本文主要是介绍无偏方差和有偏方差,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
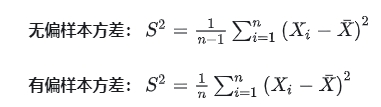
无偏方差和有偏方差的区别就是无偏方差下面的是n-1,而有偏方差就是我们常用的计算方差的公式,最后除以的是n
为什么无偏方差要除以n-1呢?这里理论上可以用自由度解释,即在计算方差时实际上是已知这个序列的均值的,这样这个序列的自由度就是n-1(感觉不太理解,自由度和求方差又有什么关系呢?)
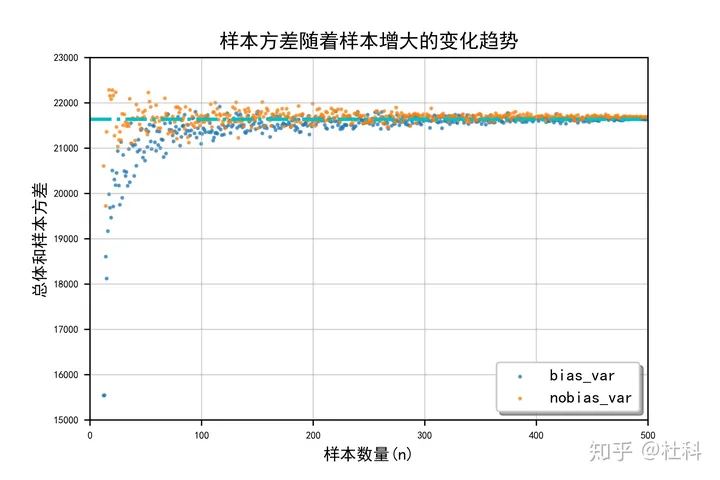
所以用下图来理解吧,无偏方差在样本量比较小的时候计算方差就接近理论值,但有偏方差不是,有偏方差是从0逐渐升到理论值的。
总结的结论就是:在样本量较小的时候,无偏方差更符合实际的总体方差,当样本量较大时,无偏方差和有偏方差区别不大。总的说来用无偏样本方差来估计总体方差会更加准确。
这篇关于无偏方差和有偏方差的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






