本文主要是介绍行人重识别:reid-strong-baseline-master(罗浩)---triplet_sampler.py(数据加载,迭代器构建),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先,reid-strong-baseline代码是罗浩博士在CVPR2019发表的《Bag of Tricks and A Strong Baseline for Deep Person Re-identification》,相关代码链接如下:https://github.com/michuanhaohao/reid-strong-baseline。这篇论文对我启发蛮大,也是我入门的基础。我也是小白,代码功底也不是很好,入门比较慢,目前正在研读他的代码。我的代码是在market1501数据集上跑的。
以下所阐述的内容是从以下博客学习来的基于度量学习的ReID代码实现(1)和行人重识别02-06:fast-reid(BoT)-pytorch编程规范(fast-reid为例)3-迭代器构建,数据加载-1。它们对我启发很大。
一、triplet_sampler.py具体位置
在reid-strong-baseline-master/tools/train.py文件中找到train函数的make_data_loader函数。

make_data_loader函数在reid-strong-baseline-master/data/build.py文件中,然后在该函数找到RandomIdentitySampler类。
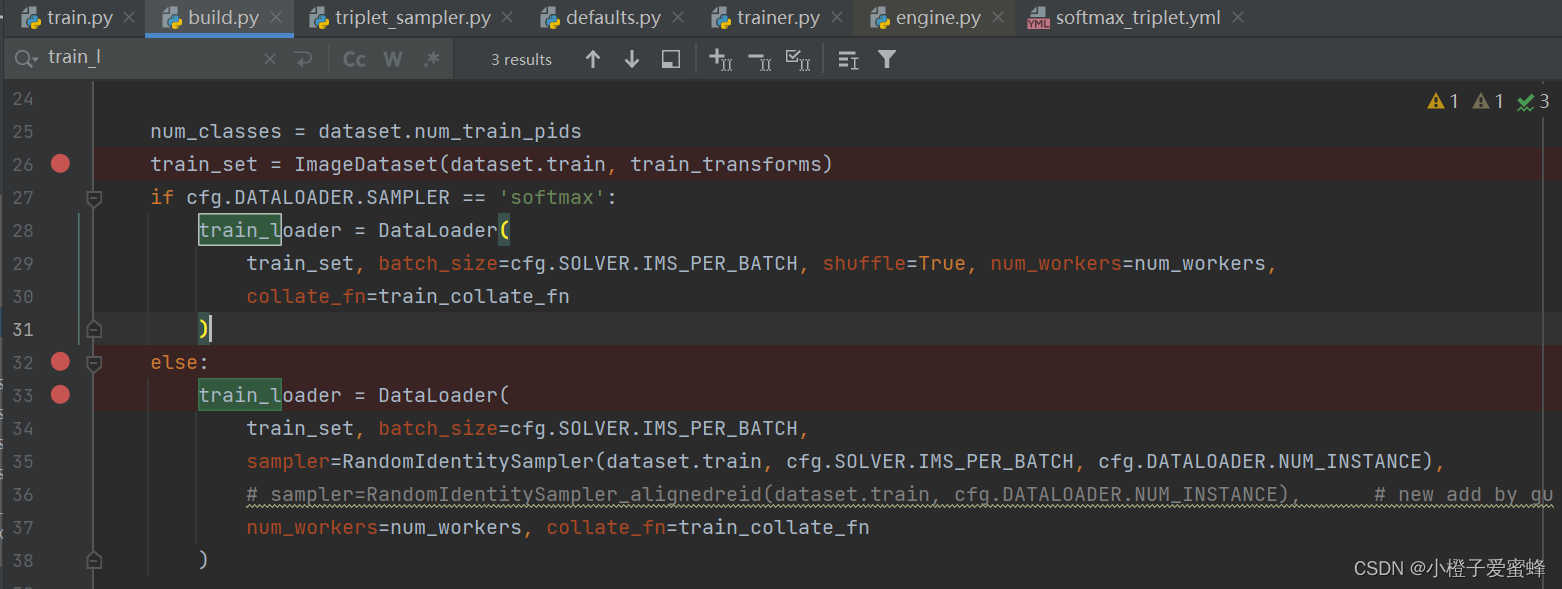
RandomIdentifySampler类是在reid-strong-baseline-master/data/samplers/triplet_sampler.py文件中。
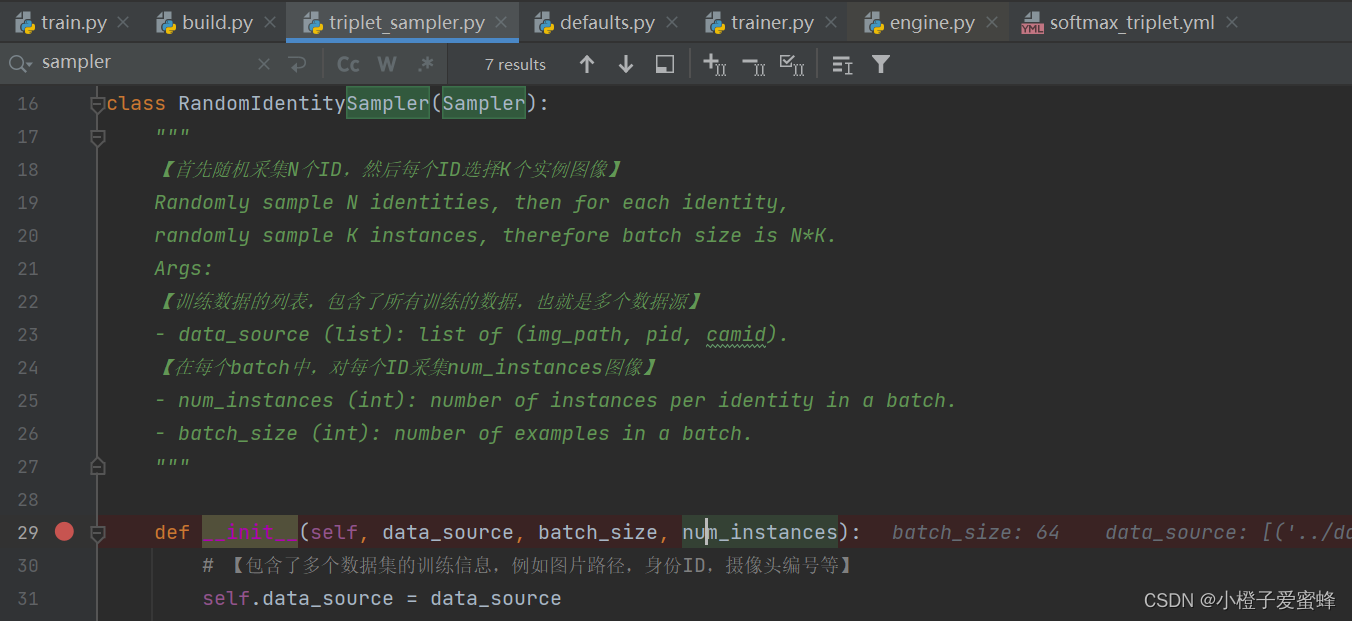
二、triplet_sampler.py解析
注释如下:
"""
@author: liaoxingyu
@contact: liaoxingyu2@jd.com
"""import copy
import random
