本文主要是介绍使用Colossal-AI复现Pathways Language Model,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Google Brain的Jeff Dean在2021年提出了Pathways的设想,这是一个为未来深度学习模型而设计的系统。在前不久,Google终于放出了关于Pathways的第一篇论文《Pathways: Asynchronous Distributed Dataflow for ML》 以及使用TPU Pod在Pathways上训练的第一个模型PaLM (Pathways Language Model)。相比传统Transformers结构,PaLM做了一些大胆的创新,相信很多小伙伴已经迫不及待想尝鲜一下PaML的效果,但是又苦于无法实现复杂的并行策略。团队使用PyTorch实现了PaLM的模型结构,并应用ZeRO,模型并行,数据并行等方法,将其扩展到多GPU。
PaLM代码现已开源在:
https://github.com/hpcaitech/PaLM-colossalai
关于Colossal-AI
Colossal-AI是一个专注于大规模模型训练的深度学习系统,Colossal-AI基于PyTorch开发,旨在支持完整的高性能分布式训练生态。Colossal-AI已在GitHub上开源,且多次登顶GitHub Trending榜单,感兴趣的同学可以访问我们的GitHub主页:
https://github.com/hpcaitech/ColossalAI
在Colossal-AI中,我们支持了不同的分布式加速方式,包括张量并行、流水线并行、零冗余数据并行、异构计算等。在例子库里,我们已经提供了BERT, GPT以及ViT等支持混合并行的训练实例。这次,我们将Colossal-AI应用到PaLM的模型上,来支持不同并行策略的分布式训练。
关于Pathways
