本文主要是介绍NLP中文数据分析干货!!!——针对Chinese分析模版、苏宁空调评论分析实战(提供数据),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NLP中文数据分析
- 一、全套中文预处理代码
- 去掉文本中多余的空格
- 去除多余符号,保留指定中英文和数字
- 繁体转简体
- 分词
- 去除停用词
- 预处理封装
- 二、统计词频+词云图分析
- 统计词频
- 词云图分析
- 三、情感分析
- SnowNLP
- 情感分析实战
- 四、主题分析
- LDA前数据预处理
- LDA主题模型
- 五、实战演练-苏宁空调评论
- 获取数据
- 数据探索性分析(EDA)
- 绘制词云图
- 输出正负类主题分析
- 细节
- 六、代码开源
- CSDN开源
- Github开源
一、全套中文预处理代码
摘要:
这一套代码,对于每一步细分的功能一一写好了,下面的进一步操作可以对这套代码进行进一步封装,使用~
去掉文本中多余的空格
#输入句子,输出句子
import jieba
def process(sentence): #去掉文本中多余的空格new_sentence = sentence.replace(' ','') return new_sentence
去除多余符号,保留指定中英文和数字
#输入句子,输出句子
def clear_character(sentence): pattern = re.compile("[^\u4e00-\u9fa5^a-z^A-Z^0-9]") #只保留中英文和数字#替换为[^\u4e00-\u9fa5^,^.^!^a-z^A-Z^0-9] #只保留中英文、数字和符号,去掉其他东西line=re.sub(pattern,' ',sentence) #把文本中匹配到的字符替换成空格符new_sentence=' '.join(line.split()) #去除空白return new_sentence
繁体转简体
#输入句子,输出句子
from snownlp import SnowNLP
def complex_to_simple(sentence): #繁体转简体new_sentence = SnowNLP(sentence)new_sentence = new_sentence.hanreturn new_sentence
分词
#输入一个句子,将该句子分词后,返回一个列表
import jieba
def jieba_fenci(sentence):seg_list = jieba.cut(new_sentence,cut_all =True) #全模式seg_list = ' '.join(seg_list)jieba_fenci_list = [i for i in seg_list.split(' ')if i != '']return jieba_fenci_list
去除停用词
中文停用词表cn_stopwords.txt下载链接🔗
#输入一个句子列表的列表,返回处理后的句子列表的列表
def remove_word(sentence_list): #去除停用词stop = pd.read_csv('cn_stopwords.txt',encoding='utf-8',header=None,sep='tipdm',engine='python')stop_words = list(stop[0])stop_words +=['哈哈'] #根据自定义添加停用词remove_sentence_list = [[w for w in sentence if w not in stop_words]for sentence in sentence_list] return remove_sentence_list
预处理封装
#对前三个功能的封装,输入句子,返回句子,每个句子都是经过简单处理后的
def processing_chinese(sentence):sentence = process(sentence) #去除空格sentence = clear_character(sentence) #去除符号new_sentence = complex_to_simple(sentence) #繁体转简体return new_sentence
二、统计词频+词云图分析
统计词频
#计算词频,把所有句子的整个列表丢进来就行,输出一个字典形式的词频集
def compute_word_fre(sentence_list):sentence_list =[jieba.cut(processing_chinese(sentence),cut_all =True) for sentence in sentence_list] #分词sentence_list = remove_word(sentence_list) #去除停用词new_sentence_list = [[w for w in sentence if w!='']for sentence in sentence_list] #去除jieba分词空字符和停用词更新all_list=[]for i in new_sentence_list: all_list+=i #拼接处理后的句子word_fre ={} for word in all_list : #统计所有句子的全部词语的频率word_fre[word]=word_fre.get(word,0)+1return word_fre
词云图分析
设置参数:
mask=imread(‘cloud.png’,pilmode=“RGB”)设置为词云图背景,可以自定义图片
font_path=r"/System/Library/Fonts/STHeiti Medium.ttc"设置为本地中文字体路径