import torch
from collections import defaultdictimport numpy as np
from torch.utils.data.sampler import Samplerclass RandomIdentitySampler(Sampler):"""【首先随机采集N个ID,然后每个ID选择K个实例图像】Randomly sample N identities, then for each identity,randomly sample K instances, therefore batch size is N*K.Args:【训练数据的列表,包含了所有训练的数据,也就是多个数据源】- data_source (list): list of (img_path, pid, camid).【在每个batch中,对每个ID采集num_instances图像】- num_instances (int): number of instances per identity in a batch.- batch_size (int): number of examples in a batch."""def __init__(self, data_source, batch_size, num_instances):# 【包含了多个数据集的训练信息,例如图片路径,身份ID,摄像头编号等】self.data_source = data_sourceself.batch_size = batch_size# 【对每个身份采集的图像数目,本文设置(num_instances=4)】self.num_instances = num_instances# 【通过计算获得每个batch需要采集多少个身份ID,16=64/4】self.num_pids_per_batch = self.batch_size // self.num_instances# 【(写了一个dic,dic的key是id,value是各id对应的图片序号)用于存储该图片 序列号 保存于字典,方便查找转换】self.index_dic = defaultdict(list)# 【循环把(key:id==>行人的id,即pid)(value:各个id对应的图片序号)数据保存上述字典中】for index, (_, pid, _) in enumerate(self.data_source):self.index_dic[pid].append(index)# 【把index_dic的键值(身份ID)保存于self.pids中】self.pids = list(self.index_dic.keys())# estimate number of examples in an epochself.length = 0for pid in self.pids:idxs = self.index_dic[pid]num = len(idxs)if num < self.num_instances:num = self.num_instancesself.length += num - num % self.num_instances# 【iter返回的是一个epoch的数据,是一个list】def __iter__(self):batch_idxs_dict = defaultdict(list)for pid in self.pids:idxs = copy.deepcopy(self.index_dic[pid])if len(idxs) < self.num_instances:idxs = np.random.choice(idxs, size=self.num_instances, replace=True)random.shuffle(idxs)batch_idxs = []for idx in idxs:batch_idxs.append(idx)if len(batch_idxs) == self.num_instances:batch_idxs_dict[pid].append(batch_idxs)batch_idxs = []avai_pids = copy.deepcopy(self.pids)final_idxs = []while len(avai_pids) >= self.num_pids_per_batch:selected_pids = random.sample(avai_pids, self.num_pids_per_batch)for