本文主要是介绍文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《与新能源互补和独立参加多级市场的抽蓄电站容量分配策略》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》
这个标题涉及到抽蓄电站在能源系统中的角色,特别是在多级市场中的参与,并强调了新能源的互补性以及抽蓄电站的独立性。下面我将对标题中的关键术语进行解读:
-
新能源互补: 这指的是抽蓄电站与新能源(可能是太阳能、风能等)之间的互补关系。抽蓄电站通常可以弥补新能源的间歇性和不稳定性,通过储存多余的新能源产生的电力,以备不时之需。这种互补性关系可以提高能源系统的可靠性和稳定性。
-
独立参加多级市场: 抽蓄电站可以在能源市场的不同层次(多级市场)中独立参与。这可能包括能源交易市场、辅助服务市场等。独立参与多级市场意味着抽蓄电站具有一定的灵活性和自主性,可以根据市场需求进行运营和交易。
-
抽蓄电站容量分配策略: 这指的是制定和实施抽蓄电站在能源系统中的容量分配策略。容量分配策略可能涉及到确定抽蓄电站的装机容量、分配储能资源的使用比例,以及在不同市场中分配其能力的方法。这种策略的设计需要考虑到系统的需求、市场机制、新能源波动性等多方面因素。
总体而言,这个标题表明研究的焦点是在新能源和抽蓄电站之间找到一种有效的协同关系,并且关注抽蓄电站如何灵活地参与多个能源市场,以最大化其在整个能源系统中的效用。容量分配策略则是关键的研究方向,涉及到如何合理配置抽蓄电站的资源,以适应不同层次市场的需求。
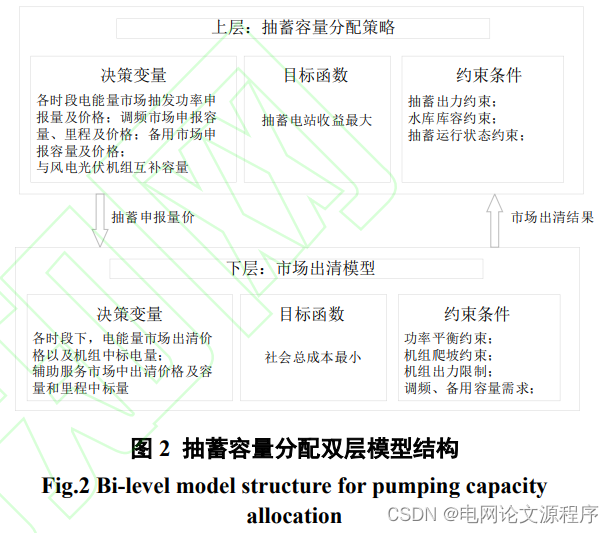
摘要:我国部分区域已构建含风光水蓄的互补联合电站,随着电力现货市场的发展,现行两部制电价下抽水蓄能电站面临灵活调节能力价值难以体现,获利空间有限的问题。为此,本文提出一种与新能源互补以及独立参与电能量、调频和备用等多级市场的双模式下抽水蓄能电站容量分配策略。基于现货市场运行机制,考虑对手报价和新能源出力不确定性,构建了双模式下抽蓄容量分配双层模型,上层以抽蓄收益最大为目标做出容量分配决策,其中,互补模式下抽蓄电站与风电光伏机组以约定价格形成联合体;下层以社会总成本最小为目标进行主辅市场联合出清。采用多场景的方法描述风光出力波动带来的收益风险,并通过双层智慧型自适应粒子群算法对模型进行求解。算例仿真结果证明,抽蓄采用本文提出的容量分配策略,参与市场竞争的收益比两部制电价收益有明显提高,互补模式降低新能源发电机组因出力波动产生的考核费用的同时增加抽蓄自身收益,降低了对容量电费的依赖性,为未来抽蓄电站成本回收和盈利提供理论参考。
这段摘要描述了一项研究,该研究关注我国部分地区已经建立的风光水蓄互补联合电站,以及由于电力现货市场的发展,现有的两部制电价制度下抽水蓄能电站面临的问题。文章提出了一种新的策略,旨在通过与新能源的互补性以及在不同电能市场(电能量、调频、备用等)中的独立参与,解决抽水蓄能电站在现行体制下难以体现其灵活调节能力价值和获利空间有限的问题。
具体而言,该研究基于电力现货市场的运行机制,考虑了对手报价和新能源出力的不确定性,提出了一个双模式下的抽蓄容量分配策略。这个策略采用了双层模型,上层以最大化抽蓄收益为目标,做出容量分配决策。在这个层面,互补模式下抽蓄电站与风电光伏机组形成联合体,以约定价格参与市场。下层以社会总成本最小为目标进行主辅市场的联合出清。
研究采用了多场景方法来描述风光能源出力波动带来的收益风险,并通过双层智慧型自适应粒子群算法对模型进行求解。仿真结果表明,采用本文提出的容量分配策略的抽蓄电站在市场竞争中的收益相较于两部制电价模式有明显提高。互补模式不仅降低了新能源发电机组因出力波动导致的考核费用,同时增加了抽蓄自身的收益,减少了对容量电费的依赖性。
总体来说,这项研究为未来抽水蓄能电站在新能源环境中的成本回收和盈利提供了理论参考,强调了通过灵活的市场参与和容量分配策略来提高抽蓄电站的经济效益。
关键词: 抽水蓄能电站;市场机制;辅助服务市场;联合出清;新能源互补;
-
抽水蓄能电站: 这是一种电力储能系统,它通过将水从低处抽升到高处来储存能量,然后在需要电力的时候通过释放水势来发电。这种技术在平衡电力供需、应对电力波动和提高电力系统灵活性方面具有重要作用。
-
市场机制: 指的是电力市场的运作方式和规则,其中包括电力定价、交易规则、市场参与者行为等。这与传统的固定电价体制不同,市场机制通常更加灵活,允许根据供需关系和其他因素动态调整电价。
-
辅助服务市场: 指提供电力系统稳定性和可靠性所需的附加服务的市场。这些服务包括调频、备用容量等,用于应对电力系统中突发的波动和变化。辅助服务市场对于支持可再生能源集成和电力系统运行的平稳性至关重要。
-
联合出清: 是指多个市场参与者(可能包括抽水蓄能电站、新能源发电站等)通过协作或联合参与电力市场,以达到更高效的市场清算和资源分配。这通常涉及参与不同市场层次,以实现更综合的系统优化。
-
新能源互补: 表示抽水蓄能电站与新能源发电站(例如风电和光伏发电)之间的协同作用。通过结合利用抽水蓄能的灵活性和新能源的可再生优势,可以提高整个系统的效率和可再生能源的利用。
这些关键词的结合表明研究关注了如何优化抽水蓄能电站在市场机制下的运行,特别是在辅助服务市场中的角色,以及通过与新能源互补的方式来提高效益。联合出清则强调了多层次、多市场的参与和协作,以实现更全面的系统优化。
