无偏专题

【0007day】总体标准差、样本标准差和无偏估计
文章目录 总体标准差和样本标准差无偏估计无偏性与无偏估计量 总体标准差和样本标准差 一些表示上的差别。 总体标准差 样本标准差 两者的区别 样本方差为什么除以n-1? 这主要是由于样本的方差会低估总体的方差(抽样的过程中,按照概率来说,会多选中间的数值从而低估方差),为了使样本标准方差与总体标准方差相接近,这就需要乘以一个大于1的数。)至于为什么是n-1?
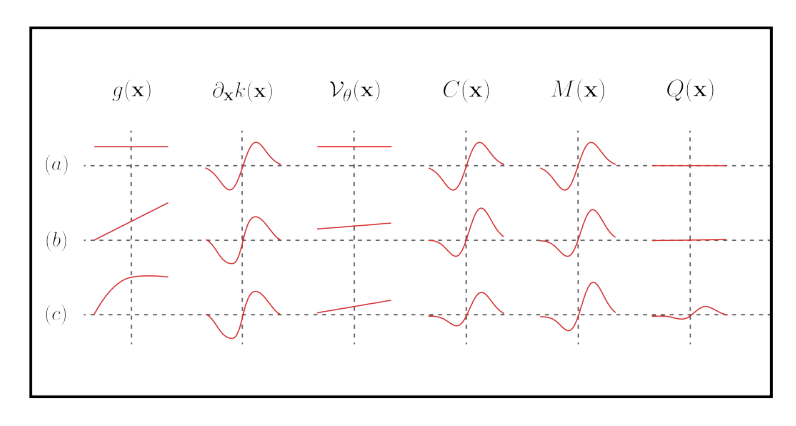
无偏扭曲区域采样在可微分渲染中的应用
图1. 可微渲染计算光传输方程的导数。为了处理可见性的存在,最近的基于物理的可微渲染器需要显式地找到边界点[Li等人2018; Zhang等人2020],或者通过启发式方法近似边界贡献[Loubet等人2019]。我们从第一原理出发,开发了一个无偏估计器,通过内部(区域)样本计算边界贡献。我们的方法可以轻松地与现有的重要性采样方法集成,并计算准确且低方差的梯度。例如,边缘采样方法[Li等人201

无偏估计中贝塞尔系数的由来
对于采样自 X X X的独立同分布样本 x i : i ∈ [ 1 , n ] x_i: i\in[1,n] xi:i∈[1,n],用样本方差 s 2 s^2 s2去估计 X X X的方差 σ 2 \sigma^2 σ2,为什么要除以 n − 1 n-1 n−1而不是 n n n? 证明用 n n n除得到的估计 σ ^ 2 = σ 2 − E [ ( X ˉ − μ ) 2 ] \hat\s

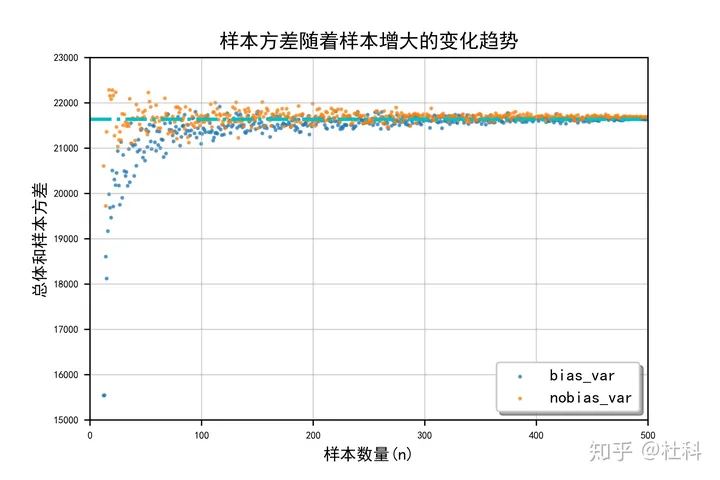
无偏样本方差和有偏样本方差 这里的n或n-1称之为自由度
两者的区别就是一个除以的是n-1,而另一个除以的是n。这里的n或n-1称之为自由度。自由度通俗的理解就是比如一个数值列表list=[x1,x2,x3],如果我们此时知道list的平均值为2,那么对于x1,x2变量我们可以任取,若x1=1,x2=2,那么要使list均值为2那么x3只能取3,此时x3就不再是自变量。那么在平均值已知的条件下,能自由取值的变量就只有2个而不是3个。所以此时list的自由

n折交叉验证结果中的+-怎么算的? 标准差?有偏估计?无偏估计?
n折交叉验证的结果怎么写 Q:这种实验结果里的±是怎么写出来的呢? A:均值± 标准差 标准差 百度标准差的时候,发现了这两个公式。差别是,后者是无偏估计量。 无偏估计 那么什么是无偏估计呢?下面三个链接很好的解释了: 为什么分母从n变成n-1之后,就从【有偏估计】变成了【无偏估计】? 为什么样本方差(sample variance)的分母是 n-1? 为什么样本方差(sample
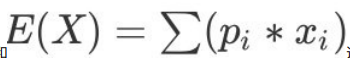
机器学习---无偏估计
1. 如何理解无偏估计 无偏估计:就是我认为所有样本出现的概率⼀样。 假如有N种样本我们认为所有样本出现概率都是 1/N。然后根据这个来计算数学期望。此时的数学期望就是我们平常讲 的平均值。数学期望本质就 是平均值。 2. 无偏估计为何叫做“无偏”?它要“估计”什么? 首先回答第⼀个问题:它要“估计”什么? 它要估计的是整体的数学期望(平均值)。 第⼆个问题:那为何叫做无偏?有偏是什
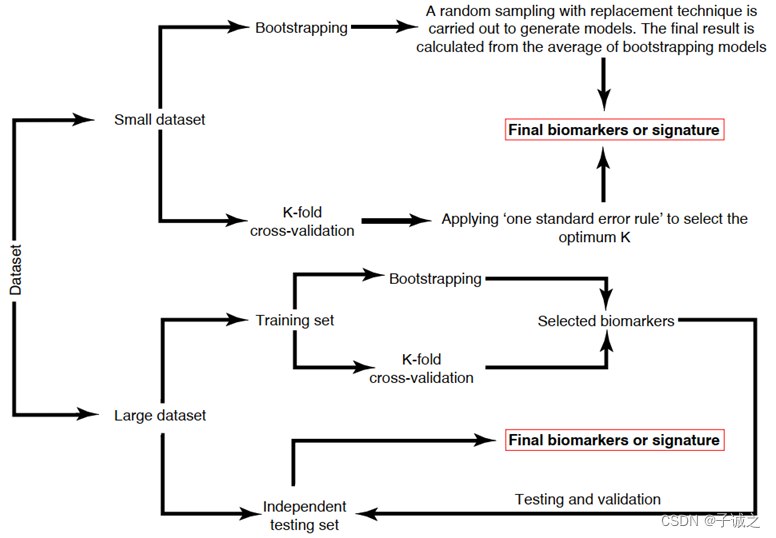
生物标志物发现中的无偏数据分析策略
目录 0. 导论基本概念 1. 生物标志物发现的注意事项2. 数据预处理2.1 高质量原始数据和缺失值处理2.2 数据过滤2.3 数据归一化 3. 数据质量评估3.1 混杂因素3.2 类别分离3.3 功效分析3.4 批次效应 4. 生物标志物发现4.1 策略4.2 数据分析工具4.3 模型优化策略 0. 导论 组学技术有望改善精准医学中生物标志物的发现。已发现的生物标志物的首要