本文主要是介绍主观世界模型的3类4组18个惊奇的理论分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:CreateAMind

摘要
令人惊讶的事件触发可测量的大脑活动,并通过影响学习、记忆和决策来影响人类行为。然而,目前对于惊喜的定义还没有达成共识。在这里,我们在一个统一的框架中确定了18个惊喜的数学定义。我们首先根据这些定义对主体信念的依赖程度,将它们从技术上分为三组,展示它们之间的关系,并证明在什么条件下它们是不可区分的。超越这种技术分析,我们提出了一个惊喜定义的分类法,并根据它们测量的数量将它们分为四个概念类别:
(I)“预测惊喜”测量预测和观察之间的不匹配;
(ii)“变化点检测惊喜”测量环境变化的概率;
(iii)“置信度修正的意外”明确说明了置信度的影响;以及
(iv)“信息获得惊喜”测量基于新观察的信念更新。该分类法为大脑中惊奇的功能作用和生理特征的原则性研究奠定了基础。
关键词:惊奇、预测误差、概率建模、预测大脑、预测编码、贝叶斯大脑

1.介绍
想象一下,某天早上你拉开窗帘,发现你公寓前的街道被新雪覆盖。根据天气预报,如果你期待一个温暖晴朗的早晨,当你看到白色的街道时,你会感到‘惊讶’;惊讶的结果是,你大脑中许多神经元的活动发生变化[Squires等人,1976年,Mars等人,2008年,Kolossa等人,2015年],你的瞳孔扩大[Antony等人,2021年,Preuschoff等人,2011年,Nassar等人,2012年]。惊喜影响着我们对未来的预测和感知,以及我们对过去的记忆。例如,一些研究表明,在下雪的早晨之后,你对未来计划的依赖会减少[等人,2007,Nassar等人,2010,Xu等人,2021]。其他研究预测,在你感到惊讶的那一刻,你会更生动地记得随机走过街道的陌生人的脸[鲁哈尼等人,2018年,鲁哈尼和尼夫,2021年],一些研究预测,这一惊讶的时刻甚至可能会修改你对过去另一个下雪早晨的记忆[格什曼等人,2017年,辛克莱和巴伦西]。为了理解和解释惊讶在不同大脑功能中的计算作用,我们首先需要问“惊讶到底意味着什么?”并形式化我们的大脑是如何感知惊喜的。例如,当你看到白色街道时,你是否会感到“惊讶”,因为你的预期结果是错误的[Meyniel等人,2016年,Faraji等人,2018年,Gl ascher等人,2010年]或者因为你需要改变对天气预报的信任[Baldi,2002年,Schmidhuber,2010年,Liakoni等人,2021年]?
感知、学习、记忆和决策的计算模型通常假设人类隐式地将他们的感官观察感知为具有隐藏变量的生成模型的概率结果[Yu和Dayan,2005,Friston,2010,Fiser等人,2010,Gershman等人,2017,Soltani和Izquierdo,2019,Findling等人,2021,Liakoni等人,2021]。在上面的例子中,观察值是是否下雪,隐藏变量描述了下雪的概率如何取决于旧的观察值和相关的上下文信息(如当前季节、昨天的天气和天气预报)。然后,在这种生成模型中将不同的大脑功能建模为统计推断和概率控制的方面[Yu和Dayan,2005年,等人,2007年,Gl ascher等人,2010年,Daw等人,2011年,Nassar等人,2012年,Gershman等人,2017年,Meyniel等人,2016年,Friston等人,2017年,Findling等人,2021年,Dubey和Griffiths,2019年,Liakoni等人在这些概率环境中,观察的惊奇程度取决于观察和我们对观察内容的预期之间的关系。
在过去的几十年里,人们提出并研究了不同的惊喜定义和正式衡量标准[巴尔迪,2002年,Gl ascher等人,2010年,施密德胡伯,2010年,弗里斯顿,2010年,帕尔姆,2012年,巴尔托等人,2013年,科洛萨等人,2015年,法拉吉等人,2018年,利亚科尼等人,2021年]。这些惊奇测量在解释惊奇在不同大脑功能中的作用[Itti和Baldi,2006年,Gershman等人,2017年,Xu等人,2021年,Rouhani和Niv,2021年,Antony等人,2021年,Findling等人,2021年]和识别行为和生理测量中的惊奇信号[Mars等人,2008年,Gl ascher等人,2010年,Rubin等人,2016年,modirsh然而,仍有许多未解决的问题,包括但不限于:(1)不同的惊奇定义所度量的量在概念上是否不同?(ii)我们能否确定不同惊喜定义之间的数学关系?特别是,一个定义是另一个定义的特例,完全不同,还是它们有一些共同点?