Pathways是Google开发的新一代机器学习系统,它是为了满足Google未来深度学习训练需求而重新设计的。想了解更多的同学可以阅读一流科技袁老师写的博客。由于Pathways的设计是面向类似TPU Pod的硬件和网络结构相对定制化的,并且很多核心组件也尚未开源,这给大家在GPU上体验PaLM模型效果造成了很大的障碍。而PaLM模型参数量巨大,采用传统的数据并行技术也已经无法其扩展到多个GPU。那能否用我们常见的GPU集群来尝鲜一下PaLM模型呢?潞晨科技的工程师们利用Colossal-AI给出了解决方案。
PaLM模型解读
比起常规的Transformer层,PaLM有以下几个重要的改动。
1.SwiGLU激活函数
SwiGLU是谷歌的一名研究员设计的激活函数,比起Transformer模型常用的ReLU、GeLU或者Swish,SwiGLU能实现更好的模型性能。
2.并行Transformer层
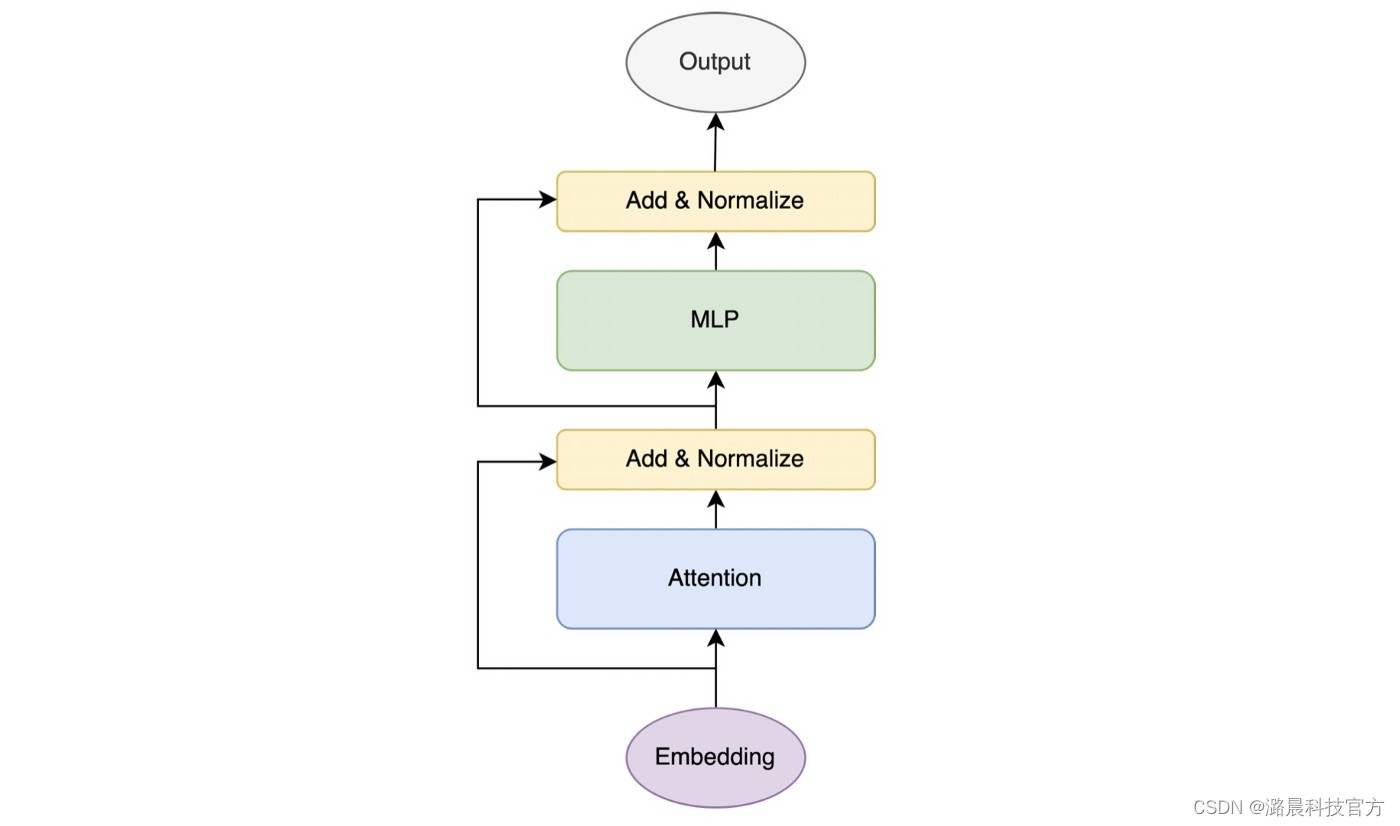
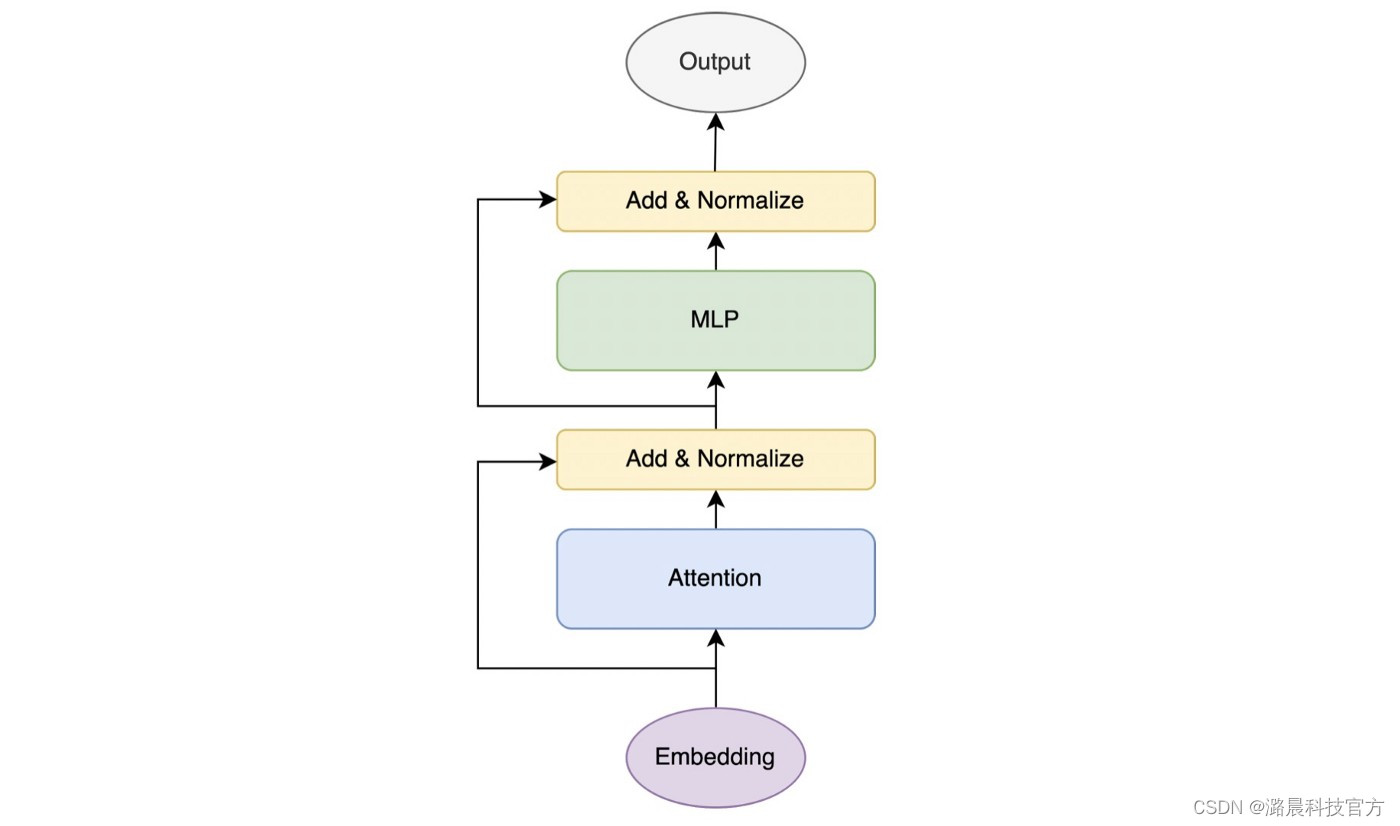
熟悉Transformer模型的同学都知道Transformer主要有attention和MLP两个模块。如上图,MLP模块通常接在attention模块之后。但是在PaLM中,为了追求计算效率,将Attention和MLP层合并到了一起。
正常的Transformer层可以表示为:
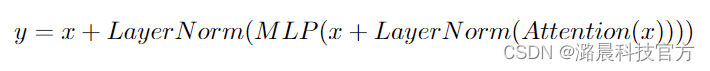
PaLM的Transformer层则表示为
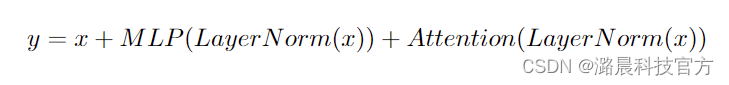
论文中提到MLP层和Attention层的第一个linear层可以融合,这可以带来大约15%的提升,但是我们发现MLP和Attention的第二个linear层也可以融合,能进一步提升计算效率。融合之后的模型架构可以用下面的架构图表示。
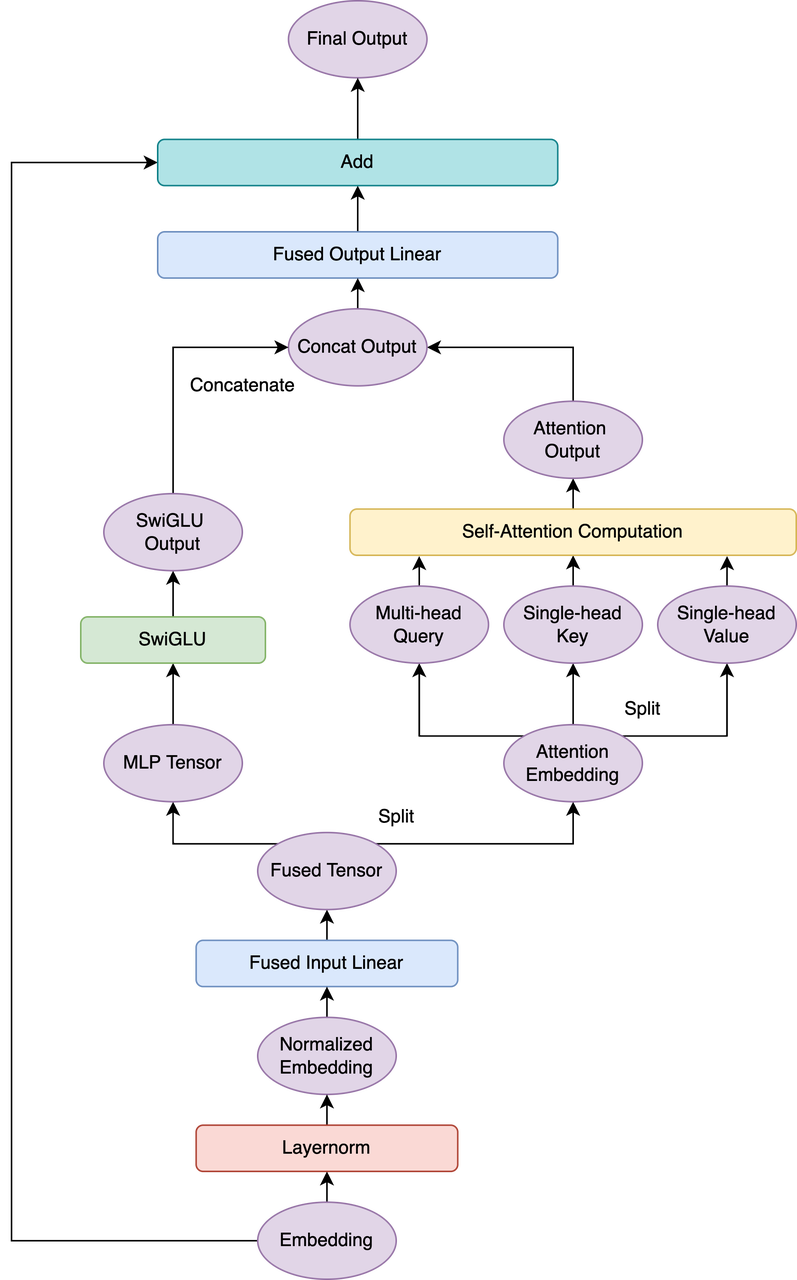
3.Multi-Query 注意力机制
与常规的多头注意力(multi-head attention)不同,PaLM中key和value都只有一头,只有query保持了多头,这样能够在不损失模型性能的情况下减少计算量,提升训练和推理的速度。在我们的实现中,提供了multi-query和multi-head两种机制。
