本文主要是介绍使用Colossal-AI分布式训练BERT模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
最近几周在研究分布式训练中的模型并行技术。为了直观感受和加深记忆,阅读相关论文的同时,动手用开源的大模型训练框架Colossal-AI逐步改写出了一个数据并行+模型并行的BERT来帮助理解。在这里想介绍一下借助Colossal-AI提供的零冗余优化器、张量并行、流水线并行等技术一点点缩小BERT模型内存占用的过程。
文章内容:
-
大规模模型对分布式训练带来了什么挑战?什么是Colossal-AI?
-
用Colossal-AI提供的分布式技术训练BERT模型
- 数据并行
- 零冗余优化器
- 张量并行
- 流水线并行
-
实验
-
总结
背景知识
大规模模型训练
NLP领域中新的预训练模型不断对各种语言任务的效果做出了突破。这些预训练模型依赖于深而宽的网络结构来“记忆”某些语言表征,往往把模型的Layer增多增宽(参数量也随之变多)能进一步提升模型表现,因此近年来NLP模型的模型参数也越来越多。比如BERT论文中提到的BERT-base有1亿参数和BERT-large有3亿参数;最近的GPT-3和PaLM的large更是高达1750亿参数和5400亿参数。 大规模模型为分布式训练带来了新的挑战:过去单卡就能放下的小规模模型仅用数据并行就能达到优秀的性能和可扩展性;而如今单个模型甚至算子的参数量就超过了单卡内存,需要用更复杂的并行技术来将参数分布到各个节点多张卡上,使分布式训练能支持更大规模的模型训练。
Colossal-AI
Colossal-AI是一个专注于大规模模型训练的深度学习系统,Colossal-AI基于PyTorch开发,旨在支持完整的高性能分布式训练生态。Colossal-AI已在GitHub上开源,且多次登顶GitHub
trending榜单,感兴趣的同学可以访问我们的GitHub主页(https://github.com/hpcaitech/ColossalAI)。在Colossal-AI中,我们支持了不同的分布式加速方式,包括张量并行、流水线并行、零冗余数据并行、异构计算等。
简单的来说,就像我们借助PyTorch、Tensorflow等训练框架提供的方法来写单机模型训练一样,Colossal-AI旨在帮助用户像写单机训练一样去写大规模模型的分布式训练,并提供了PyTorch-like的接口和使用方式,使用户尽量无痛迁移目前的单机模型。
分布式加速方式
关于上面提到的各种优化技术,Colossal-AI官方文档有原论文地址和详细的探讨,这里不赘述,想了解细节的朋友移步我们的文档Paradigms of Parallelism | Colossal-AI。
Colossal-AI:从数据并行的BERT模型到模型并行的BERT模型
下面我们用一个PyTorch开发的BERT模型由易到难逐步实验各种优化技术的效果。 原始模型我们直接采用huggingface-BERT的BERTForMaskedLM,该模型用Masked Language Model单任务预训练BERT。Colossal-AI使用v0.1.0。参考Colossal-AI官方的初始化和engine文档,我们定义配置文件config.py,并用colossalai.launch和colossalai.initialize接口启动一个engine来运行BERTForMaskedLM训练。
下面展示一些 内联代码片。
1 import colossalai
2
3 colossalai.launch(config='./config.py', ...)
4
5 # define model, optimizer, dataloader, criterion just like using PyTorch
6 ...