在这项工作中,我们在一个统一的框架中分析和讨论了先前提出的18种惊奇措施。我们首先在第2节介绍我们的框架、假设和符号。然后,在第3节到第6节中,我们给出了18个意外措施的定义,并展示了它们的相似性和差异性。特别是,我们确定的条件,使不同的惊喜措施实验难以区分。最后,在第7节中,我们基于我们的理论分析,通过将它们分为四个概念上不同的类别,提出了一个惊奇措施的分类法。
2.主观世界模型:一个统一的生成模型
我们的目标是在一个共同的数学框架中研究不同形式的惊奇测度的理论性质。为了做到这一点,我们需要假设一个主体(例如,一个人类参与者或者一个动物)如何思考它的环境。
我们假设一个主体认为它的观察是带有隐藏变量的生成模型的概率结果,因此,考虑一个生成模型,它捕捉日常生活的几个关键特征,并统一神经科学和心理学中许多现有的模型环境(参见2.2小节)。
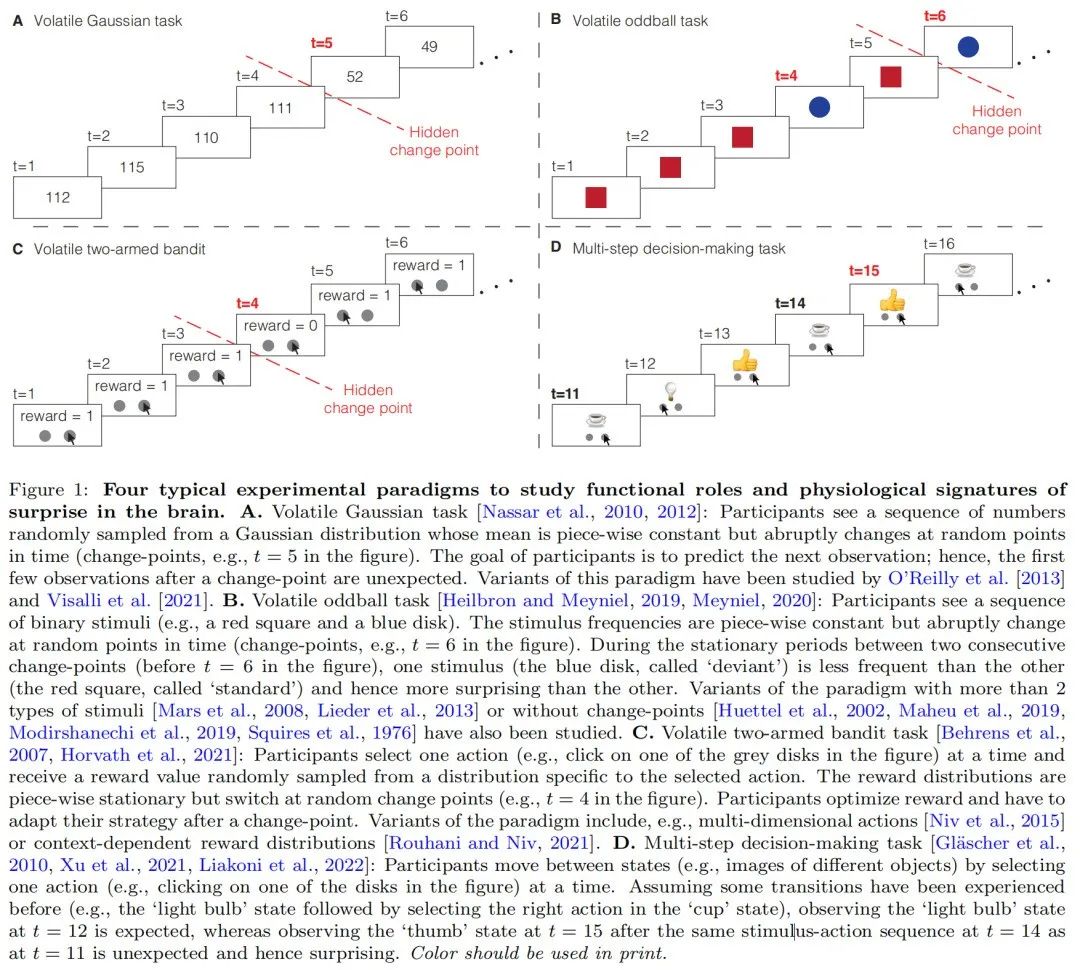
更具体地,我们假设生成模型从主体的角度描述了对环境的主观解释,并且重要的是,主体考虑了环境可能在未知时间点发生突然变化的可能性(即,环境是易变的),类似于等人[2007]、Nassar等人[2010]、Glaze等人[2015]、Heilbron和Meyniel [2019]、Xu等人[2021]、Maheu等人[2019]所研究的实验范式。参见图1,用于研究惊讶的行为和生理特征的四个典型实验范例。请注意,我们并不假设环境具有与代理所假设的相同的动态。
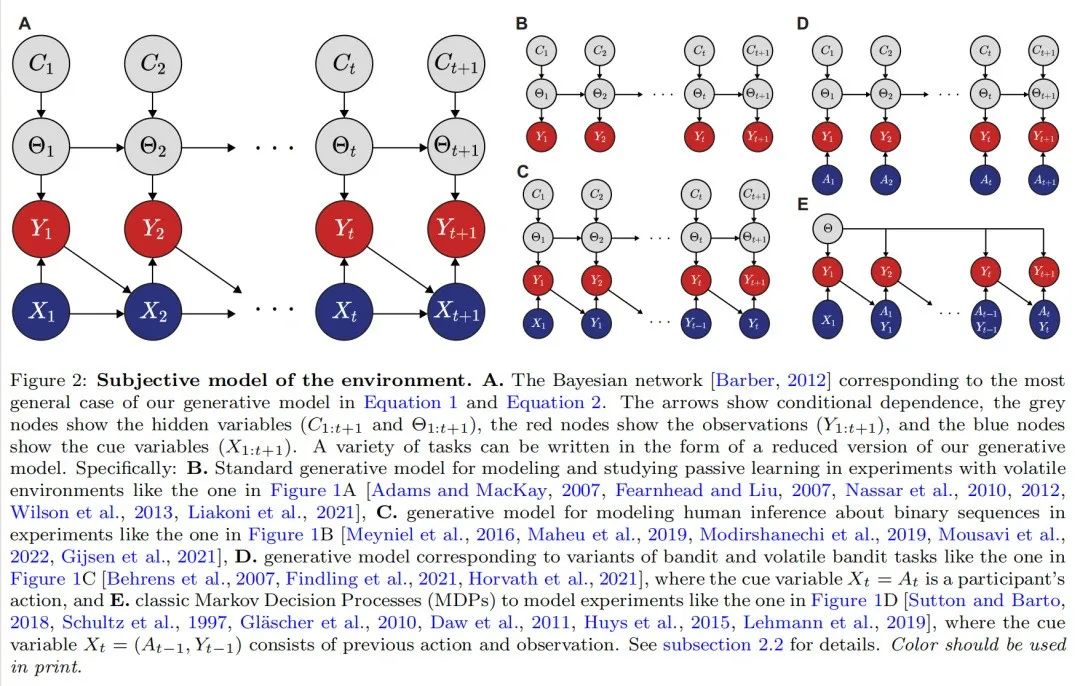
图2:环境的主观模型。a .贝叶斯网络[Barber,2012]对应于等式1和等式2中我们的生成模型的最一般情况。箭头显示条件相关性,灰色节点显示隐藏变量(C1:t+1和θ1:t+1),红色节点显示观察值(Y1:t+1),蓝色节点显示提示变量(X1:t+1)。各种各样的任务可以以我们的生成模型的简化版本的形式来编写。具体来说:b .用于在如图所示的易变环境的实验中建模和研究被动学习的标准生成模型[Adams和MacKay,2007,Fearnhead和Liu,2007,Nassar等人,2010,2012,Wilson等人,2013,Liakoni等人,2021],c .