4.linear和layernorm层均不使用bias,Google研究员声称这有利于模型的训练稳定。
我们根据论文描述,首先编写了单卡版本的PaLM。这里我们参考了如下repo的工作 :
https://github.com/lucidrains/PaLM-pytorch
Colossal-AI并行改造
在实现单卡串行版本的训练程序后,利用Colossal-AI,我们可以很容易地将训练过程扩展到多GPU并行。
张量并行改造
Colossal-AI支持了与PyTorch算子接口一致的并行算子,我们使用colossalai.nn.Linear去替换原生的torch.nn.Linear,这样能够允许运行时使用不同的张量并行(1D, 2D, 2.5D, 3D),想详细了解不同类型的张量并行的同学可以移步到Colossal-AI文档。
在对PaLM进行并行版本改造时,会遇到由其attention结构引起的一个特殊问题。张量并行会对query, key和value的最后一维进行切割(第一个维度根据并行模式可能会切,但是不影响计算,所以在下文会忽略),由于key和value为single-head,我们需要进行额外的通信来确保正确性。我们用B来表示batch size, S表示sequence length,H表示hidden size,N表示attention head的个数,A表示单个attention head的大小,P表示被切割的份数, 其中H = NA。
在非并行的情况下,我们的multi-head query张量大小为(B, S, H),single-head key和value的大小为(B, S, A),通过将query转换为(B, S, N, A),可以直接与key和value进行注意力计算。但是在并行情况下,query为(B, S, H / P),key和value为(B, S, A/P)。我们可以将query转化为(B, S, N/P, A),这样我们就可以在不同GPU上切割query的head维度。但是这样仍然不能进行计算,因为key和value上的值并不足以组成一个完整的attention head,所以需要引入额外的all-gather操作来组成一个完成head,即(B, S, A/P) -> (B, S, A)。如此一来,便能进行正常的注意力计算。
