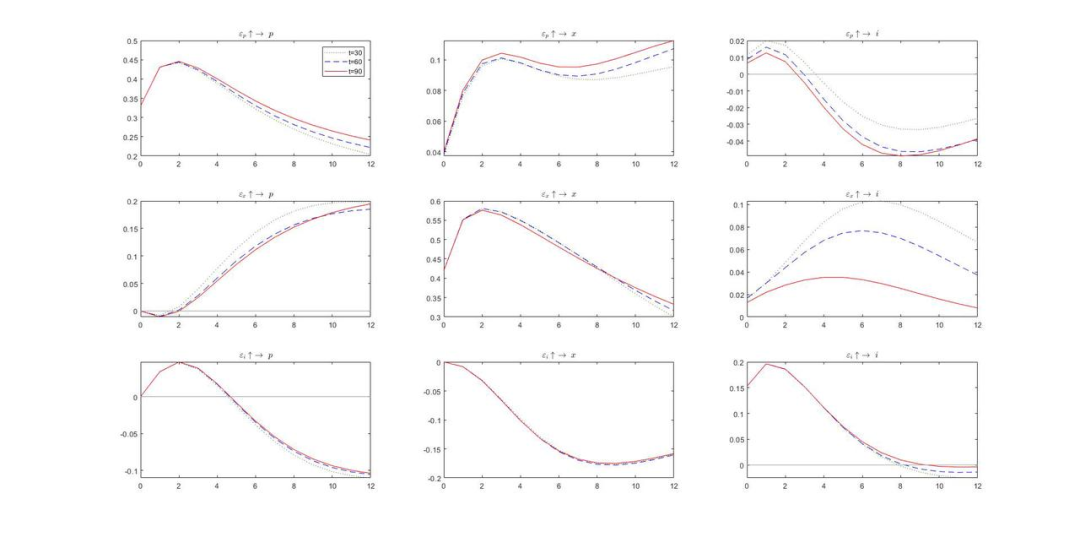
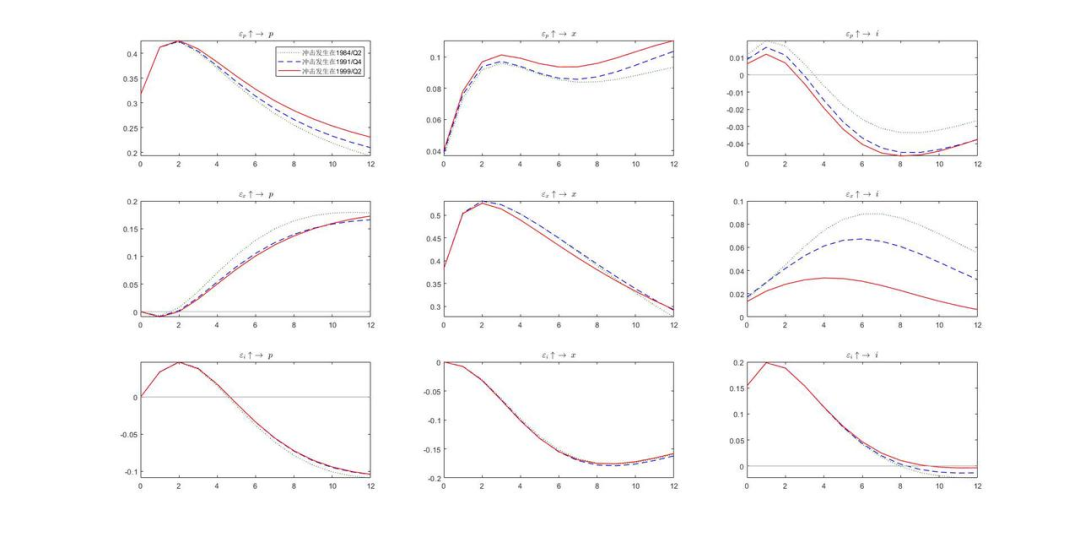
以下为部分三维脉冲响应图形的展示:
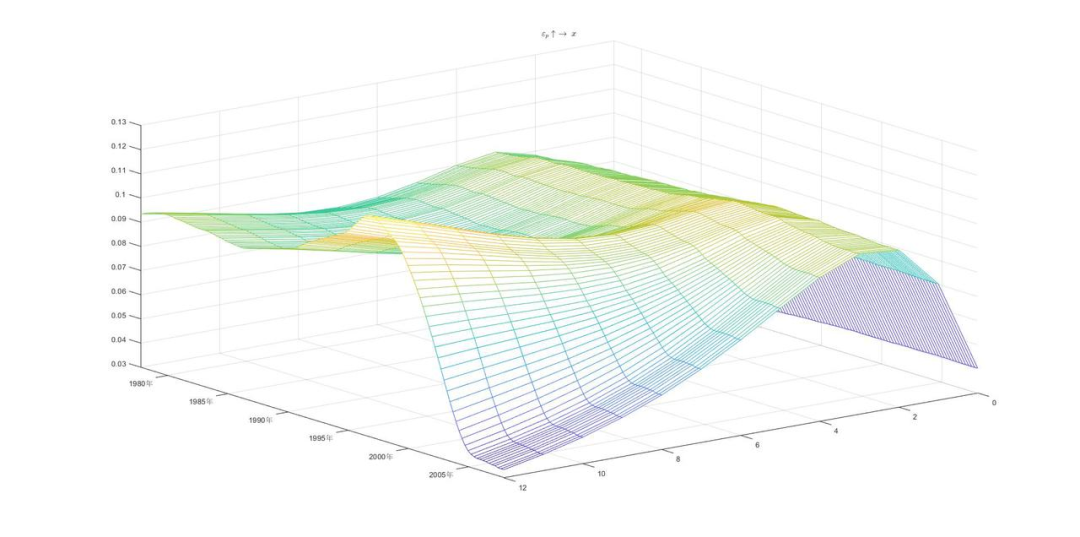
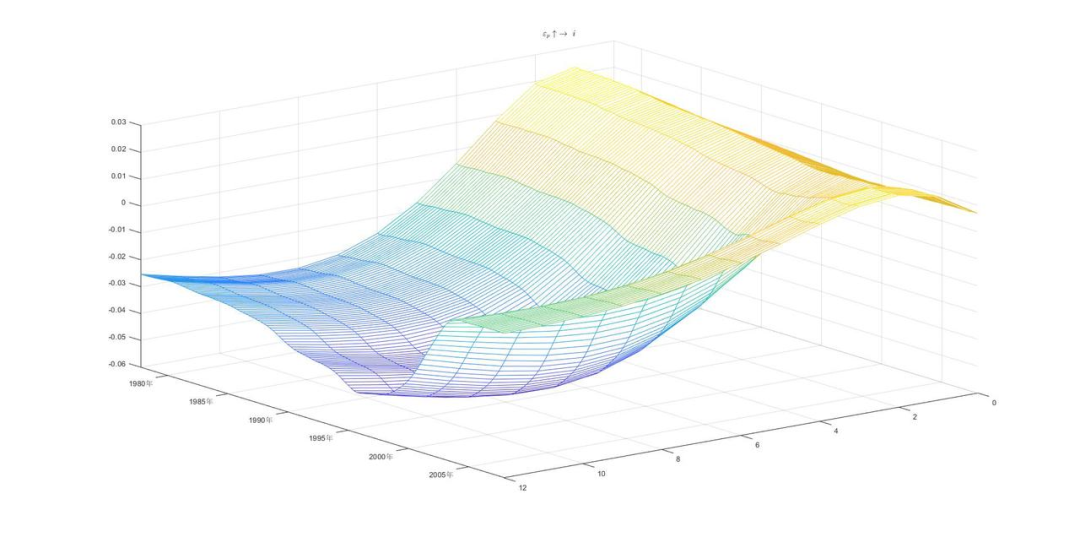

三、使用说明
中岛上智教授提供了样例数据,请严格按照样例数据的格式将要估计的数据存入EXCEL表中,每一列存储一个变量,左上角不留空白,且表中除数据外不存在多余的空白行,否则会导致估计出错;
例如,在中岛教授提供的tvpvar_ex.xlsx中,总共有124期、共三个变量的数据,存储在A1-C124的范围内的单元格中,如果存在空白行,则可能导致MATLAB在载入数据时扩大读取范围,如将A1-D200范围内的单元格一并读入,最终导致参数估计失败;
我们仿照并补充了中岛上智教授的样例数据所对应的时间标签数据,存储在tvpvar_ex_time.xlsx的A1-A124范围内的单元格中,EXCEL表中同样不允许存在多余的空白行;
时间格式等参数请参阅MATLAB的相关文档;
tvpvar_m文件夹中为中岛教授的原始代码,tvpvar_m_modified文件夹中为修改后的代码,本版本代码仅修改了以下文件:drawimp.m;mcmc.m;tvpvar_ex1.m;tvpvar_ex2.m;
sa2参数的汇报功能由团队成员添加,如存疑可以自行删去。
四、特别声明
本代码仅是对中岛上智教授工作成果的少量修饰,代码本身仍然是中岛上智教授的工作成果,如果使用了本代码,请按如下规范引用:
Nakajima, J. (2011) "Time-varying parameter VAR model with stochastic volatility: An overview of methodology and empirical applications" Monetary and Economic Studies, 29, 107-142.
严禁私自将本代码用于商业目的!违者必究!
如需获取代码压缩包请私信
这篇关于TVP-VAR模型MATLAB代码【增加时间标签、三维脉冲响应图、sa2参数输出】(企研数据修改自Nakajima(2011))的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