7
8 engine, trainloader, testloader, _ = colossalai.initialize(
9 model=model,
10 optimizer=optimizer,
11 criterion=criterion,
12 train_dataloader=train_dataloader,
13 test_dataloader=test_dataloader,
14 )
15
16 for data, label in trainloader:
17 data, label = data.cuda(), label.cuda()
18 engine.zero_grad()
19 output = engine(data)
20 loss = engine.criterion(output, label)
21 engine.backward(loss)
22 engine.step()数据并行
首先实验数据并行。数据并行对于模型代码是非侵入式的,只需要正常启动colossal-AI engine即可,Colossal-AI默认会自动配置数据并行。由于GPU的数量等于数据并行大小 x 张量并行大小(default=1) x 流水线并行大小(default=1),Colossal-AI会根据张量并行和流水线并行配置自动配置数据并行。不传入自己实现的梯度处理器时,默认会使用PyTorch自带的DistributedDataParallel来做数据并行。所以我们的训练不额外添加任何config,在启动并传入了GPU Number=8后,已经自动启动了8卡数据并行。
零冗余优化器
其次实验零冗余优化器ZeRO。ZeRO也不需要修改任何原生模型代码,只需要我们配置config和在colossalai.zero.init_ctx.ZeroInitContext的上下文内创建模型,Colossal-AI会自动检测ZeRO相关配置然后管理模型训练过程中需要减少冗余的参数。
第一步是修改config文件,增加如下ZeRO配置表明我们要启动ZeRO,参数解释见注释。ZeRO更全面的设置参见ZeRO文档。
1 from colossalai.zero.shard_utils import TensorShardStrategy
2
3 zero = dict(
4 model_config=dict( #模型参数
5 offload_config=dict(device="cpu"), #在不参与计算时将模型参数卸载到CPU上,进一步减少显存开销
6 shard_strategy=TensorShardStrategy() #指定使用的切片策略,这里我们使用Colossalai默认策略、将每个张量均匀地分片到所有rank上
7 ),
8 optimizer_config=dict( #优化器参数
9 cpu_offload=True, #将优化器状态从 GPU 卸载到 CPU,以节省 GPU 的内存使用
10 initial_scale=2**5, #自动混合精度训练的初始scale
11 )
12 )
第二步是在Colossalai ZeRO上下文内创建模型,让Colossalai能管理原生的PyTorch模型。
1 from colossalai.zero.init_ctx import ZeroInitContext
2
3 zero_ctx = ZeroInitContext(
4 target_device=torch.cuda.current_device(),
5 #gpc.config is all things defined in config.py as a dict
6 shard_strategy=gpc.config.zero.model_config.shard_strategy,
7 shard_param=True,
8 )
9
10 ...
11
12 with zero_ctx:
13 model = build_model()
14
15 ...
16 # colossalai.initialize(...)
17 # start your train
这样我们就能启动Colossalai的零冗余优化器来减少原生模型的显存使用,也是非常便捷。
张量并行
然后实验张量并行。张量并行比起前两个优化技术稍微复杂一些,需要在config中配置和改动模型代码来使用。
第一步仍然是修改config文件,增加如下设置表明我们希望在传入的8卡上启动一个数据并行大小为4(自动配置)、张量并行大小为2的1D张量并行。
1 parallel = dict(
2 tensor=dict(size=2, mode='1d')
3 )
第二步我们需要更改模型代码。
-
首先是将原生BertForMaskedLM中的
torch.nn.Linear/LayerNorm/Embedding/Dropout以及损失函数torch.nn.CrossEntropyLoss替换成colossalai.nn.Linear/LayerNorm/Embedding/Dropout/CrossEntropyLoss。Colossalai提供的这些算子会根据当前配置的张量并行模式自动切分模型参数:如张量并行大小为2的1D模式下,一个Linear层6x8的weight张量会根据所在位置被切分为2个3x8或者6x4的张量,其输出结果张量也会相应的切分,并在forward和backward的过程中处理合并逻辑,从而完成自动张量并行。同样,只要在配置文件中修改合适的size和mode,方法会自动根据配置文件变更张量并行方式,非常方便。 -
因为Colossalai要求
colossalai.nn算子定义的顺序和forward调用的顺序一致来保证多个算子间输入输出切分的维度匹配,我们需要严格将所有colossalai.nn算子定义顺序按照实际使用顺序排序。 -
对于注意力算子中的qkv Linear算子做特殊处理。目前默认状态下,Colossal 1D Linear算子会尝试将qkv三个连续定义的
colossalai.nn.Linear算子划分成:q-按列切(col)|k-按行切(row)|v-col,预期三个Linear算子将会是q(k(v(input)))的计算路径,这样的计算路径下col-row-col的切分能保证运算形状正确。但这样不符合我们对qkv的实际使用期望。我们可以直接调用colossalai.nn.Linear1D_col手动指定1D按列切分来处理,这样可以在1D mode正确计算注意力。不过为了让模型代码能保持根据config适配1D、2D、2.5D和3D的能力,我们可以选择将qkv直接合并为一个size*3的colossalai.nn.Linear算子,然后在forward计算中再重新chunk成3份来表示qkv,避免k在1D下被误切分为row。
1 def __init__(self, ...):
2 ...
3 self.query_key_value = colossalai.nn.Linear(hidden_size,
4 num_attention_heads * attention_head_size * 3)
5 ...
6
7 def forward(self, ...):
8 ...
