本文主要是介绍【爬虫实战】-爬取微博之夜盛典评论,爬取了1.7w条数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
TaoTao之前在前几期推文中发布了一个篇weibo评论的爬虫。主要就是采集评论区的数据,包括评论、评论者ip、评论id、评论者等一些信息。然后有很多的小伙伴对这个代码很感兴趣。TaoTao也都给代码开源了。由于比较匆忙,所以没来得及去讲这个代码。今天刚好使用这个代码去爬取了一些数据,刚好借着这个机会给大伙讲讲代码思路。
思路讲解:
其实这个代码比较简单,其实就是通过使用request这个python的库向目标url发送对应的请求,然后服务器在相应了请求以后,然后再给数据返回回来。然后我们再对对应的数据进行解析就可以了。
大体上如下图所示:
图画的有的地方不是特别严谨,还请见谅

代码讲解:
首先需要明确我们需要使用的类库,这里主要使用到的库如下:
import re # 进行数据正则化
import time # 跟时间有关,主要是为了请求休眠使用
import csv # 数据持久化,保存到csv
import random # 随机化数据
import requests # request请求的库,主要是为了发送请求
from datetime import datetime # 进行数据格式化,主要是为了对评论时间进行转换
from fake_useragent import UserAgent # 模拟各种浏览器,一种反反爬手段
这些库都是需要使用的,所以需要提前安装,安装方法,可以使用pip 进行安装,如果直接安装不上的话,可以使用清华镜像站进行安装,安装方法如下:
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple
然后就是登录weibo账号,然后找到对应的文章点进去,可以看到hotflow,这个其实就是评论的数据。我们点击它,然后就可以看到对应的cookie值了,然后复制它

之后需要给这个cookie值写在代码中,具体如下:
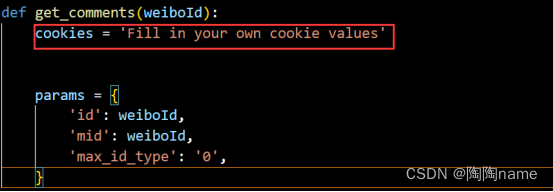
设置好cookie之后,就是需要给这个创建request请求了。我们还是回到之前的打开文章的界面复制url链接就可以了。
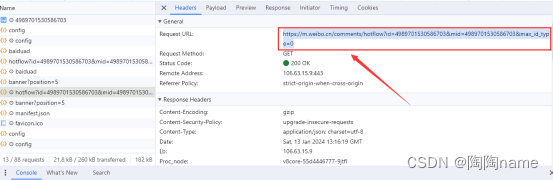
之后写如下的代码就完成了request请求的操作了,
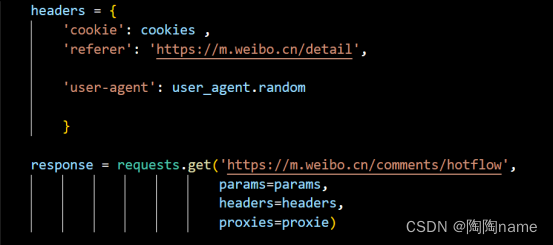
其实现在就可以获取到数据了,但是我们可以看一下,hotflow哪些是我们需要的数据。
可以看到我们需要的是like_count、source、text等这些数据


所以我们就需要写下面的代码对数据进行解析,至于为什么要写一个for循环,就是为了迭代多条数据。
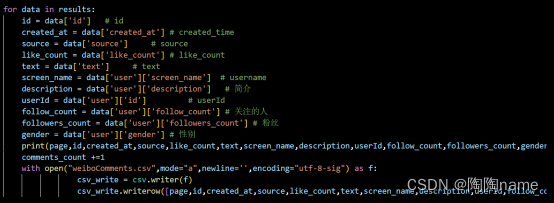
然后就是数据进行持久化了,持久化这里我这里使用的是csv,代码如下:
下面的这个是进行表格以及表头的创建

下面的是对数据进行保存的操作:

到这里基本上代码就已经写完了
爬取数据:
完成了上面的代码以后,我们就可以爬取数据了
首先我们需要找到需要爬取文章的id,获取方式如下
然后给这个id复制到代码的下面的位置就可以了
然后就可以爬取数据了,这里可以在pycharm或者cmd中执行都是可以的。我比较喜欢在cmd中执行代码,具体就是在cmd中使用python youcodeName.py就可以了。比较省事的方式其实就是使用pycharm直接run
下面是我在cmd中运行结束的截图
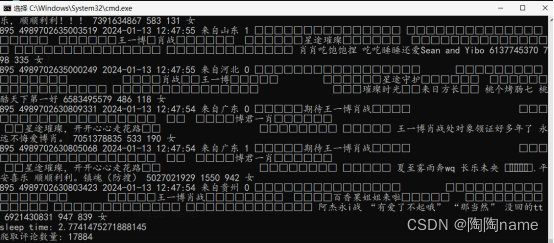
然后下面的是我爬取到的数据:


数据可视化:
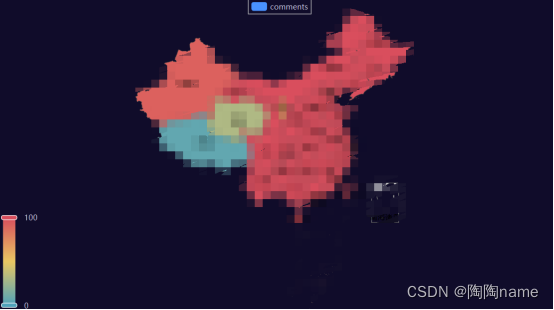
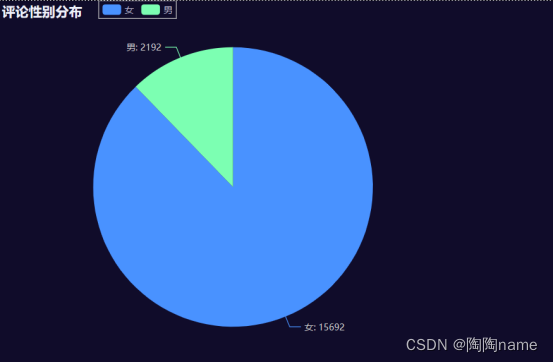
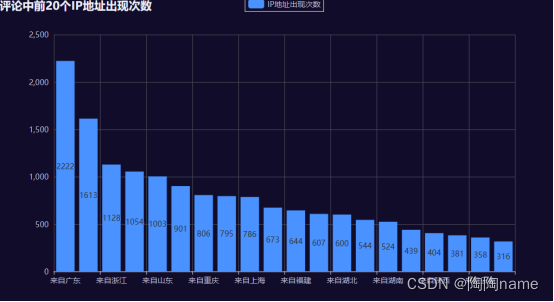
拿到了数据,其实我们还可以对数据进行可视化,这样方便观察数据的规律
TaoTao使用pyecharts简单的做了几个,仅供大家参考:
其实我们可以看到有重复数据。我看了一下评论区,其实是有人多刷的,就是说一个账号刷了多条同样的评论。我理解这些人可能是水军。


源码获取:关注“python小胡说”,回复“微博评论”既可获取源码!
希望大家可以动手实践,光说不练假把式!
由于TaoTao能力有限,在一些问题表述上难免有不准确的地方,还请多多包涵!
这篇关于【爬虫实战】-爬取微博之夜盛典评论,爬取了1.7w条数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






