本文主要是介绍低质量图像超分算法 SwinIR: Image Restoration Using Swin Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文名称:SwinIR: Image Restoration Using Swin Transformer
论文地址:https://arxiv.org/abs/2108.10257
代码仓库:https://github.com/JingyunLiang/SwinIR
Swin Transformer
Transformer在机器翻译等一维序列处理上取得了巨大成功,但基本的Transformer难以直接应用到视觉任务,Vision Transformer(VIT)的出现成功的将Transformer拉入了CV界,可以说是Transformer处理视觉任务的开山之作,VIT成功的将视觉问题转换成了NLP问题,将2D的图像通过打成多个patch块来转换Transformer能处理的1Dpatch序列,Swin Transformer也是借鉴了Vision Transformer对于图片的处理方法。
Swin Transformer名字的前部分Swin来自于Shifted Windows,Shifted Windows(移动窗口)也是Swin Transformer的主要特点。Swin Transformer的作者的初衷是想让Vision Transformer像卷积神经网络一样,也能够分成几个block做层级式的特征提取,从而导致提出来的特征具有多尺度的概念。
标准的Transformer直接用到视觉领域有一些挑战,难度主要来自于尺度不一和图像的resolution较大两个方面。首先是关于尺度的问题,例如一张街景的图片,里面有很多车和行人,并且各种物体的大小不一,这种现象不存在于自然语言处理。再者是关于图像的resolution较大问题,如果以像素点为基本单位,序列的长度就变得高不可攀,为了解决序列长度这一问题,科研人员做了一系列的尝试工作,包括把后续的特征图作为Transformer的输入或者把图像打成多个patch以减少图片的resolution,也包括把图片划成一个一个的小窗口,然后再窗口里做自注意力计算等多种办法。针对以上两个方面的问题,Swin Transformer网络被提出,它的特征是通过移动窗口的方式学来的,移动窗口不仅带来了更大的效率,由于自注意力是在窗口内计算的,所以也大大降低了序列的长度,同时通过Shiting(移动)的操作可以使相邻的两个窗口之间进行交互,也因此上下层之间有了cross-window connection,从而变相达到了全局建模的能力。层级式结构的好处在于不仅灵活的提供各种尺度的信息,同时还因为自注意力是在窗口内计算的,所以它的计算复杂度随着图片大小线性增长而不是平方级增长,这就使Swin Transformer能够在特别大的分辨率上进行预训练模型。
摘要
图像恢复是一个长期存在的低级视觉问题,旨在从低质量图像(例如,缩小的、有噪声的和压缩的图像)中恢复高质量图像。虽然最先进的图像恢复方法是基于卷积神经网络的,但很少有人尝试使用在高级视觉任务中表现出令人印象深刻的性能的变压器。本文提出了一种基于Swin变换的强基线图像恢复模型SwinIR。SwinIR由浅层特征提取、深层特征提取和高质量图像重建三部分组成。实验表明在图像超分辨率(包括经典、轻量级和真实世界图像超分辨率)、图像去噪(包括灰度和彩色图像去噪)和JPEG压缩伪影减少。实验结果表明,SwinIR在不同任务上的性能比现有方法提高了0.14~0.45dB,同时参数总数减少了67%。

上图可以看出SwinIR的提升非常恐怖,经典的RCAN在质量和参数量上都要远逊色于SwinIR。
引言及相关工作
以往基于CNN的方法通常会遇到两个基本问题:
- 图像和卷积核之间的交互与内容无关,使用相同的卷积核来恢复不同的图像区域可能不是一个好的选择。
- CCN只能对局部信息进行处理,卷积对于长期依赖性建模是无效的。
而Transformer基于自注意力机制可以捕获上下文之间的全局信息交互,但同时基于视觉的VIT会将输入图像分割成大小固定的小块(patch),并独立处理每个小块,因此会导致另外两个缺点:
- 恢复的图像可能会在每个小斑块周围引入边界伪影。
- 每个patch的边界像素会丢失信息。
Swin Transformer则很好的结合了CNN和Transformer的优点,同时避免了这些缺点
Swin Transformer采用局部注意机制处理图像,其具有CNN处理大尺寸图像的优势,并且相较于Transformer/CNN,它的计算量减少了很多,因此可以处理大尺寸图像。此外采用了滑动窗口方案来建模长期依赖关系
网络结构
SwinIR由三个模块组成:浅层特征提取、深层特征提取和高质量(HQ)图像重建模块。

