colossal专题

浪潮信息AIStation与潞晨科技Colossal-AI 完成兼容性认证!
为进一步提升大模型开发效率,近年来,浪潮信息持续加强行业合作,携手业内头部,全面进攻大模型领域。日前,浪潮信息AIStation智能业务创新生产平台与潞晨科技Colossal-AI大模型开发工具完成兼容性互认证。后续,基于AIStation平台部署与调度的潞晨科技Colossal-AI系统,用户可实现在本地算力平台一键训练、微调、推理、部署大模型,将大模型开发效率提升10倍以上,并将算力效率提升2

Colossal Fibonacci Numbers! UVA - 11582
Colossal Fibonacci Numbers! UVA - 11582 The i’th Fibonacci number f(i) is recursively defined in the following way: • f(0) = 0 and f(1) = 1 • f(i + 2) = f(i + 1) + f(i) for every i ≥ 0 Yo
GPT系列训练与部署——Colossal-AI环境配置与测试验证
Colossal-AI框架主要特色在于对模型进行并行训练与推理(多GPU),从而提升模型训练效率,可快速实现分布式训练与推理。目前,该框架已集成很多计算机视觉(CV)和自然语言处理(NLP)方向的算法模型,特别是包括GPT和Stable Diffusion等系列大模型的训练和推理。 本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python

Colossal-AI简介
Colossal-AI为您提供了一系列的并行训练组件。我们的目标是支持您开发分布式深度学习模型,就像您编写单GPU深度学习模型一样简单。ColossalAI提供了易于使用的API来帮助您启动您的训练过程。为了更好地了解ColossalAI的工作原理,我们建议您按照以下顺序阅读本文档。 如果您不熟悉分布式系统,或者没有使用过Colossal-AI,您可以先浏览概念部分,了解我们要实现的目标同时掌握
Colossal AI 并行技术
简介 随着深度学习的发展,对并行训练的需求越来越大。这是因为模型和数据集越来越大,如果我们坚持使用单 GPU 训练,训练过程的等待将会成为一场噩梦。在本节中,我们将对现有的并行训练方法进行简要介绍。如果您想对这篇文章进行补充,欢迎在GitHub论坛上进行讨论。 数据并行 数据并行是最常见的并行形式,因为它很简单。在数据并行训练中,数据集被分割成几个碎片,每个碎片被分配到一个设备上。这相当
使用Colossal-AI云平台精调私有GPT
介绍 ChatGPT的出现展示了人工智能发展的潜力。通用数据集塑造的综合性大型语言模型在垂类领域中表现并不完美,存在幻想(AI Hallucination)等问题。要真正提升此类大语言模型在垂类领域的性能,应当使用高质量垂类数据集对模型进行精调。 目前,有大量企业客户想要将大模型能力融入日常业务,因而产生了对垂类大模型的迫切需求。大模型所能提供的快速有效地解决问题和生成回答的能力,可以帮助提高

Colossal-AI: A Unified Deep Learning SystemFor Large-Scale Parallel Training【深度模型分布式多核加速】
原文链接 一、摘要 1. 主要针对数据并行操作进行优化 parallel training system,主要针对的部分为 1)data parallelism 数据并行处理 2)pipeline parallelism 流水线并行 3)multiple tensor parallelism 多重张量并行 4)sequence parallelism 序列并行 二、Highli
Colossal-AI团队亮相全球超级计算机大会等多项国际盛会
近日,面向大模型时代的通用深度学习系统 Colossal-AI 连续入选和受邀全球超级计算机大会、国际数据科学会议、世界人工智能大会、亚马逊云科技中国峰会等多项国际专业盛会,并发表主题演讲,向众多参会者展示不断革新的高性能计算与人工智能前沿发展,及其在全面推动AI大模型民主化中的创新实践,敬请期待。 项目开源地址:https://github.com/hpcaitech/ColossalAI

霸榜GitHub热门第一多日后,Colossal-AI正式版发布
大规模并行AI训练系统Colossal-AI,旨在作为深度学习框架的内核,帮助用户便捷实现最大化提升AI部署效率,同时最小化部署成本。 开源地址:https://github.com/hpcaitech/ColossalAI Colossal-AI一经开源便受到广泛关注,连续多日登顶GitHub热榜Python方向世界第一,与众多已有数万star的明星开源项目一起受到海内外关注! 经过开发者们