9 qkv = self.query_key_value(hidden_states)
10 q, k, v = torch.chunk(qkv, 3, dim=-1)
11 ...-
对于模型最后一层Head使用的Linear层,调用特殊算子
colossalai.nn.Classifier替换。Classifier对于Bert的MLM任务输出会做vocab切分并行,也就是将num_class维度切分。得到的输出再交给同样对vocab做切分并行的colossalai.nn.CrossEntropyLoss计算loss。到这里,大部分使用Colossal做张量并行的工作已经完成,已经可以运行切分逻辑最简单的1D张量并行。 -
接下来我们对attention mask的维度做微调,来确保1D、2D、2.5D和3D张量并行时候注意力计算都能正确。对于多维(>1D)的张量并行,为了保证模型切分后计算的正确性,需要将attention mask先用
colossalai.nn.partition_batch从batch维度切分,并从[partition_batch_size, seq_length]reshape为[partition_batch_size, 1, 1, seq_length],这样计算注意力时可以广播成[partition_batch_size, num_heads, from_seq_length, to_seq_length],以便于多维张量并行计算。最后的转化dtype是因为我们这里的初始化赋值有可能改变attention mask的dtype,需要转化为原本的dtype。
1 extended_attention_mask = attention_mask.view(batch_size, -1)
2 extended_attention_mask = col_nn.partition_batch(extended_attention_mask)
3 extended_attention_mask = extended_attention_mask.unsqueeze(1).unsqueeze(2)
4 extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
5 extended_attention_mask = extended_attention_mask.to(dtype=embedding_output.dtype)
这样我们就改写了一个1D、2D、2.5D和3D支持张量并行的Colossal Bert模型,并可以通过config文件灵活更改张量并行大小和方式。通过张量并行,我们能将算子和模型分布到多张GPU上,减少显存开销。
流水线并行
最后实验流水线并行。流水线并行需要配置config、修改模型、使用Colossalai封装的高级API trainer代替engine训练。新版本Colossalai流水线并行的接口做了简化,请参考Pipeline Parallel | Colossal-AI。 配置config,启动一个2阶段的流水线并行:
1 parallel = dict(
2 pipeline=2,
3 )
流水线并行对原生模型的主要修改是要切分每个流水线阶段应该执行的逻辑。这里的BertForMaskedLM修改可以通过让Embedding只被first执行,输出token分类结果只被last执行,然后将中间的Encoder Layers切分给各流水线阶段完成:
1 class PipelineBertForMaskedLM(nn.Module):
2 def __init__(..., first, last):
3 ...
4 self.first = first
5 self.last = last
6
7 if self.first:
8 ...
9 # The logic will be executed only in the first stage
10
11 ...
12 # The logic will be executed in every pipeline stage
13
14 if self.last:
15 ...
16 # The logic will be executed only in the last stage
17 ...
18
19 def forward(
20 ...
21 ):
22 ...
23 if self.first:
24 ...
25 # The logic will be executed only in the first stage
26
27 ...
28 # The logic will be executed in every pipeline stage
29
30 if self.last:
31 ...
32 # The logic will be executed only in the last stage
33
