本文主要是介绍Feature Fusion for Online Mutual KD,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paper:Feature Fusion for Online Mutual Knowledge Distillation
official implementation:https://github.com/Jangho-Kim/FFL-pytorch
本文的创新点
本文提出了一个名为特征融合学习(Feature Fusion Learning, FFL)的框架,该框架通过一个组合并行网络特征图并生成更有意义特征图的融合模块(fusion module)高效的训练一个强大的分类器。具体来说,首先训练多个并行网络作为子网络,然后通过融合模块组合来自每个子网络的特征图得到一个更有意义的特征图,这个融合特征图送入融合分类器fused classifier中进行整体的分类。与现有的特征融合方法不同,该框架集成各个子网络的分类器ensemble classifier并将知识蒸馏到融合分类器中,同时融合分类器也将它的知识蒸馏回各个子网络中,以一种在线蒸馏online-knowledge distillation的方式进行互学习mutual learning。这种互学习的方式不仅提高了融合分类器的性能同时提升了各个子网络的性能。此外和其它一些类似方法相比,本文的方法中每个子网络的架构可以不同。
方法介绍
Fusion Module
和DualNet不同,本文的方法在融合特征时不是简单的求和或求均值,而是先concatenate不同子网络的特征,然后通过融合模块进行卷积操作。为了减少参数,使用了深度可分离卷积。我们使用最后一层的特征进行融合因为它特定于该任务并且具有足够的表示能力。假定子网络1,2的最后一层特征的通道分别为 \(C_{1},C_{2}\),拼接后特征图的通道数为 \(M=C_{1}+C_{2}\),融合模块的输出通道 \(N\) 可以根据需要设定。如图2所示,首先执行3x3的深度卷积,然后使用点卷积来创建特征映射切片的线性组合,以便更好的融合它们。
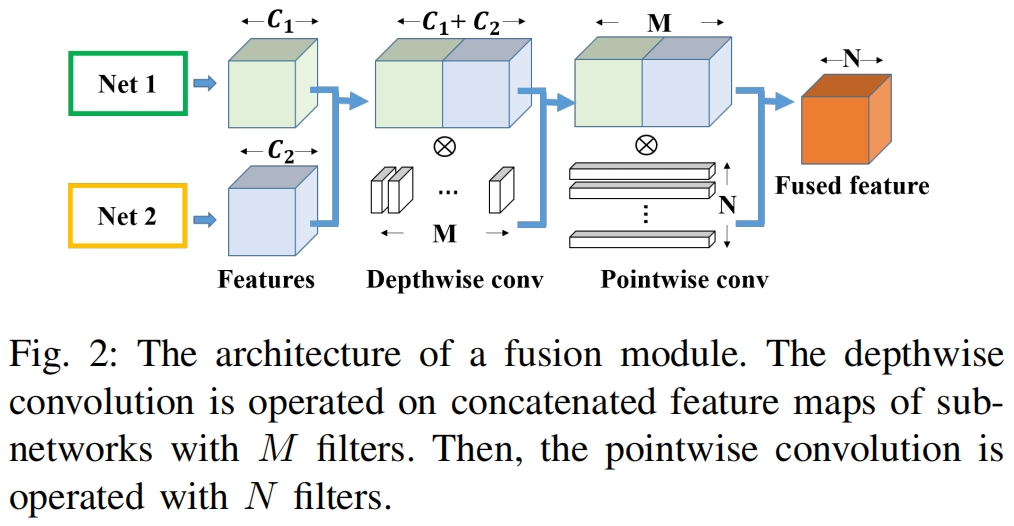
在DualNet中,存在一个问题,即子网络的输出通道数必须相等,因为特征图需要进行element-wise add。在本方法中,由于子网络的特征时concatenate的,因此FFL可以使用不同输出通道的网络作为子网络。如果子网络最后特征图的分辨率不同,那么使用一个卷积就可以对齐分辨率,如FitNets中的regressor。
Feature Fusion Learning

在子网络的结构方面,ONE(On-the-fly Native Ensemble)和DualNet都不够灵活因为它们的子网络的结构必须相同。为了解决这个问题,本文基于子网络的结构设计了两种不同的FFL
- 如果子网络的结构相同,则子网络的low-level层共享,high-level层分成不同的分支。
- 如果子网络的结构不同,则子网络分别独立训练因为无法共享层。
本文处理的多类别分类任务,假设有 \(m\) 个类别,第 \(k\) 个网络的logit定义为 \(\mathbf{z}_{k}=\left \{z^1_{k},z^2_{k},...,z^{m}_{k} \right \} \)。在训练过程中,我们使用softened probability进行模型泛化。给定 \(\mathbf{z}_{k}\),软化概率定义为

当 \(T=1\) 时,就是原始的softmax。给定one-hot标签 \(\mathbf{y}=\left\{y^{1},y^{2},...,y^{m}\right\}\),第 \(k\) 个子网络的交叉熵损失为

完整的过程如图1所示,其中子网络的结构不同。为了充分利用给定的知识,我们使用了一个强大的集成分类器。子网络通过集成logits创建一个集成分类器用来训练融合模块。假设有 \(n\) 个子网络,则logits的集成如下

为了训练融合模块,集成分类器将它的知识蒸馏给融合分类器,称为集成知识蒸馏(ensemble knowledge distillation, EKD)。EKD损失定义为集成分类器软化分布和融合分类软化分布之间的KL散度。如果融合分类器的logit定义为 \(\mathbf{z}_{f}\),则EKD损失如下

和其他方法相比,EKD损失可以帮助训练一个融合模块来生成更有意义的特征图。不同子网络最后一层特征图拼接后进入融合模块。为了训练每个子网络,融合模块中的融合分类器将它的知识蒸馏回每个子网络,称为融合知识蒸馏(fusion knowledge distillation, FKD)。将融合分类器的软化分布蒸馏回每个子网络的FKD损失如下
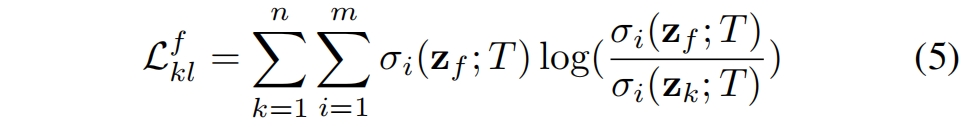
除了蒸馏损失,每个子网络和融合分类器还通过交叉熵损失学习ground truth,完整损失如下
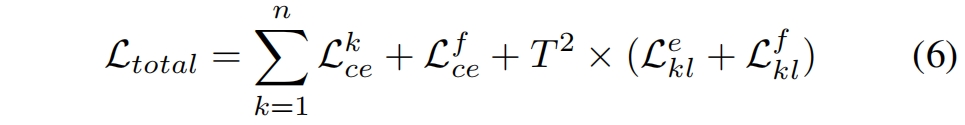
在FFL中,每个子网络和融合分类器通过交叉熵损失学习ground truth。同时,集成分类器通过 \(\mathcal{L}^{e}_{kl}\) 将它的知识蒸馏到融合分类器中,反过来,融合分类器也将它的知识蒸馏回每个子网络。通过这种互蒸馏(mutual knowledge distillation, MKD),融合模块生成对分类更有意义的特征。由于软分布的梯度缩放了 \(1/T^{2}\),我们乘上 \(T^{2}\)。FFL中的子网络和融合模块是同时训练的。
这篇关于Feature Fusion for Online Mutual KD的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![[LeetCode] 901. Online Stock Span](/front/images/it_default.gif)

