本文主要是介绍训练DAMO-YOLO(damoyolo_tinynasL25_S.py),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 参考链接
- 1 准备数据
- 1.1 转为COCO格式
- 1.2 指明数据路径
- 2 设置训练配置文件,在configs/damoyolo_tinynasL25_S.py进行如下两块修改
- 2.1 关于训练参数的设置
- 2.2 根据自己数据集设置
- 3 开始训练
- 4 调用tools/eval.py进行测试
- 5 训练时可能遇到的报错
- 5.1 RuntimeError: Distributed package doesn't have NCCL built in
- 5.2 ModuleNotFoundError: No module named 'damo.base_models.core'
参考链接
- 官方代码:DAMO-YOLO
- DAMO-YOLO最强操作教程.我的这博文不算很详细,可以去看看这篇博文的视频链接。但我的博文也就是少了配置虚拟环境的步骤,其实如果已经配置好了YOLO相关的虚拟环境,跟着我来应该是能跑通的
1 准备数据
1.1 转为COCO格式
- 参考我的另一篇博客:将YOLO数据集转成COCO格式,单个文件夹转为单个json文件,例如…/images/train转为instance_train.json
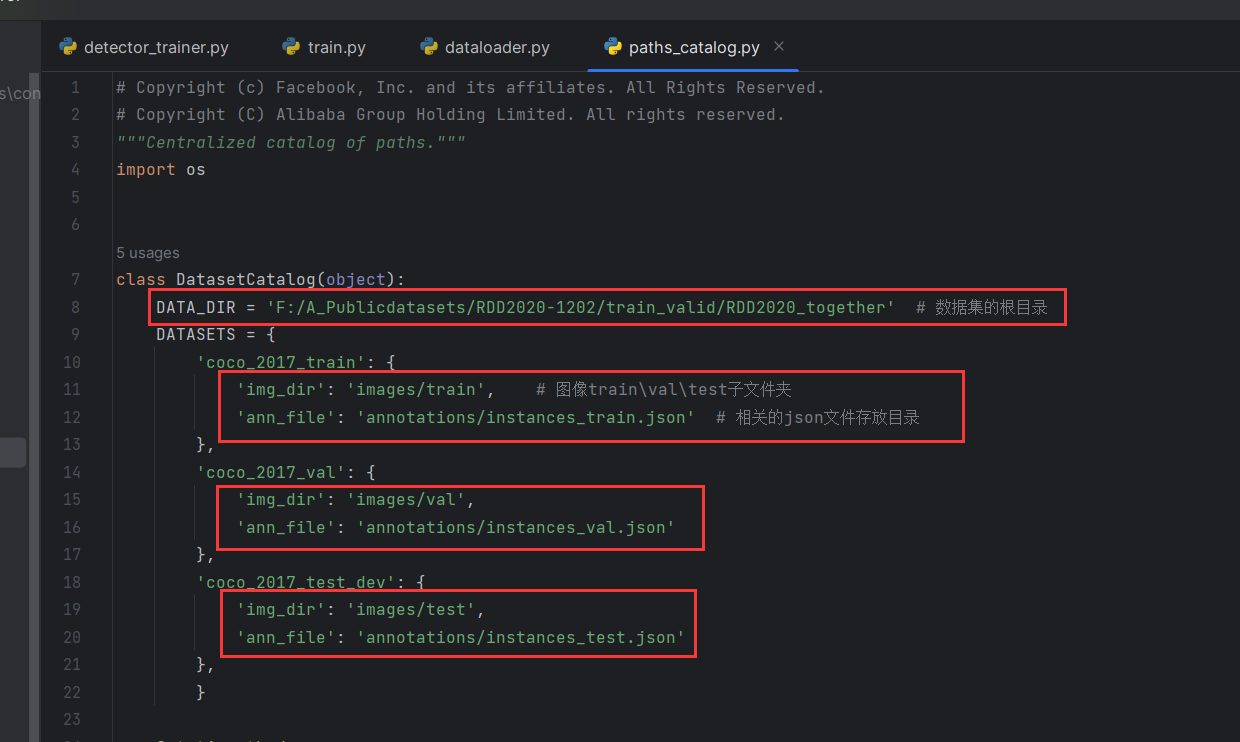
1.2 指明数据路径
在damo/config/paths_catalog.py进行修改
2 设置训练配置文件,在configs/damoyolo_tinynasL25_S.py进行如下两块修改
