本文主要是介绍增量预训练,在所属领域数据上继续预训练,主要问题是灾难性遗忘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
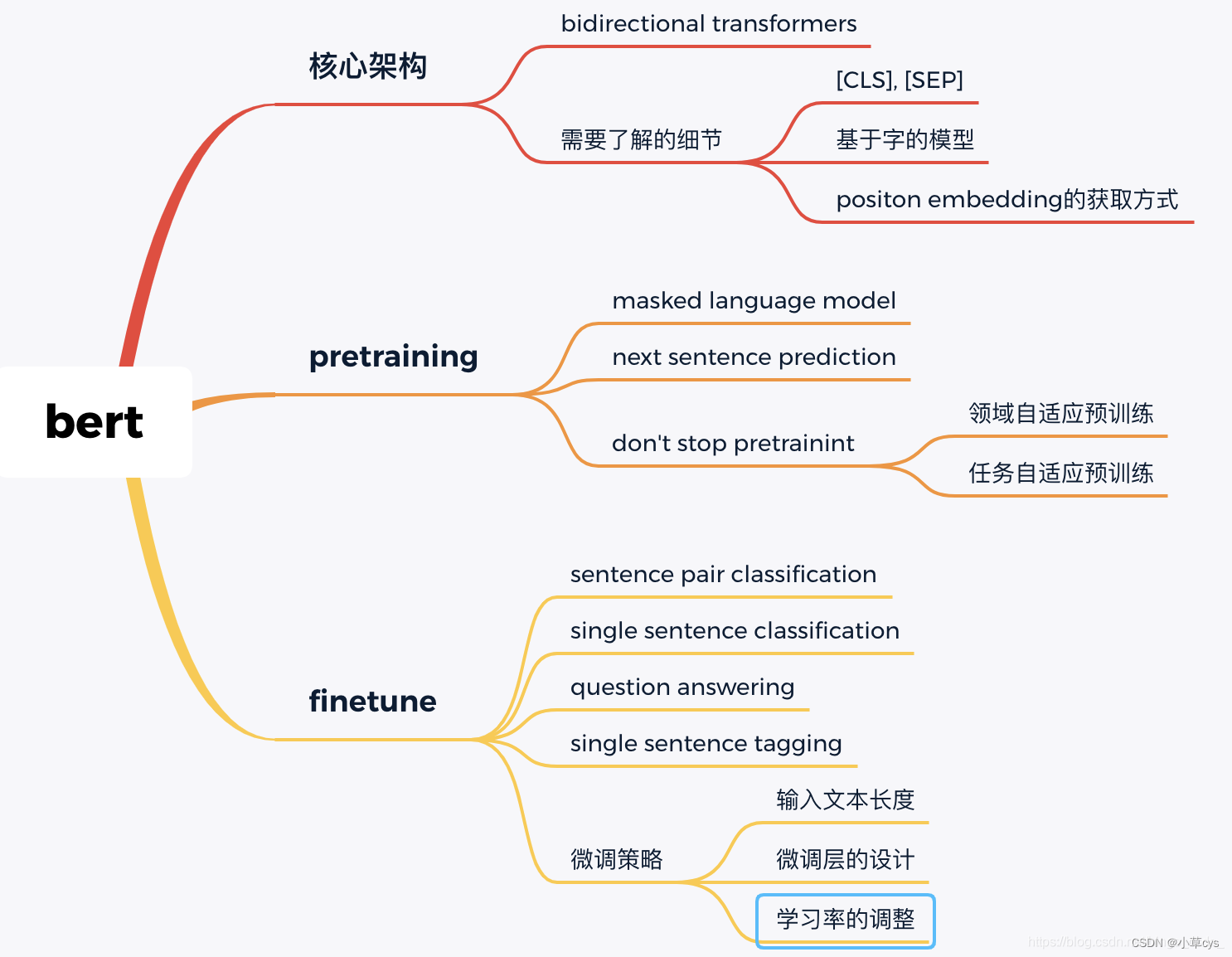
增量预训练也叫领域自适应预训练(domain-adapter pretraining),即在所属领域数据上继续预训练。
主要问题是在增量预训练后可能发生灾难性遗忘。
避免灾难性遗忘主要从以下几个方面入手:
1 领域相关性
增量数据与所选基座模型的原始训练数据尽量一定的相关性。
2 新数据分布与原始数据尽量相似
领域数据和通用数据的比率,结合具体数据:10%,15%,20%的都有。
方案之一是:让无监督数据和指令数据混合,合并增量预训练和微调两个阶段。
3 降低学习率
增量预训练2e-5;指令微调需要更低1e-6;但是得多跑几轮不然学不到领域知识
4 进行warm up,
在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据点看过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就可以看做是warmup。那么为什么之后还要decay呢?当模型训到一定阶段后(比如十个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近loss的local optimal了,为了靠近这个point,我们就要慢慢来。
5 对新任务中参数的变化施加惩罚
6 知识蒸馏(KD),使微调模型的预测结果接近旧模型的预测结果。
这篇关于增量预训练,在所属领域数据上继续预训练,主要问题是灾难性遗忘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