Colossal Fibonacci Numbers! 数学
题意:输入两个非负整数 a,b 和正整数 n (0<=a,b<2^64 , 1<=n<=1000) 求斐波拉数f(a^b)%n 的值 其中f(0)=0 f(1)=1 分析: 斐波拉契数列规律:所有数对n取模,二元组( f(i),f(i+1) ) 有 n*n 种组合 则必有重复 ( f(i),f(i+1) ),导致数列循环 可转化为 => a^b 对 循环周期time取模的问题 其中0~2
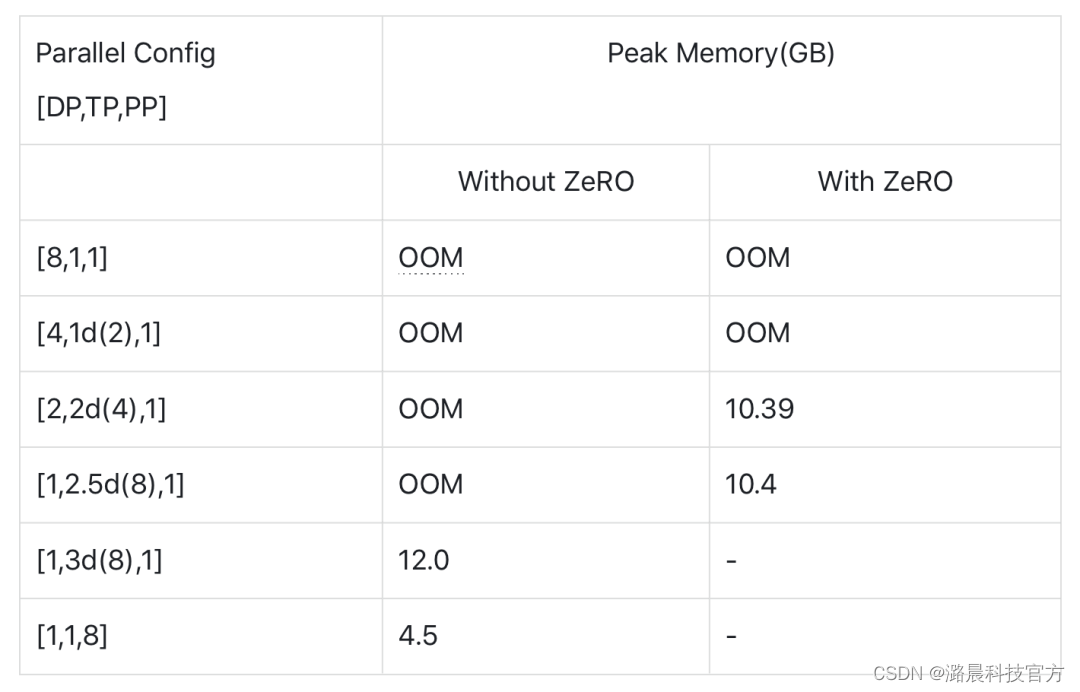
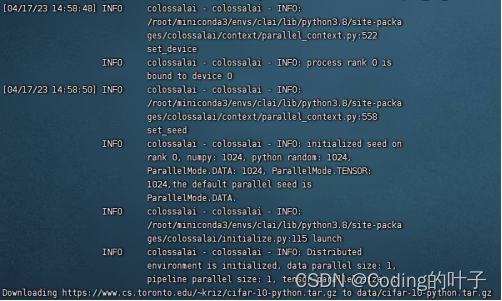
使用Colossal-AI分布式训练BERT模型
前言 最近几周在研究分布式训练中的模型并行技术。为了直观感受和加深记忆,阅读相关论文的同时,动手用开源的大模型训练框架Colossal-AI逐步改写出了一个数据并行+模型并行的BERT来帮助理解。在这里想介绍一下借助Colossal-AI提供的零冗余优化器、张量并行、流水线并行等技术一点点缩小BERT模型内存占用的过程。 文章内容: 大规模模型对分布式训练带来了什么挑战?什么是Coloss