用于在如图所示的实验中建模人类对二进制序列的推理的生成模型[Meyniel等人,2016,Maheu等人,2019,Modirshanechi d .生成模型,对应于类似于图1C中的土匪和易变土匪任务的变量[伯伦斯等人,2007年,芬德林等人,2021年,霍瓦特等人,2021年],其中线索变量Xt = At是参与者的动作,以及e .经典马尔可夫决策过程(MDPs),以模拟类似于图1D中的实验[萨顿和巴尔托,2018年,舒尔茨等人,1997年,Gl ascher等人,2010年,道等人,2011年,Huys 详见第2.2小节。印刷时应使用颜色。


3. Surprise measures and indistinguishability
4. Probabilistic mismatch surprise measures
4.1. Bayes Factor surprise
智能体应该衡量在先前的信念下比在当前的信念下对新观察结果的预期高多少。贝叶斯因子惊喜是由 Liakoni 等人提出的。 [2021]量化这种惊喜的概念, 其动机是惊喜调节大脑的学习速度[Iigaya, 2016, Frémaux and Gerstner, 2016]。

4.2.香农惊喜及4.3强化学习状态转移跟4.1本质相同
4.2
不管是否有突变(Ct+1 = 1)或没有突变(Ct+1 = 0),不可能发生的事件都可能被认为是令人惊讶的。因此,另一种衡量观察结果的惊奇程度的方法是量化该观察结果在代理人眼中的可能性。香农惊喜,也被称为诧异[巴尔托等人,2013],是一种形式化这种惊喜概念的方式。它来自信息论[Shannon,1948]和统计物理学[Tribus,1961]领域,广泛应用于神经科学





7.惊喜定义的分类
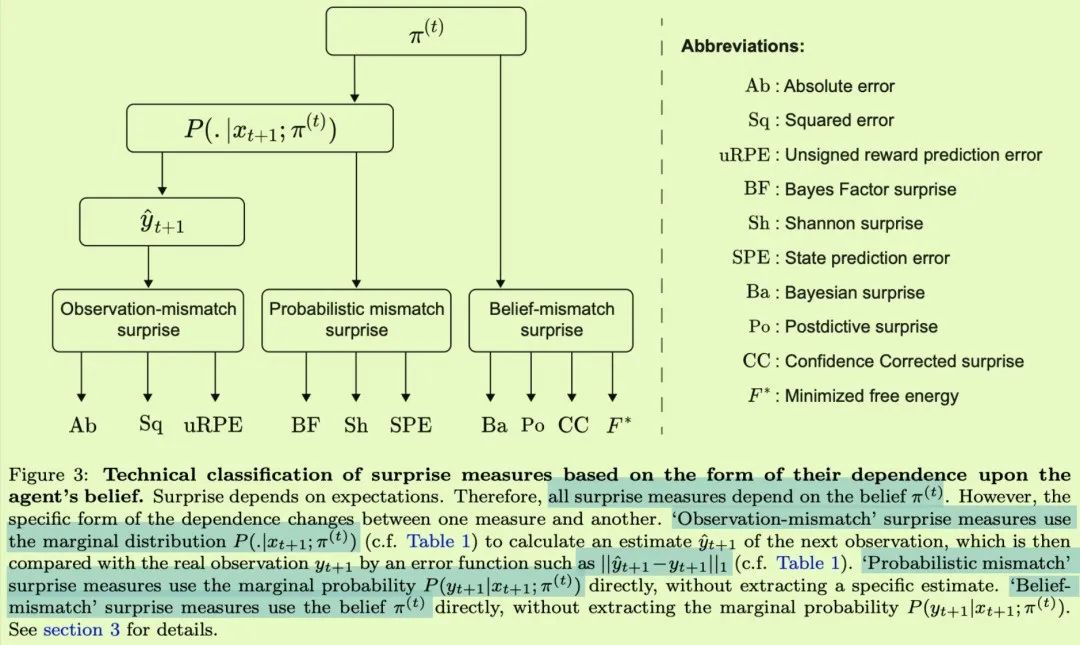
