本文主要是介绍数据分析等于算命?基于纳什均衡的竞技游戏英雄数值设计先验模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.背景
最近在玩《战地1》,发现战地的角色设计还是很有意思的,不同于《彩虹六号》特色鲜明,和游戏策略强结合的干员技能,战地系列里面支援兵、医疗兵等不同兵种的能力是比较隐晦的,例如支援兵可以像突击兵一样往前猛冲,主要特点是供弹能力,刚玩的时候感觉没有什么兵种的感受,但是玩久了之后发现队伍缺了支援兵是真的不行的,侦察兵、医疗兵的强度会大大减弱
于是有了一个想法:能不能预先判断怎么样的兵种数值,可以均衡每个兵种的出场率,让喜欢每种兵种的玩家都享受这个游戏?
2.数据模型
基本思路:
- 射击游戏是一个典型的博弈场景,玩家需要尽可能地通过击杀对手、占领目标等方式来获取胜利,战地中玩家常常以小队的形式发生对抗。
- 在这个背景下,我们可以将博弈抽象为“小队”之间的对抗,将小队的构成(如全突击、突击+侦察+医疗、突击+支援等)作为策略集S,此时兵种的技能调整将会影响每个策略的收益(或者说“阵容强度”),阵容强度的差异会使得博弈者(即玩家)倾向于使用高收益阵容,从而影响对局中的小队构成分布(即“环境”)。
- 通过线性规划的优化求解方法,我们可以从当前的阵容强度推导出未来可能的环境构成,从而对环境有一个提前的预判
- 有了环境的预判,一方面我们可以提前判断当前的阵容构成是否存在平衡性问题,另一方面可以判断当前的环境构成是否与产品的用户群体构成匹配,从而预估对用户留存的影响

举一个栗子:
- 由于当前版本突击兵太强了,大家都在玩突击兵,我们同时上调了支援兵种的供弹量和医疗的加血速度,那么对核心的留存指标会有什么影响呢?
- 首先,我们将新的数值输入收益预测模型,预测在新的数值下每一类小队构成对位其他小队构成时的收益
- 基于预测模型的结果,更新阵容对位收益矩阵,求解当前收益下的混合纳什均衡,并于之前的作对比
- 在混合纳什均衡中显示,多突击兵阵容的出场概率从80%下降到了40%,同时包含支援兵的阵容从10%上升到了30%,包含医疗兵的阵容从30%上升到了60%
- 从平衡性的角度来看,所有兵种的上场率都能提升到20%+,平衡性的提升必然会带来更好的游戏体验,从而提升留存;从用户群体匹配的角度来看,擅长支援和医疗的用户能够得到合适的生存空间,因此留存意愿也会更高
胜率预测
在这个模型下,小队阵容之间的对位收益是最重要的评估依据,我们可以从玩家测试中获得各类小队阵容的对战结果,但是当我们要调整兵种技能的情况下,这种线上测试的数据就无法提供有效的支撑了。
因此,我们需要构建一个预测模型,以判断在我们对兵种技能和数值作调整之后,可能的对战结果是怎么样的,即当小队A与小队B遭遇后,可能的结果Y
F(A,B)=Y
在模型的特征上,我们主要基于小队兵种的数值来构建,例如A小队是突击兵+侦察兵+医疗,B小队是双突击+医疗,则:
- A小队的位移能力是高于平均水平的,但是B小队的位移能力更强
- A、B小队的回血速度与回血上限相等
- A小队拥有侦察兵,因此侦察范围为X,而B小队为0
- 根据实际的对战数据标记 Y=0 or 1,作为训练集数据
除了这些特征外,其他的小队面板数据(如支援兵种的修车速度等)均可以作为特征输入到模型内

预测模型可以采用Xgboost或LGBM,模型本身对预测准确性要求不高,更重要是减少过拟合的情况,保证模型对兵种面板数据的变更有较好的响应
组队环境推演
接下来我们需要构建一个小队对位矩阵,矩阵主要由阵容策略集S和对位胜率W组成
- 矩阵中,每一个阵容都是一种策略,构成了策略集S。策略集S1和S2
- 矩阵中,每一个格子W表示这一行(如突击+支援)对上这一列(如侦察+支援+支援)的胜率
- 胜率的数据主要通过收益预测模型得到

在有了这样一个矩阵后,我们可以基于混合纳什均衡的线性规划优化求解方法,得到在混合纳什均衡状态下的小队组队环境,从而对改动上线后的对局环境有先验的认知。得到:
简单补充说明一下混合纳什均衡(Mixed Nash Equilibrium , MNE):
- 在二元非合作博弈中,随着博弈双方对方策略的了解,最终双方必然会进入一个均衡状态中,在这个状态下无论哪一方改变自己的策略,都会引起对方有机会获得更大收益,因此两方均不会改变自己的策略,则此策略组合被称为纳什均衡
- 在实际生活中,只能选择单一策略的情况是比较少的,所以有了混合策略的概念,即用户的策略是以一定的概率打出的,对应到《战地1》中就是组队的形式,有时候我们会选择单兵种,有时候会选择支援+其他进攻能力强的组合,这时候同样存在一个最优的组合,从而使得双方按照这个组合的时候能够获得最大收益
业务分析
平衡性检验
平衡性是非常常见的一个判断依据,基于推演的组队环境,我们可以对兵种出场率有一个明确的预判,结合对位胜率矩阵中的相关数据,我们也能得到兵种平均胜率的数据,例如推演结果为:
MNE状态:
(突击+控制):10%;(支援+突击):50%;(支援+侦察):40%
对位胜率矩阵:
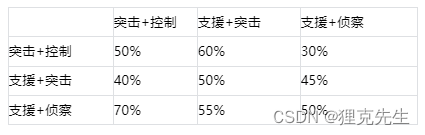
则支援的出场率=90%,
平均胜率=0.5/0.9x(0.1x0.4+0.5x0.5+0.4x0.45)+0.4/0.9x(0.1x0.7+0.5x0.55+0.4x0.5)
=0.26+0.25
=51%
同理,我们也能计算出其他兵种的出场率和胜率,以及诸如全突击等特殊阵容的出场率与胜率等,从而对环境平衡性有先验的认知
匹配性检验
组队环境与用户群体构成的匹配程度决定了用户留存,譬如当游戏现有用户中突击、支援、侦察型用户的分布为4:3:3时,如果当前游戏环境要求有超过60%的用户使用支援兵种,则会出现明显的不匹配,导致突击兵被迫玩支援等情况,从而引起用户流失,此时匹配性我们可以从推演的组队环境中进行判断
3.待优化问题
以上分析都是基于理论推导和对产品的认知建立的,实际中针对具体的数据分布情况,必然会存在可行性或准确性的问题,需要根据实际的数据分布来调整模型或指标的设计
关于胜率预测
- 很有可能会受到样本分布的影响,由于平衡性改动通常不会非常频繁,因此模型可能会对训练集出现过拟合,导致输入新的兵种数值时无法很好的响应,模型的构建需要多次不同的数值调整才能较为稳定,但无论如何,只要我们持续产生不同数值下的战斗数据,模型的预测效果就会越好
关于组队环境推演
- 推演是基于纳什均衡理论的,纳什均衡成立的前提是所有玩家都是理性的,并且他们都能感知到这些策略之间的对抗关系。实际中这2点常常难以达到,此时可以考虑将推演结果与线上数据的差异纳入考量范围,主要判断变化趋势而非绝对的数值
这篇关于数据分析等于算命?基于纳什均衡的竞技游戏英雄数值设计先验模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