在configs/damoyolo_tinynasL25_S.py进行如下两块修改
2.1 关于训练参数的设置
右侧的base.py在damo/config/base.py
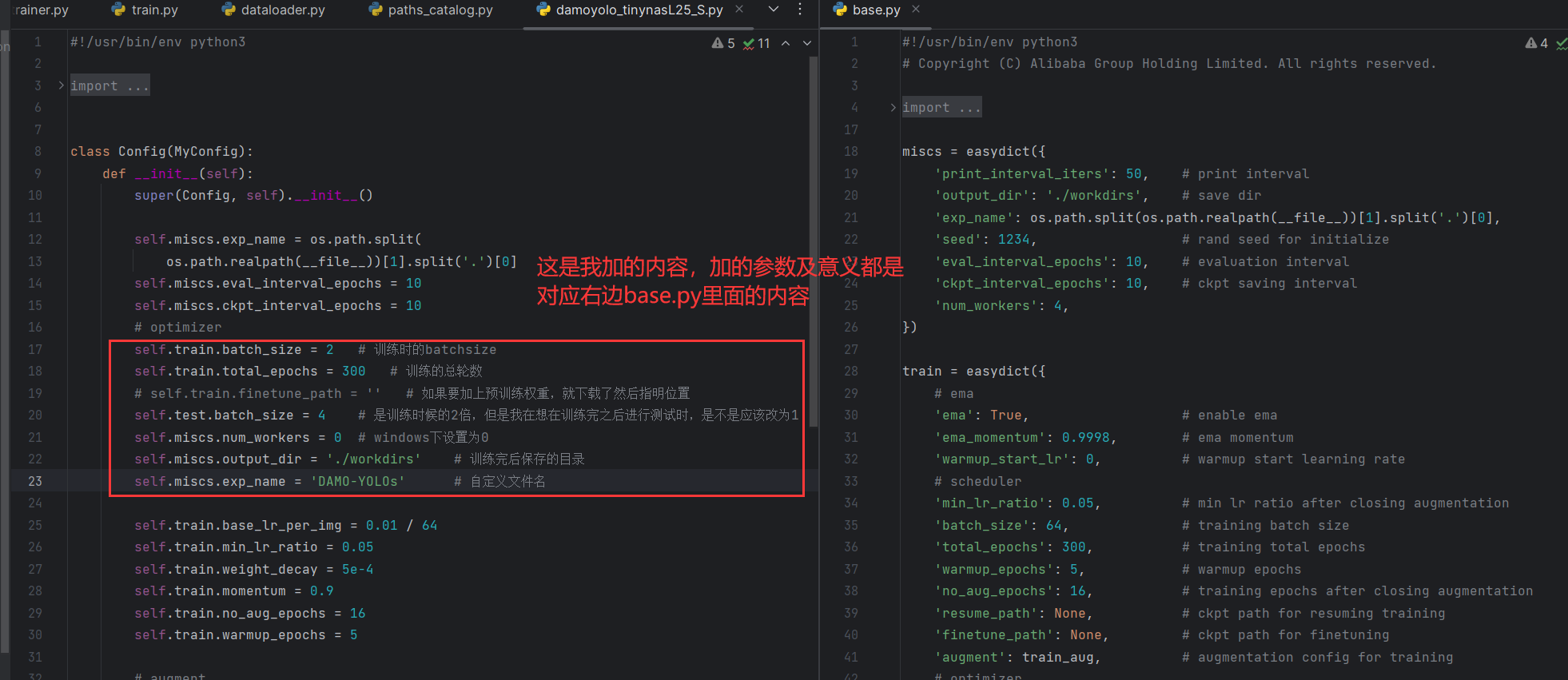
self.train.batch_size = 2 # 训练时的batchsizeself.train.total_epochs = 300 # 训练的总轮数# self.train.finetune_path = '' # 如果要加上预训练权重,就下载了然后指明位置self.test.batch_size = 4 # 是训练时候的2倍,但是我在想在训练完之后进行测试时,是不是应该改为1self.miscs.num_workers = 0 # windows下设置为0self.miscs.output_dir = './workdirs' # 训练完后保存的目录self.miscs.exp_name = 'DAMO-YOLOs' # 自定义文件名
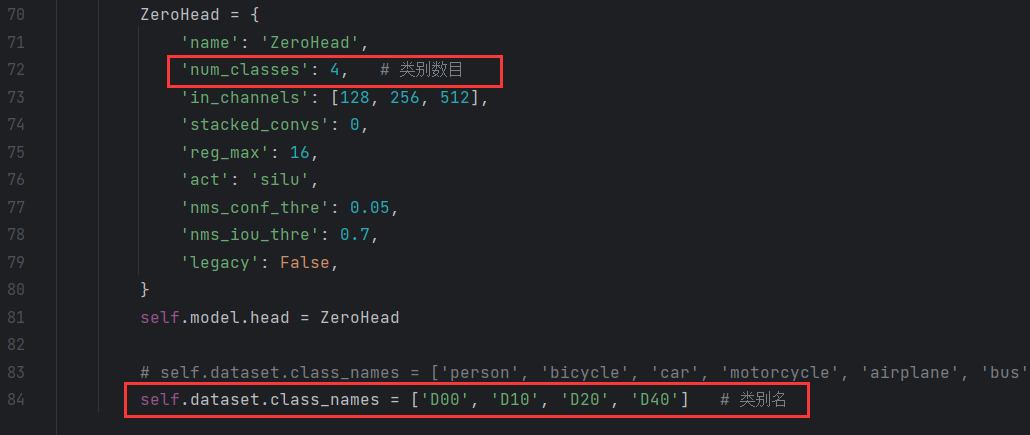
2.2 根据自己数据集设置
3 开始训练
python -m torch.distributed.launch --nproc_per_node=1 tools/train.py -f configs/damoyolo_tinynasL25_S.py
- 可以像下图一样,直接设置好配置文件的
绝对路径,肯定不会出现找不到配置文件的错误

- 这个