ZeRO并行
Colossal-AI可通过在配置文件里加入ZeRO相关配置,实现微软提出的ZeRO方式数据并行,并与上述不同张量并行方式混合使用。
异构训练
为了支持在单节点上进行大规模AI模型训练,我们实现动态异构内存管理机制,通过捕捉一个张量的生命周期,将张量在合适的时间放置在CPU或GPU上。相比DeepSpeed的ZeRO-offload,我们的方式可以减少CPU-GPU内存移动,并且更高效利用异构内存。
训练流程
在明确了优化手段后,我们可以直接定义一下配置文件(config.py),在配置文件中添加张量并行以及ZeRO的配置。

有了这个配置文件,我们就可以使用colossalai.initialize去初始化一个训练引擎,这个引擎提供了与PyTorch类似的常用API,这样就能使用Colossal-AI进行大规模训练了。

性能测试
我们在一台搭载8张A100 40GB GPU的单机多卡服务器上进行测试。该服务器使用NVLink将相邻成对的两张GPU高速互联,4对GPU之间采用PCI-E进行互联。
我们构造了一个80亿参数的PaLM结构网络,并使用混合并行策略(1D, 2D, 2.5D Tensor Parallel,ZeRO)去训练它。ColossalAI只需要通过零代码方式改动配置文件,就可以低成本的切换不同训练策略。下图中,b表示每个数据并行进程组的batch size,XXtpY表示tp并行策略,XX表示1D,2D,2.5D并行方案,Y表示TP的并行degree。zero表示ZeRO方式数据并行degree。数据并行degree X 模型并行degree=总的GPU数。
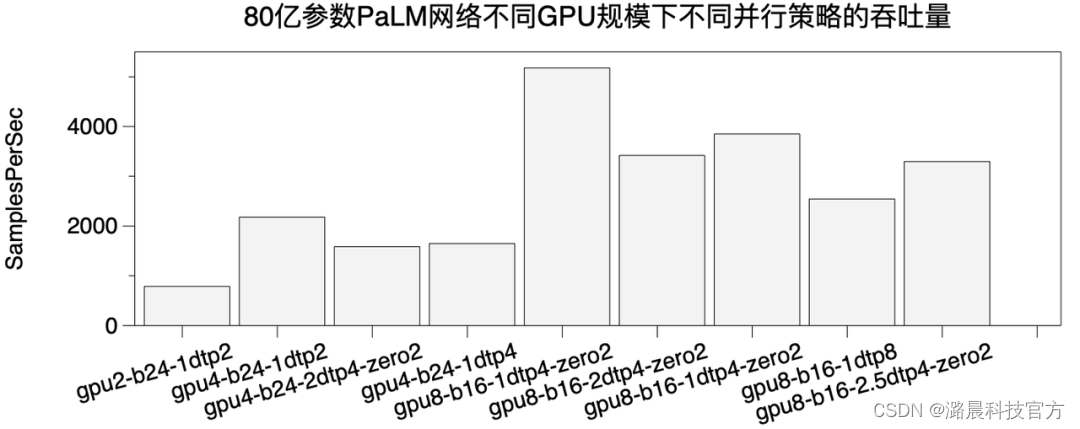
通过实验我们发现,异构训练是非常必要的,以上方案全部需要使用异构训练实现,如果不使用则无法成功运行80亿参数模型。
在2,4,8GPU情况下,我们发现1D TP degree为2效果最好。这是由我们的网络硬件拓扑决定的,因为相邻2个GPU之间通信带宽相对比较高,TP=2可以将大部分通信放在相邻GPU内。如果,在不同的网络硬件下,2D和2.5D会显示出更大的威力。ColossalAI通过简单的并行策略配置来快速适配不同的网络硬件。