开源星「001号」落地 Colossal-AI,欢迎登陆赢神秘大礼包!
前言:今年 5 月 6 日,腾讯·腾源会社区联合 Colossal-AI 等在内的 80 余家开源社区、国内外开源基金会等,共同发起「开源摘星计划」。开展 3 月以来,我们累计为近百位优秀摘星贡献者,送出激励大礼包 300 余份;同时为 700 位的开源爱好者搭建了共同的交流乐园,帮助很多人完成了从开源萌新到「过来人」的成长、蜕变。 今天,「开源摘星计划」继续「001号」任务探索,船长登陆,希望

Colossal-AI的安装
最近在学习stable diffusion model,但是这个模型成本比较高,作为低端学习者,借助colossal-ai加速训练,即能满足显卡要求又能节约时间。 Colossal-AI 是一个集成的大规模深度学习系统,具有高效的并行化技术。该系统可以通过应用并行化技术在具有多个 GPU 的分布式系统上加速模型训练。该系统也可以在只有一个 GPU 的系统上运行。 Colossal-ai的安装
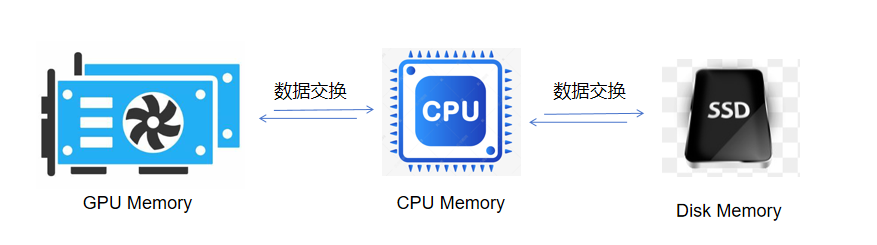
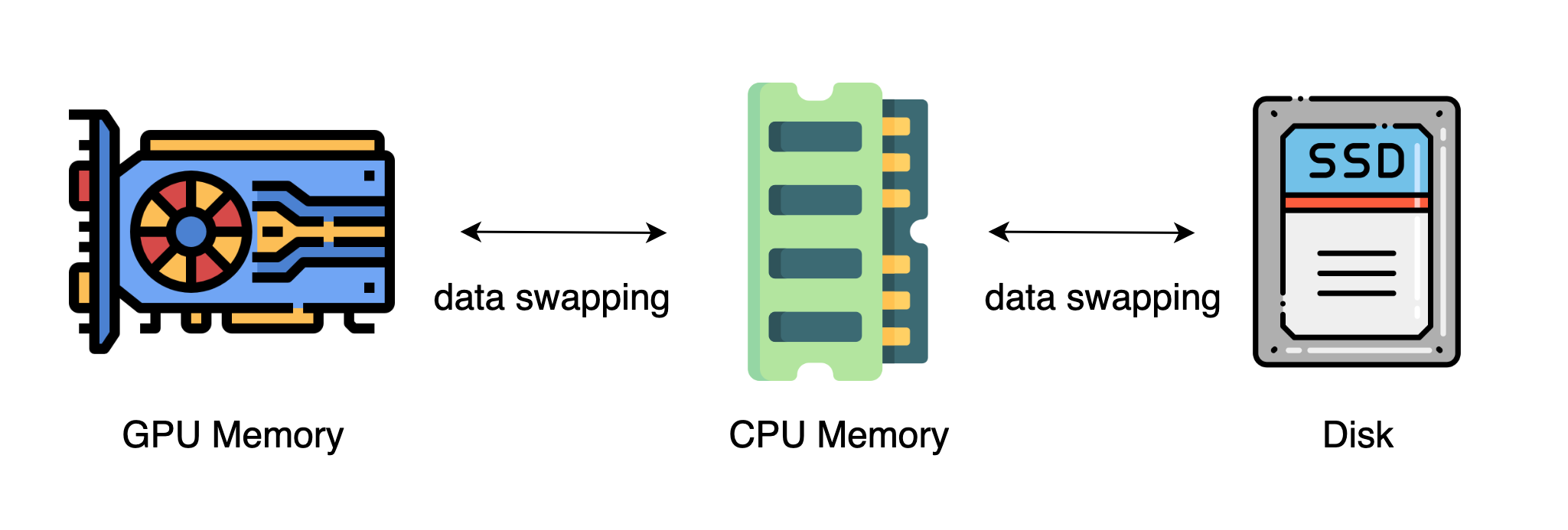