-m torch.distributed.launch --nproc_per_node=1是用来设置多卡训练的,必须要带上才能正常运行起来,因此我在调试的时候多有不便,亲测这个博客很有用,如果有需要可以参考:Pycharm 调试debug torch.distributed.launch- 兴许这个博客也能有用,暂存一下:DAMOYOLO windows 单卡训练
4 调用tools/eval.py进行测试
官方示例:
python -m torch.distributed.launch --nproc_per_node=1 tools/eval.py -f configs/damoyolo_tinynasL25_S.py --ckpt /path/to/your/damoyolo_tinynasL25_S.pth
5 训练时可能遇到的报错
5.1 RuntimeError: Distributed package doesn’t have NCCL built in
解决方法:会出现这个错,是因为在Windows上跑的,那么只要在tools/train.py中定位到backend='nccl',然后把nccl改为gloo即可
5.2 ModuleNotFoundError: No module named ‘damo.base_models.core’
解决方法:会出现这报错,是因为程序没有根据找到damo包的位置,其实就是代码写得有点奇怪然后没有找到路径。只要把tools/train.py复制到根目录下,然后运行就可以了
这篇关于训练DAMO-YOLO(damoyolo_tinynasL25_S.py)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别](https://i-blog.csdnimg.cn/direct/22c867ab717d44c78b985ed667169b42.png)