import matplotlib.pyplot as plt
from imageio import imread,imsave
from wordcloud import WordCloud, ImageColorGenerator, STOPWORDSwordcloud = WordCloud(background_color='white',collocations=False,mask=imread('cloud.png',pilmode="RGB"),max_words=30,random_state=2021,width=1200, height=800,font_path=r"/System/Library/Fonts/STHeiti Medium.ttc").fit_words(word_fre)# 绘制词云图
plt.imshow(wordcloud)
wordcloud.to_file("wordcloud.png")
#plt.savefig("other_wordcloud.png",dpi=600) #另一种保存形式
三、情感分析
SnowNLP
SnowNLP是一个经过大量数据训练得到的模型,可以进行三分类的预测任务,分别是正类、中性、负类,具体划分,我们可以通过定义阈值确定。
情感分析实战
# 加载情感分析模块
from snownlp import SnowNLP
from snownlp import sentiment
positive_sentence = '你真厉害,每个同学的妈妈都夸你,英雄联盟打得好,还带同学们去上王者'
print(SnowNLP(positive_sentence).sentiments)
#0.9999948382464556
neutral_sentence = '你好,哈哈'
print(SnowNLP(neutral_sentence).sentiments)
#0.5312500000000001
negative_sentence = '你真垃圾,大家都觉得你不行'
print(SnowNLP(negative_sentence).sentiments)
#0.04962917764338359
可以看到,通过得分可以看出,三类句子的不同,然后我们可以主观划分三类。
| 得分 | 类别 |
|---|---|
| 大于0.7 | positive正类 |
| 大于0.3,小于0.7 | neutral中性 |
| 小于0.3 | negative负类 |
四、主题分析
LDA前数据预处理
import gc
import tqdm
import numpy as np
from gensim import corpora, models, similarities
import time#LDA前数据预处理
def LDA_processing(sentence_list):sentence_list =[jieba.cut(processing_chinese(sentence),cut_all =True) for sentence in sentence_list] #分词sentence_list = remove_word(sentence_list) #去除停用词new_sentence_list = [[w for w in sentence if w!='']for sentence in sentence_list] #去除jieba分词空字符和停用词更新return new_sentence_list
LDA主题模型
设置参数:
num_topics = 3 #指定训练主题数
#输入处理好的句子,与分类主题数目,进行聚类训练
def LDA_model(sentence_list,num_topics=3):sentence_list = LDA_processing(sentence_list)sentence_dict = corpora.Dictionary(sentence_list) # 建立词典sentence_corpus = [sentence_dict.doc2bow(i) for i in sentence_list]lda_model = models.LdaModel(sentence_corpus, num_topics=num_topics, id2word=sentence_dict) # LDA模型训练return lda_modelnum_topics = 3 #指定训练主题数
lda_model = LDA_model(new_sentence_list, num_topics = num_topics)
for i in range(num_topics):print(lda_model.print_topic(i)) # 输出每个主题
五、实战演练-苏宁空调评论
获取数据
- 爬虫开源代码
- 八爪鱼等免费软件
- 本分析实战提供数据下载链接🔗
数据探索性分析(EDA)
通过以下代码,可以得到数据分析报告:example.html
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno# 用于可视化缺失值分布
import scipy.stats as st
%matplotlib inline
data = pd.read_csv('苏宁易购-商品评论.csv')import pandas_profiling
pfr = pandas_profiling.ProfileReport(data)
pfr.to_file("./example.html")
分析完毕后,发现只有评价星级和评价内容比较有意思,接下来对这两个特征进行归类、分析
将5星归为正类,1、2、3星归为负类,其余丢弃,对两类样本的中文评价内容继续进行下面的分析。
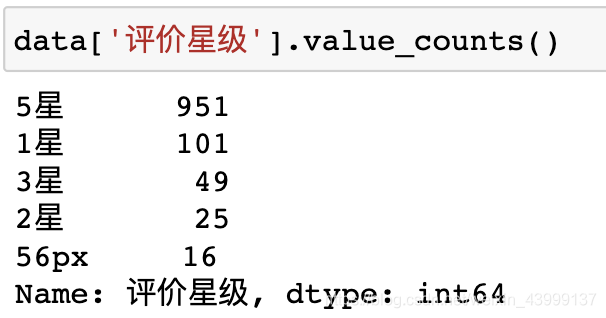
data_good = data[data['评价星级']=='5星']data_bad = data[data['评价星级']!='5星']
data_bad = data_bad[data_bad['评价星级']!='56px']
- data_good部分数据如下