极智AI | Colossal-AI高效异构内存管理系统
欢迎关注我的公众号 [极智视界],获取我的更多经验分享 大家好,我是极智视界,本文来介绍一下 Colossal-AI高效异构内存管理系统。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq 首先需要了解一下异构内存中的数据移动,由于 GPU 的内存容量有限,一般没有办法直接容下大模型,这样的话可以使用
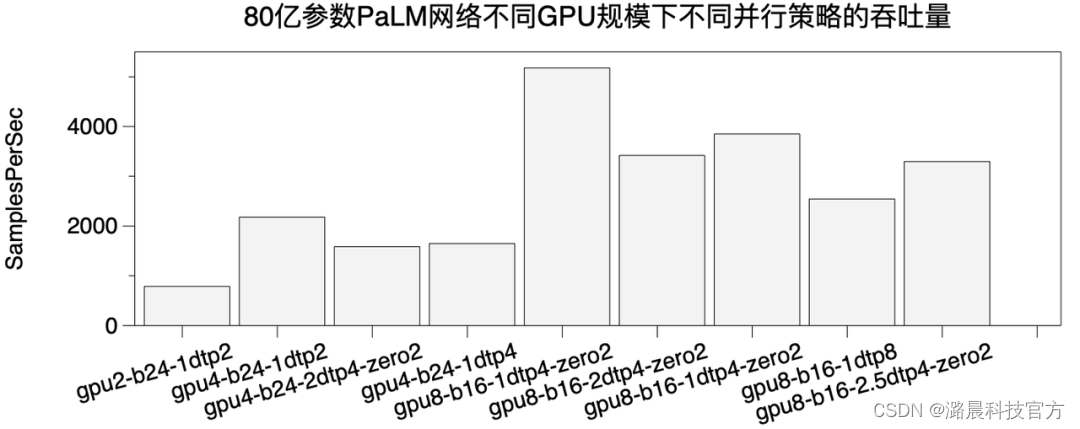
使用Colossal-AI复现Pathways Language Model
Google Brain的Jeff Dean在2021年提出了Pathways的设想,这是一个为未来深度学习模型而设计的系统。在前不久,Google终于放出了关于Pathways的第一篇论文《Pathways: Asynchronous Distributed Dataflow for ML》 以及使用TPU Pod在Pathways上训练的第一个模型PaLM (Pathways Language