在一个统一的框架中,我们讨论了10个先前提出的措施的惊喜:(1)贝叶斯因素的惊喜;(2)香农的惊奇;(3)状态预测误差;(4)绝对误差和(5)平方误差惊奇;(6)未签约报酬预测误差;(7)贝氏惊奇;(8)表达后的惊讶;(9)信心修正后的惊喜;和(10)最小自由能。我们考虑了在不稳定的环境中定义这些度量的不同方法,并且总体上分析了18种不同的惊奇定义。在本节中,我们提出了这18个定义的分类法,并根据它们量化的语义将它们分为四个主要类别(图5)。
神经科学中的惊讶测量之前被分为两类[Hurley等人,2011,Faraji等人,2018,Gijsen等人,2021]:“困惑”和“启发”惊讶。困惑惊喜衡量的是一个新的观察对一个代理人来说有多困惑,而启发惊喜衡量的是这个新的观察给代理人带来了多少启发并改变了它的信念——这个概念与“啊哈![Kounios和Beeman,2009年,Dubey等人,2021年]。贝叶斯和事后惊奇可以归类为启发惊奇,因为两者都量化了信息增益(图5)。然而,基于我们的理论分析,我们建议将困惑惊讶的测量进一步分为3个子类别(图5

i.“预测惊奇”量化了新观察结果的不可预测、不可预料或不太可能的程度。这一类别包括香农惊奇、状态预测误差、最小化自由能和所有观察不匹配惊奇测量(图5)。根据这些度量,代理人的难题是找到下一次观测的最准确的预测。在自然语言中,惊讶被定义为“由意想不到的事情引起的感觉或情绪”[牛津英语词典,2021]。如果我们把注意力放在‘意外’这个词上,把它等同于‘在当前信念下不太可能’,而忽略了‘感觉’和‘情绪’这个词,那么预测惊喜所衡量的质量就和自然语言中对惊喜的定义密切相关。
ii.“变化点检测惊喜”量化了新观察的相对不太可能,旨在调整学习速率和识别环境变化。这一类别包括贝叶斯因素惊奇和香农惊奇的差异(参见推论1;图5)。根据这些措施,代理的难题是检测环境变化。
iii.“信心修正惊喜”明确解释了代理人的信心。这个想法是,更高的信心(或对信念的更高承诺)导致更多的困惑,其中的困惑要么是检测环境变化,要么是找到最准确的预测。Faraji等人[2018]利用一项思维实验认为,对信心的这种明确解释对于解释我们对惊喜的感知至关重要。这一类别目前仅有的候选者是SCC 1和SCC 2,它们假设智能体的难题是检测环境变化(参见命题9);但是我们预计将来会发现更多这类的例子。