- data_bad部分数据如下

绘制词云图
def compute_word_fre(sentence_list)函数上面已经介绍过了
这里只需更改输入word_fre = compute_word_fre(data_good)即可
def compute_word_fre(sentence_list):sentence_list =[jieba.cut(processing_chinese(sentence),cut_all =True) for sentence in sentence_list] #分词sentence_list = remove_word(sentence_list) #去除停用词new_sentence_list = [[w for w in sentence if w!='']for sentence in sentence_list] #去除jieba分词空字符和停用词更新all_list=[]for i in new_sentence_list: all_list+=i #拼接处理后的句子word_fre ={} for word in all_list : #统计所有句子的全部词语的频率word_fre[word]=word_fre.get(word,0)+1return word_freword_fre = compute_word_fre(data_good) #注意:只调整输入即可import matplotlib.pyplot as plt
from imageio import imread,imsave
from wordcloud import WordCloud, ImageColorGenerator, STOPWORDSwordcloud = WordCloud(background_color='white',collocations=False,mask=imread('cloud.png',pilmode="RGB"),max_words=30,random_state=2021,width=1200, height=800,font_path=r"/System/Library/Fonts/STHeiti Medium.ttc").fit_words(word_fre)# 绘制词云图
plt.imshow(wordcloud, interpolation='bilinear')
wordcloud.to_file("wordcloud.png")
#plt.savefig("other_wordcloud.png",dpi=600) #另一种保存形式
- 正类词云图

- 负类词云图

输出正负类主题分析
因为我们的数据是已经明确标签了,用到这类无监督算法,其实可以分别对正类数据和负类数据进行聚类,但聚为一类,获取它们这一类的主题是什么。
import gc
import tqdm
import numpy as np
from gensim import corpora, models, similarities
import time#LDA前数据预处理
def LDA_processing(sentence_list):sentence_list =[jieba.cut(processing_chinese(sentence),cut_all =True) for sentence in sentence_list] #分词sentence_list = remove_word(sentence_list) #去除停用词new_sentence_list = [[w for w in sentence if w!='']for sentence in sentence_list] #去除jieba分词空字符和停用词更新return new_sentence_list#输入处理好的句子,与分类主题数目,进行聚类训练
def LDA_model(sentence_list,num_topics=3):sentence_list = LDA_processing(sentence_list)sentence_dict = corpora.Dictionary(sentence_list) # 建立词典sentence_corpus = [sentence_dict.doc2bow(i) for i in sentence_list]lda_model = models.LdaModel(sentence_corpus, num_topics=num_topics, id2word=sentence_dict) # LDA模型训练return lda_modelnum_topics = 1 #指定训练主题数
lda_model = LDA_model(data_good, num_topics = num_topics)
for i in range(num_topics):print(lda_model.print_topic(i)) # 输出每个主题lda_model = LDA_model(data_bad, num_topics = num_topics)
for i in range(num_topics):print(lda_model.print_topic(i)) # 输出每个主题
- 正类主题
0.022*“不错” + 0.020*“服务” + 0.016*“非常” + 0.014*“效果” + 0.013*“品牌” + 0.012*“快” + 0.012*“满意” + 0.011*“送货” + 0.009*“制冷” + 0.008*“质量”
- 负类主题
0.020*“安装” + 0.015*“苏宁” + 0.014*“空调” + 0.013*“说” + 0.011*“买” + 0.008*“客服” + 0.008*“格力” + 0.007*“没有” + 0.006*“一个” + 0.005*“电话”
细节
由于我们的负类数据不多,提取的负类主题词可能不是特别准确,我们可以通过对停用词进行人为干预,从而得到更理想的效果。
def remove_word(sentence_list): #去除停用词stop = pd.read_csv('cn_stopwords.txt',encoding='utf-8',header=None,sep='tipdm',engine='python')stop_words = list(stop[0])stop_words +=['安装','苏宁','买','一次','一个','客服','空调','格力','电话','11','问','点','师傅'] #根据自定义添加停用词remove_sentence_list = [[w for w in sentence if w not in stop_words]for sentence in sentence_list] return remove_sentence_list
- 负类主题
0.014*“说” + 0.008*“没有” + 0.005*“差” + 0.005*“服务” + 0.005*“知道” + 0.005*“制冷” + 0.005*“不知” + 0.005*“送” + 0.004*“第一” + 0.004*“降价”
六、代码开源
CSDN开源
Csdn下载链接🔗
Github开源
Github下载链接🔗
注:本开源数据、代码仅供学习使用,不得用于商业用途。
这篇关于NLP中文数据分析干货!!!——针对Chinese分析模版、苏宁空调评论分析实战(提供数据)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







