本文主要是介绍Real-time Scene Text Detection with Differentiable Binarization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们提出了一个名为可微二值化(DB)的module,它可以在分割网络中执行二值化过程。DB module和分割网络一起优化,可以自适应设置二值化的阈值,从检测精度和速度两方面来看,它达到了19年最先进的结果,检测1器实现了 F-measure of 82.8,速度为62FPS, 在MSRA-TD500 数据集上
传统做法:大多数现有的检测方法使用类似的post-processing,如图所示(蓝色箭头):首先,它们设置一个固定的阈值,用于转换分割网络生成的概率图转换成二值图像;然后,使用像素聚类等启发式技术将像素分组到文本实例中
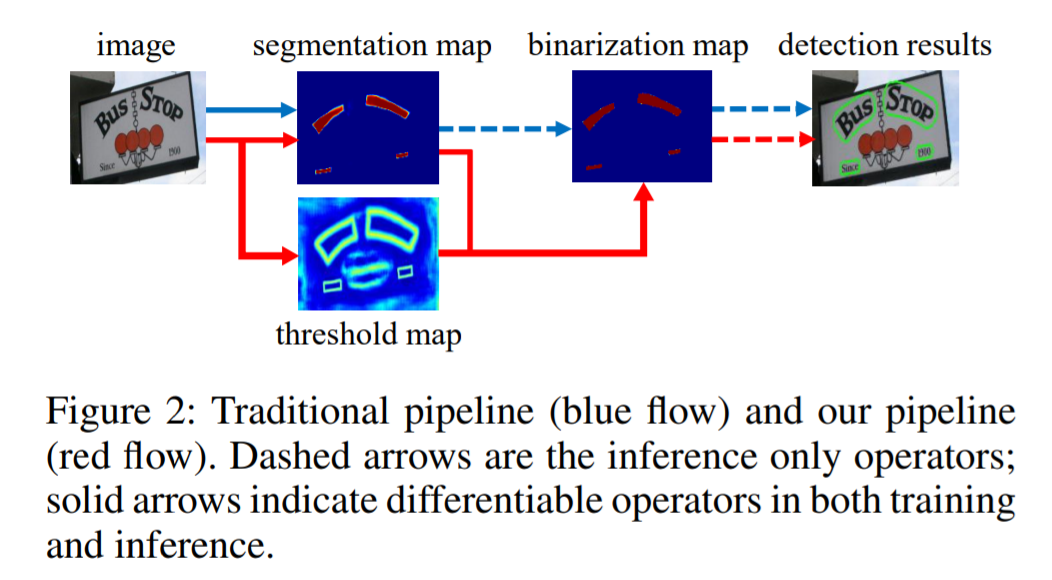
改进做法:将二值化操作插入分割网络,以进行联合优化。通过这种方式,可以自适应地预测图像每个位置的阈值,从而能够完全区分像素前景和背景
然而,标准的二值化函数是不可微的,提出了一个近似的二值化函数,称为可微二值化(DB)
本文的主要贡献是提出了可微的DB模块,对segment结果的二值化过程可以端到端进行训练
- 在5个基准集上实现了比较好的表现
- 比先前的方法更快,DB可以提供一个二值化图,简化了后处理
- 使用轻量级的主干也可以表现好,在ResNet-18主干网络上增强了检测性能
- 在推理阶段,可以移除DB,不影响性能
1. 方法
由FPN产生的结果特征结果F,由thresh网络和probability网络分别产生probability map (P) and the threshold map (T). approximate binary map (Bˆ) 由 P 和 T计算得到