浅层特征提取(Shallow Feature Extraction)
与所有的SR方法一样,浅层特征采用3×3大小的卷积核进行浅层特征提取,给出的解释是卷积层擅长早期视觉处理,从而导致更稳定的优化和更好的结果,这一点在许多研究中也有所体现。

深层特征提取(DeepFeature Extraction)
上面的图2可以看出,整个深层特征提取依赖于作者提出的Residual Swin Transformer blocks (RSTB)结构,每一个RSTB由6个Swin Transformer Layer(STL)组成,并在最后加上一个3×3的Conv。
![]()
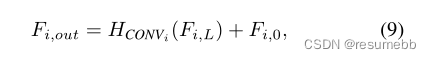
至于为什么要加上卷积层,作者给出的解释有两个原因:
- 虽然Transformer可以被视为空间变化卷积的具体实例,但具有空间不变滤波器的卷积层可以增强SwinIR的平移等方差。
- 残差连接提供了从不同块到重建模块的基于标识的连接,允许不同级别的特征的聚集。
RSTB代码:
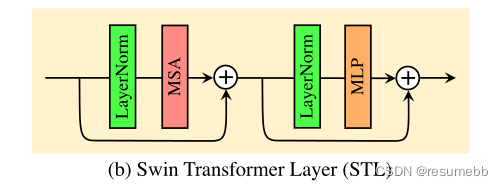
class RSTB(nn.Module):"""Residual Swin Transformer Block (RSTB).Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resolution.depth (int): Number of blocks.num_heads (int): Number of attention heads.window_size (int): Local window size.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.img_size: Input image size.patch_size: Patch size.resi_connection: The convolutional block before residual connection."""def __init__(self, dim, input_resolution, depth, num_heads, window_size,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,img_size=224, patch_size=4, resi_connection='1conv'):super(RSTB, self).__init__()self.dim = dimself.input_resolution = input_resolutionself.residual_group = BasicLayer(dim=dim,input_resolution=input_resolution,depth=depth,num_heads=num_heads,window_size=window_size,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop, attn_drop=attn_drop,drop_path=drop_path,norm_layer=norm_layer,downsample=downsample,use_checkpoint=use_checkpoint)if resi_connection == '1conv':self.conv = nn.Conv2d(dim, dim, 3, 1, 1)elif resi_connection == '3conv':# to save parameters and memoryself.conv = nn.Sequential(nn.Conv2d(dim, dim // 4, 3, 1, 1), nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Conv2d(dim // 4, dim // 4, 1, 1, 0),nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Conv2d(dim // 4, dim, 3, 1, 1))self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim,norm_layer=None)self.patch_unembed = PatchUnEmbed(img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim,norm_layer=None)def forward(self, x, x_size):return self.patch_embed(self.conv(self.patch_unembed(self.residual_group(x, x_size), x_size))) + xdef flops(self):flops = 0flops += self.residual_group.flops()H, W = self.input_resolutionflops += H * W * self.dim * self.dim * 9flops += self.patch_embed.flops()flops += self.patch_unembed.flops()return flopsSwin Transformer Layer(STL)
这个算是文章真正的精华所在了,STL也是基于标准Transformer layer 的多头自注意力机制。主要改进点在于局部注意力和移动窗口机制。
如图所示,给定尺寸为H × W × C的输入,Swin Transformer先将输入划分为不重叠的M × M个局部窗口,reshape为HW/M平方×M平方×C,其中HW/M平方是窗口总数。然后,它为每个窗口分别计算自我注意(局部注意力),对于局部窗口特征X ∈ M平方×C,查询、键和值矩阵Q、K和V计算如下:
![]()
这段话不太好叙述,原文是这么说的:

其中PQ、PK和PV是跨不同窗口共享的投影矩阵,有了QKV后,就可以计算局部窗口中的注意力得分了,这里就跟Transformer一样了:
![]()
B就是Transformer中的position位置编码,不过Transformer是给定的,这里是可学习的相对位置编码。在使用时并行执行h次注意功能,并连接多头自注意multi-head self-attention(MSA)的结果。
和Transformer一样,在MSA和MLP之前加了LayerNorm层进行标准化。
计算过程如代码所示:
class WindowAttention(nn.Module):r""" Window based multi-head self attention (W-MSA) module with relative position bias.It supports both of shifted and non-shifted window.Args:dim (int): Number of input channels.window_size (tuple[int]): The height and width of the window.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if setattn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0proj_drop (float, optional): Dropout ratio of output. Default: 0.0"""def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Wwself.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)trunc_normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask=None):"""Args:x: input features with shape of (num_windows*B, N, C)mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None"""B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return xdef extra_repr(self) -> str:return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'def flops(self, N):# calculate flops for 1 window with token length of Nflops = 0# qkv = self.qkv(x)flops += N * self.dim * 3 * self.dim# attn = (q @ k.transpose(-2, -1))flops += self.num_heads * N * (self.dim // self.num_heads) * N# x = (attn @ v)flops += self.num_heads * N * N * (self.dim // self.num_heads)# x = self.proj(x)flops += N * self.dim * self.dimreturn flops重建部分
重建部分与大部分网络一样,不过SwinIR将浅层和深层特征给加起来了,这个操作也很常见。
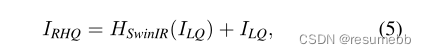
损失函数对于SR任务用的也是通用的L1
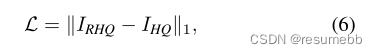
实验部分
超参设置
RSTB个数K = 6 (轻量级SwinIR,取K= 4)
STL数L = 6
窗口大小M = 8 (减少JPEG压缩伪影,窗口大小M = 7)
通道数C = 180 (轻量级SwinIR,取C = 60)
注意头数h = 6
自集成策略用“+”表示
这里比较惊讶的是通道数取到180竟然还能保持较低的参数量和计算量,RCAN取64都已经很大了,足以见得SwinIR的强大。
实验对比
消融实验感兴趣可以自行探究,主要展示一下SwinIR是如何吊打其他网络的

采用DIV2K和F2K混合训练效果好暂且不谈,以目前最流行的DIV2K做训练集,在×2,×3,×4下的结果远远领先其他方法,有点睥睨天下的感觉。

轻量级的SwinIR在仅有897K参数量的情况下,也是吊打其他方法。
可视化对比时还把GAN给拉进来了,众所周知GAN在SR任务中的表现突出一个能打,虽然评价指标PSNR/SSIM比不过CNN,但是视觉效果远好于CNN。

总结
文章提出RSTB进行深度特征提取,每个RSTB由Swin变换层、卷积层和残余连接组成。大量实验表明,SwinIR在经典图像复原、轻量级图像复原、真实图像复原、灰度图像去噪、彩色图像去噪和JPEG压缩伪影减少等6种不同设置下,均取得了令人满意的效果,从而验证了SwinIR的有效性和普适性。在未来,作者还将把该模型扩展到其他恢复任务,如图像去模糊和去雨。
用作者提供的预训练模型测试结果确实很好,后面准备自己训练一下SwinIR,看一看自己训练的效果如何, 同时计算一下Flops进行一下对比。
这篇关于低质量图像超分算法 SwinIR: Image Restoration Using Swin Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