34 ...使用trainer替代engine来启动Colossalai训练。trainer是Colossalai提供的高级API,可以简化训练过程,并且为流水线并行的自动调度提供支持:
1 from colossalai.logging import get_dist_logger
2 from colossalai.trainer import Trainer, hooks
3
4 # build components and initialize with colossalai.initialize
5 ...
6
7 # create a logger so that trainer can log on the console
8 logger = get_dist_logger()
9
10 # create a trainer object
11 trainer = Trainer(
12 engine=engine,
13 logger=logger
14 )
15
16 # define the hooks to attach to the trainer
17 hook_list = [
18 hooks.LossHook(),
19 hooks.LRSchedulerHook(lr_scheduler=lr_scheduler, by_epoch=True),
20 hooks.AccuracyHook(accuracy_func=Accuracy()),
21 hooks.LogMetricByEpochHook(logger),
22 ]
23
24 # start training
25 trainer.fit(
26 train_dataloader=train_dataloader,
27 epochs=NUM_EPOCHS,
28 test_dataloader=test_dataloader,
29 test_interval=1,
30 hooks=hook_list,
31 display_progress=True
32 )
实验
实验环境为搭载8张GPU的小型服务器,每张显卡显存为16GB。 因为Colossal-AI可以通过配置文件灵活修改并行方式,我们可以通过构建不同的config来测试显存占用。config的取值如下:
1 数据并行大小DP size取值{1, 2, 4, 8}
2 张量并行大小TP mode和size取值{1, 1d: {2, 4, 8}, 2d: {4, 8}, 2.5d|depth=2: {8}, 3d: {8}}
3 流水线并行大小PP size取值{1, 2, 4, 8}
4 DP size * TP size * PP size = 8
5 零冗余优化器根据不使用,使用切片且卸载到CPU上,取值{F, T}
测试BERT-large在不同Colossal-AI并行配置下的单张GPU内存占用峰值:
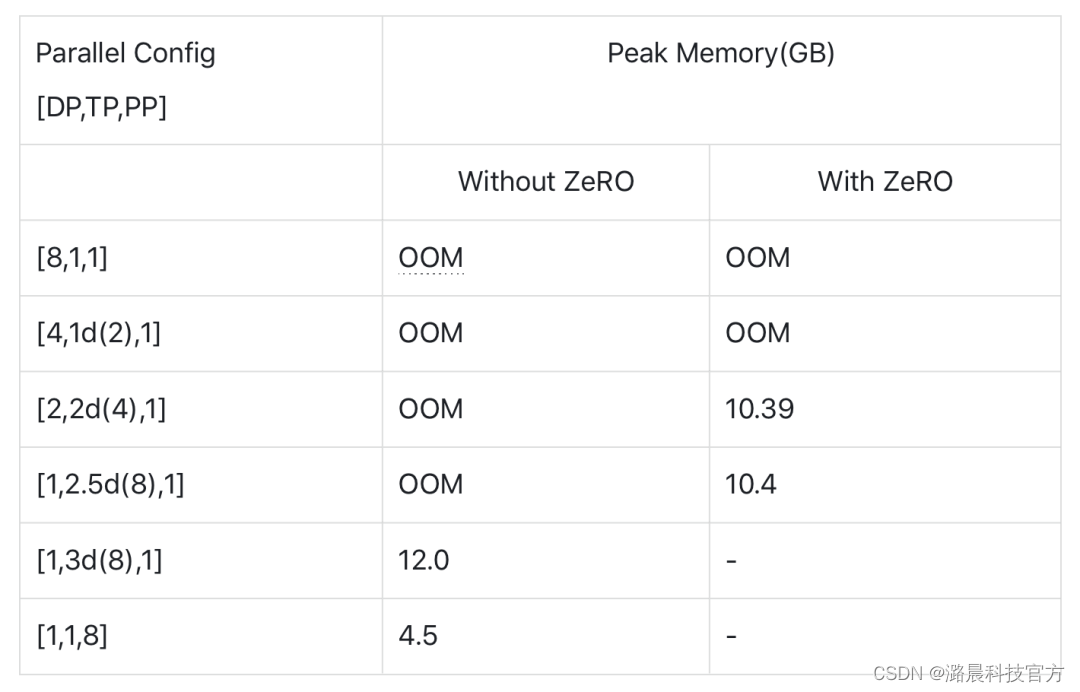 实验结果表明通过使用Colossal-AI提供的各类并行技术,能有效控制模型训练中的GPU内存使用,从而支持更大规模的规模的模型训练。
实验结果表明通过使用Colossal-AI提供的各类并行技术,能有效控制模型训练中的GPU内存使用,从而支持更大规模的规模的模型训练。
总结
- 大规模模型训练对分布式训练框架提出了更高的要求。
- Colossal-AI基于PyTorch提供了强大的数据并行、零冗余优化器、张量并行、流水线并行等训练技术,帮助用户尽可能简单地从单机训练模型迁移至分布式的训练模型。
- Colossal-AI能通过配置文件灵活地配置不同的混合并行策略,有效支持更大规模的模型训练。
项目团队
潞晨技术团队的核心成员均来自美国加州大学伯克利分校,斯坦福大学,清华大学,北京大学,新加坡国立大学,新加坡南洋理工大学等国内外知名高校;拥有Google Brain、IBM、Intel、 Microsoft、NVIDIA等知名厂商工作经历。公司成立即获得创新工场、真格基金等多家顶尖VC机构种子轮投资。
目前,潞晨科技还在广纳英才,招聘全职/实习AI分布式系统、架构、编译器、网络、CUDA、SaaS、k8s等核心系统研发人员,开源社区运营、销售人员。
潞晨科技提供有竞争力的薪资回报,特别优秀的,还可以申请远程工作。也欢迎各位向潞晨科技引荐优秀人才,如果您推荐优秀人才成功签约潞晨科技,我们将为您提供数千元至数万元的推荐费。
工作地点:中国北京,新加坡,美国。(可相互转岗)
简历投递邮箱:hr@luchentech.com
传送门
BERT项目地址:
https://github.com/hpcaitech/ColossalAI-Examples
Colossal-AI项目地址:
https://github.com/hpcaitech/ColossalAI
Colossal-AI文档地址:
https://www.colossalai.org/
这篇关于使用Colossal-AI分布式训练BERT模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