总结
Colossal-AI团队根据Pathways的论文复现了PaLM的模型架构,由于计算资源的限制,很遗憾我们无法尝试复现论文中的千亿级参数模型结构。同时,目前Google原始版的PaLM并没有开源,所以我们的实现也可能和Google的官方实现有偏差。如果有任何疑问,欢迎大家在GitHub提出Issue或者PR,我们将积极尝试解答大家的问题。:)
项目团队
潞晨技术团队的核心成员均来自美国加州大学伯克利分校,斯坦福大学,清华大学,北京大学,新加坡国立大学,新加坡南洋理工大学等国内外知名高校;拥有Google Brain、IBM、Intel、 Microsoft、NVIDIA等知名厂商工作经历。公司成立即获得创新工场、真格基金等多家顶尖VC机构种子轮投资。
目前,潞晨科技还在广纳英才,招聘全职/实习AI分布式系统、架构、编译器、网络、CUDA、SaaS、k8s等核心系统研发人员,开源社区运营、销售人员。
潞晨科技提供有竞争力的薪资回报,特别优秀的,还可以申请远程工作。也欢迎各位向潞晨科技引荐优秀人才,如果您推荐优秀人才成功签约潞晨科技,我们将为您提供数千元至数万元的推荐费。
工作地点:中国北京,新加坡,美国。(可相互转岗)
简历投递邮箱:hr@luchentech.com
传送门
PaLM项目地址:
https://github.com/hpcaitech/PaLM-colossalai
Colossal-AI项目地址:
https://github.com/hpcaitech/ColossalAI
Colossal-AI文档地址:
https://www.colossalai.org/
参考链接:
https://arxiv.org/abs/2204.02311
https://arxiv.org/abs/2203.12533
https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
这篇关于使用Colossal-AI复现Pathways Language Model的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