虽然我们提出的分类法只是概念性的,并基于不同定义的理论属性,但我们注意到,已有大量研究调查了预测的神经和生理相关性[Mars等人,2008年,Kopp和Lange,2013年,Kolossa等人,2015年,Modirshanechi等人,2019年,Gijsen等人,2021年,Maheu等人,2019年,Meyniel,2020年,Mousavi等人,2022年,Konovalov 变点检测[Nassar等,2012,Xu等,2021,Liakoni等,2022],置信度修正[Gijsen等,2021],信息增益[Ostwald等,2012,Kolossa等,2015,Gijsen等,2021,Visalli等,2021,Nour等,2018,O'Reilly等,2013]惊奇测度(图1)。因此,我们推测,这些类别中的每一个至少有一个度量是在大脑中计算的,但可能通过不同的神经通路,并用于不同的大脑功能。
8.讨论
惊讶在形式上是什么意思?现有的惊喜定义是如何相互联系的?为了解决这些问题,我们在一个统一的数学框架中回顾了18个惊喜的定义,并研究了它们的相似性和差异性。我们表明,已知的安全措施的几个扩展到不稳定的环境是可能的和潜在的相关;因此,需要进一步的实验证据来阐明惊奇的精确定义与大脑研究的相关性。根据不同的定义如何依赖于信念π(t),我们将它们分为三组概率失配、观察失配和信念失配意外测量(图3)。然后,我们展示了这些度量在理论上如何相互关联,更重要的是,在什么条件下它们是彼此的严格递增函数(即,它们在实验上变得不可区分——图4和表2)。我们进一步提出了一个惊喜定义的分类法,从概念上分为四个主要类别(图5): (i)预测惊喜,(ii)变化点检测惊喜,
(iii)置信度校正的惊奇,和(iv)信息增益的惊奇。
人们认为,惊讶在不同的大脑功能中具有重要的计算作用,如自适应学习[Iigaya,2016,Gerstner等人,2018],探索[Dubey和Griffiths,2020,Gottlieb和Oud 2018],记忆形成[Rouhani和Niv,2021],记忆分段[Antony等人,2021]。我们的结果向理论家和计算科学家提出了一个多样化的工具包和一个精炼的术语,以模拟和讨论惊奇的不同功能及其生物学实现。