pid in selected_pids:batch_idxs = batch_idxs_dict[pid].pop(0)final_idxs.extend(batch_idxs)if len(batch_idxs_dict[pid]) == 0:avai_pids.remove(pid)self.length = len(final_idxs)return iter(final_idxs)def __len__(self):return self.length
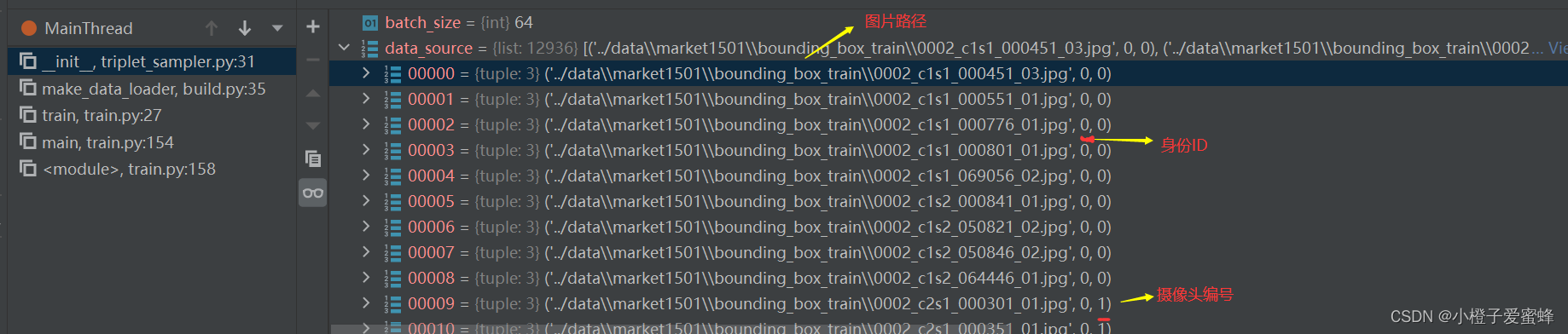
1.def __init__()函数中的data_source包含很多信息,调试结果如图:
2.def __init__()函数中的num_pids_per_batch参数,很重要:

3.def __init__()函数中for index,(_,pid,_) in enumerate(self.data_source)的解释:
首先,通过for循环将行人id存储在字典里,调试后可看到index_dic字典内容:
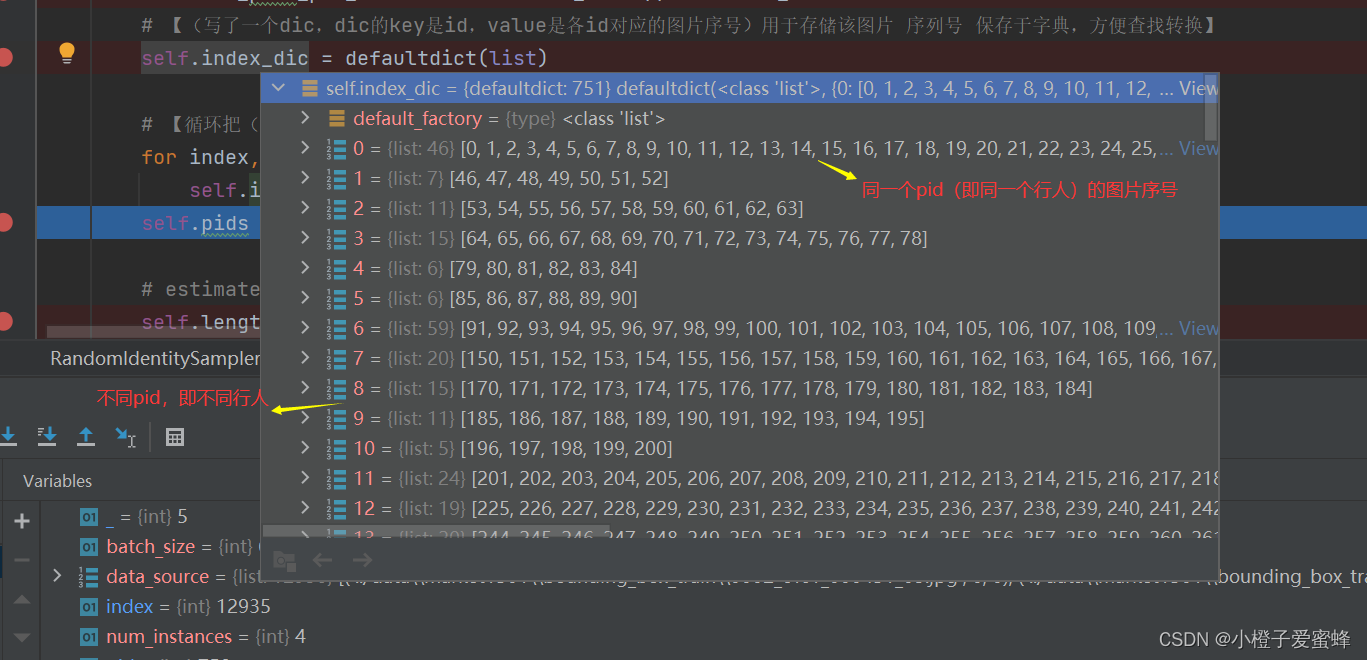
【注:pid从0开始,750结束,pid一共751个,即751个人】


更加直观从数据集看:
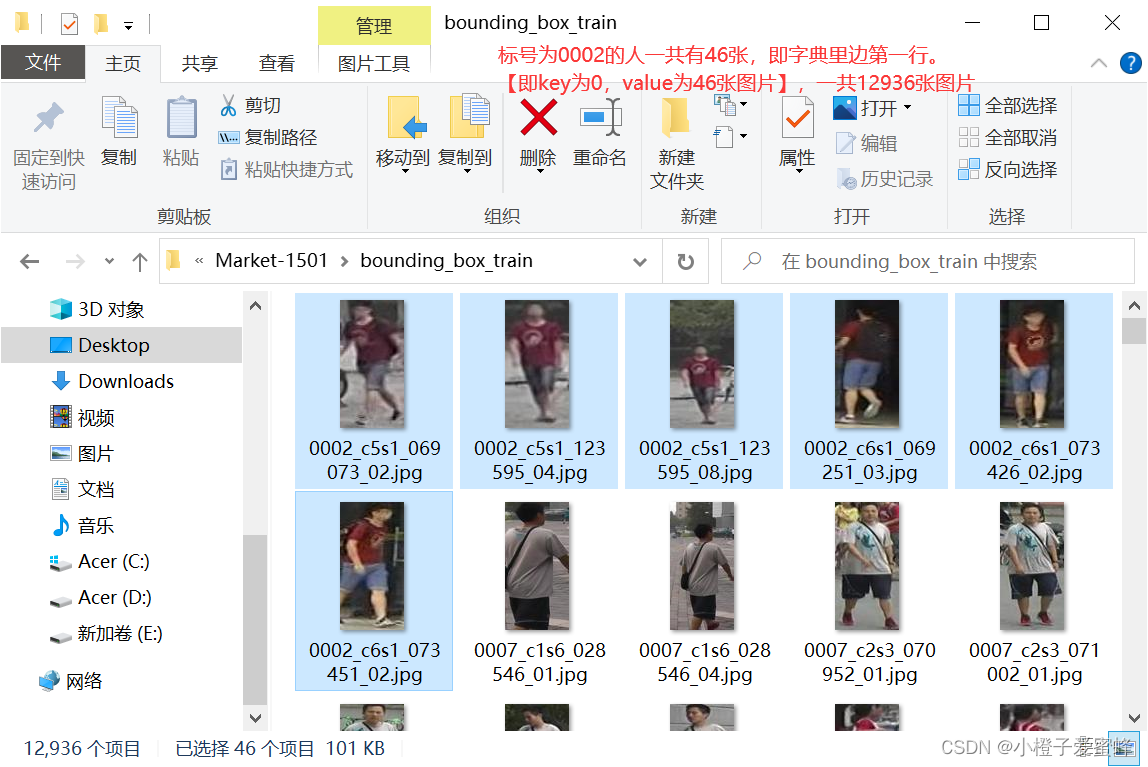
4.def __init__()函数中self.pids = list(self.index_dic.keys())调试如下:
 5.def __init__()函数中RandomIdentitySampler最终取到的值:
5.def __init__()函数中RandomIdentitySampler最终取到的值:

目录
一、triplet_sampler.py具体位置
二、triplet_sampler.py解析
这篇关于行人重识别:reid-strong-baseline-master(罗浩)---triplet_sampler.py(数据加载,迭代器构建)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