仿真算例:
本文采取的算例系统包括火电机组 6 个,抽 蓄机组 1 个,风电、光伏各 1 个。各发电机组参 数、调频里程乘子和备用调用系数如附录表 A1 所示;机组在辅助市场中报价情况如附录表 A2 所示;风电和光伏发电场景聚类削减结果如附录 图 A1~A4 所示;系统中负荷与风电光伏出力预测 情况如图 4 所示;抽蓄电站与风光互补时,抽水 价格为144.5元/MWh,发电价格为358元/MWh; 风光偏差考核价格为 5 元/MWh;两部制电价下, 上网电价取标杆电价 350 元/MWh,抽水电价取 250 元/MWh。
仿真程序复现思路:
在日前计划中,使用多场景方法描述风电光 伏电站发电的不确定性。采用拉丁超立方抽样 (Latin hypercube sampling,LHS)方法,生成大 量服从概率分布约束的风电光伏出力场景,然后 采用考虑 Kantorovich 距离的场景削减方法对场 景进行削减。最后,导出具有相应概率的削减后 的场景。
仿真的复现思路主要包括以下步骤:
# 步骤 1: 定义系统参数和数据载入
num_fire_power_units = 6
num_pump_storage_units = 1
num_wind_power_units = 1
num_solar_power_units = 1fire_power_params = load_fire_power_params()
pump_storage_params = load_pump_storage_params()
wind_power_params = load_wind_power_params()
solar_power_params = load_solar_power_params()unit_bid_prices = load_unit_bid_prices()# 步骤 2: 设定价格和电价政策
pump_price = 144.5
generation_price = 358
deviation_penalty_price = 5benchmark_electricity_price = 350
pump_electricity_price = 250# 步骤 3: 生成风电光伏出力场景
import numpy as np
from pyDOE import lhsnum_scenarios = 1000wind_power_scenarios = lhs(2, samples=num_scenarios, criterion='center')
wind_power_scenarios = adjust_wind_power_scenarios(wind_power_scenarios)solar_power_scenarios = lhs(2, samples=num_scenarios, criterion='center')
solar_power_scenarios = adjust_solar_power_scenarios(solar_power_scenarios)# 步骤 4: 场景削减
from scipy.spatial.distance import cdisttarget_distribution = np.array([0.1, 0.2, ..., 0.01])distances = cdist(np.vstack((wind_power_scenarios, solar_power_scenarios)), target_distribution.reshape(1, -1), metric='cityblock')
selected_indices = np.argsort(distances.flatten())[:num_scenarios]selected_wind_power_scenarios = wind_power_scenarios[selected_indices]
selected_solar_power_scenarios = solar_power_scenarios[selected_indices]# 步骤 5: 仿真计算
for scenario in range(num_scenarios):current_wind_power = selected_wind_power_scenarios[scenario]current_solar_power = selected_solar_power_scenarios[scenario]# 根据当前场景和系统参数进行模拟计算# ...# 计算各项指标,比如成本、收益、市场交易等# ...# 输出仿真结果# ...
以上是一个整体的伪代码,包含了仿真程序的主要步骤。具体的实现需要根据问题的复杂性和具体要求进行详细编码,包括数据加载、场景调整、场景削减、仿真计算和结果处理等方面。
这篇关于文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《与新能源互补和独立参加多级市场的抽蓄电站容量分配策略》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