例如,有人认为,观察-不匹配惊奇测度的计算在生物学上比香农惊奇等更抽象的测度更合理[Iigaya,2016]。我们的结果确定了这样的条件,在这种条件下,观察不匹配惊奇测量的行为与自适应学习最佳的概率不匹配惊奇测量的行为相同(参见图4B,命题1和推论1);这种见解可以在未来的适应性行为网络模型中加以利用。
此外,我们的结果可以用来设计新的理论驱动的实验,其中不同的惊喜措施做出不同的预测。重要的是,以前的大多数实验研究都集中在一种对惊奇的测量,以及它在行为和生理测量中的作用和特征。考虑一个以上意外测量的例子[Mars等人,2008年,Ostwald等人,2012年,Kolossa等人,2015年,Gijsen等人,2021年,Mousavi等人,2022年]主要集中在模型选择上
方法来比较不同的模型,并没有寻找这些措施的根本不同的预测-见Visalli等人【2021】的一个例外。即使两项令人惊讶的措施被正式宣布无效
值得注意的是,在一个给定的实验设置中,样本的数量或效应的大小不足以提取两者之间的定量差异。例如,对于除均匀分布以外的任何先验边缘分布,SBF和SSh1都是可区分的(图4B),但是,在实践中,对于几乎均匀的先验,这种区别很难检测到。我们的理论框架使我们能够走得更远,并设计实验,这些实验能够基于不同的预测质量来分离不同的惊奇测量,并避免不同测量在形式上或实际上不可区分的实验。
确认
AM感谢Vasiliki Liakoni、Martin Barry和Valentin Schmutz在过去几年中进行的许多有益的讨论,并感谢安德鲁·巴尔托在2021年EPFL神经研讨会期间和之后就“惊喜、好奇和回报:从神经科学到人工智能”进行的富有洞察力的讨论。本研究得到了瑞士国家科学基金会的资助(编号:200020 184615)。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

这篇关于主观世界模型的3类4组18个惊奇的理论分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