Colossal Fibonacci Numbers!
题意 给定a,b,c.求fib(a ^ b) % c 显然a ^ b 非常大,而且直接fib(a ^ b)是行不通的 解题背景 我们首先知道(1 到 n) % m,在n足够的的时候会出现循环的。当对m取模的时候最大在 m*m之前会出现循环。我们知道(m + n) % mod == (m % mod + n % mod) % mod;所以可得fib[n] % mod = (fib[n - 1

模的应用--uva11582 Colossal Fibonacci Numbers!
For each test case, output a single line containing the remainder of f(ab) upon division by n. 0 ≤ a,b < 264(a and b will not both be zero) and1 ≤ n ≤ 1000. 思想很巧妙,求f(a ^ b) % n,斐波那契数列极大
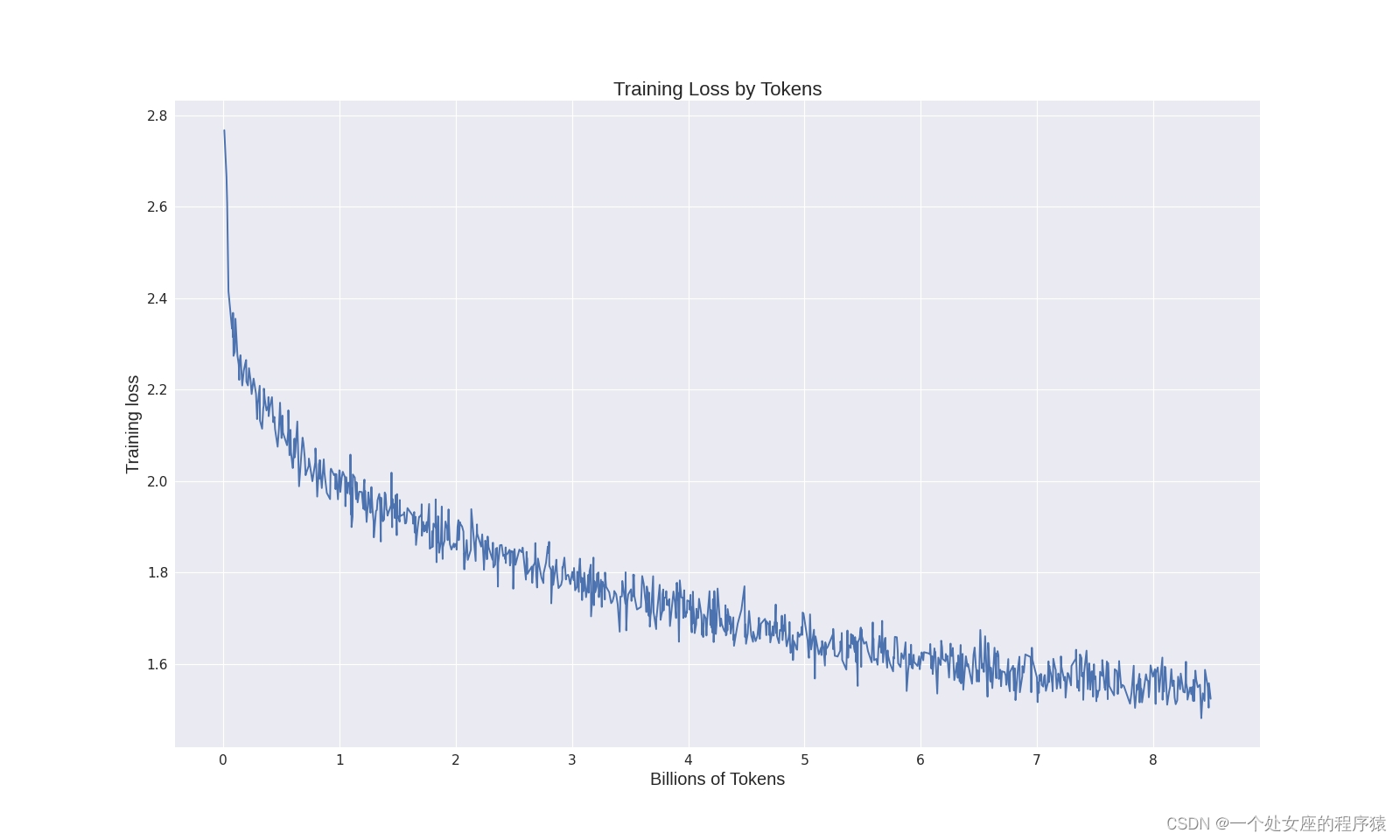
LLMs之Colossal-LLaMA-2:Colossal-LLaMA-2的简介(基于LLaMA-2架构+中文优化+扩充词表+仅千美元成本)、安装、使用方法之详细攻略
LLMs之Colossal-LLaMA-2:Colossal-LLaMA-2的简介(基于LLaMA-2架构+中文优化+扩充词表+仅千美元成本)、安装、使用方法之详细攻略 导读:2023年9月25日,Colossal-AI团队推出了开源模型Colossal-LLaMA-2-7B-base = 8.5B的token 数据+6.9万词汇+15 小时+不到1000美元的训练成本。Colossal-LL
极智AI | Colossal-AI高效异构内存管理系统
欢迎关注我的公众号 [极智视界],获取我的更多经验分享 大家好,我是极智视界,本文来介绍一下 Colossal-AI高效异构内存管理系统。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq 首先需要了解一下异构内存中的数据移动,由于 GPU 的内存容量有限,一般没有办法直接容下大模型,这样的话可以使用

Colossal Fibonacci Numbers!(裴波那切数列性质)
题意:就是让你求f(a^b)%n。数据大,很明显暴力是不可能的,这辈子都不可能的… 思路:裴波那切数列有一个性质,尾数循环。 斐波那契数列的个位数:一个60步的循环 最后两位数是一个300步的循环 最后三位数是一个1500步的循环 最后四位数是一个15000步的循环 最后五位数是一个150000步的循环 求出对应的循环周期,问题就变成了快速幂取模了。 #include<stdio