1.1 二值化
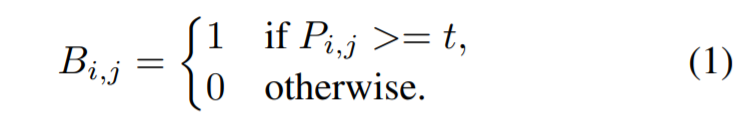
训练过程中不可以随着分割网络的优化而优化
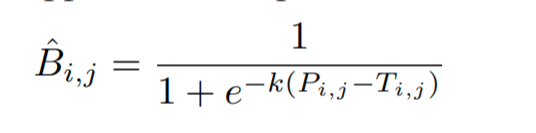
采用一个step-function代替,其中Bˆ 是 approximate binary map,T为threshold map,P为概率图,k=50

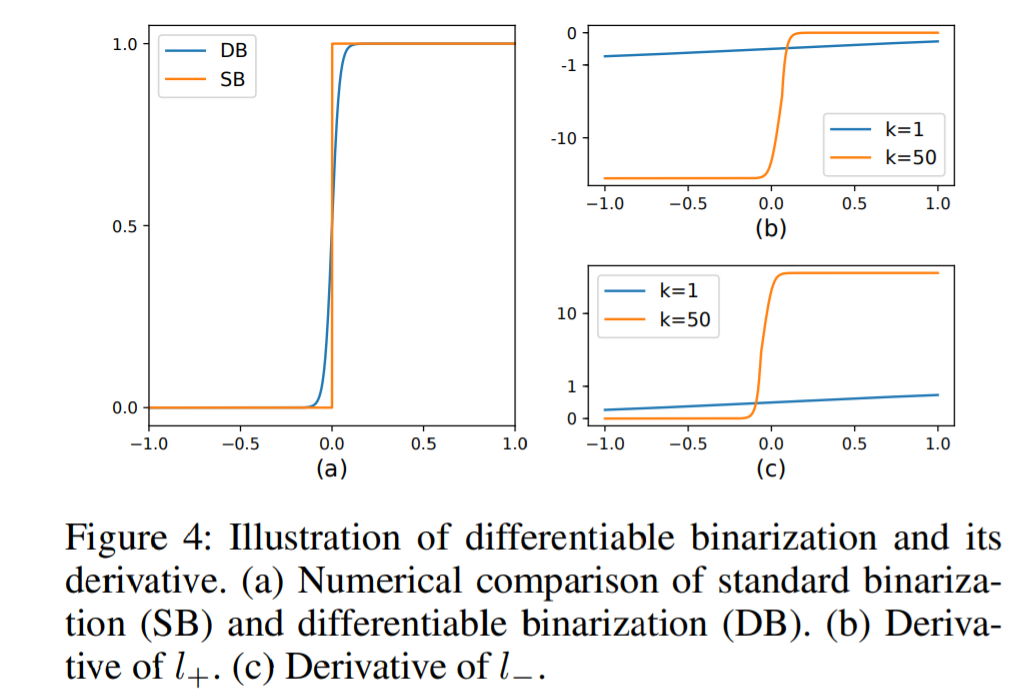
这个可微分的二值函数,不仅可以很好的区分前后背景,而且还能很好的分开相邻文本

在不同x区域,k值放大的重要性
1.2 Adaptive threshold
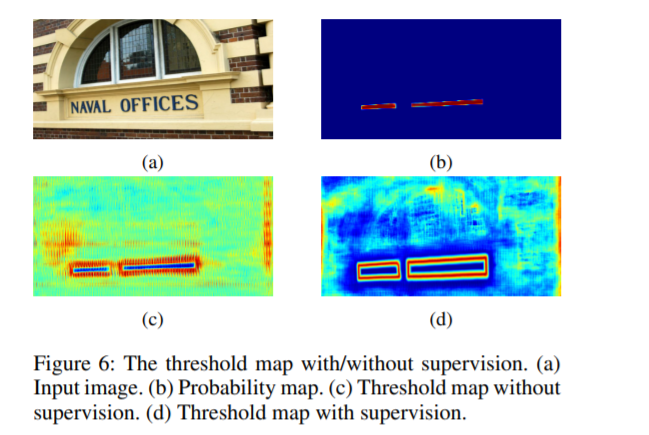
从外观上看,阈值图 (threshold map) 与的文本边框图相似。 但是,阈值图的动机和用法与文本边框图不同。 在下图中显示了带有/不带有监督的阈值图。即使没有监督阈值图,阈值图也会突出显示文本边框区域。 这表明类似边界的阈值图有利于最终结果。 因此,我们在阈值图上应用了类似边界的监督,以提供更好的指导。文中的阈值图用作二值化的阈值。
1.3 Deformable convolution
可变形卷积可以为模型提供灵活的感受野,这对极端长宽比的文本实例特别有利。 在 ResNet-18 或 ResNet-50 主干中的 conv3,conv4和conv5阶段的所有3×3卷积层中应用了可调节的可变形卷积。
1.4 Label generation
生成扩张和收缩的polygon的偏移量计算,想法来自于PSENET
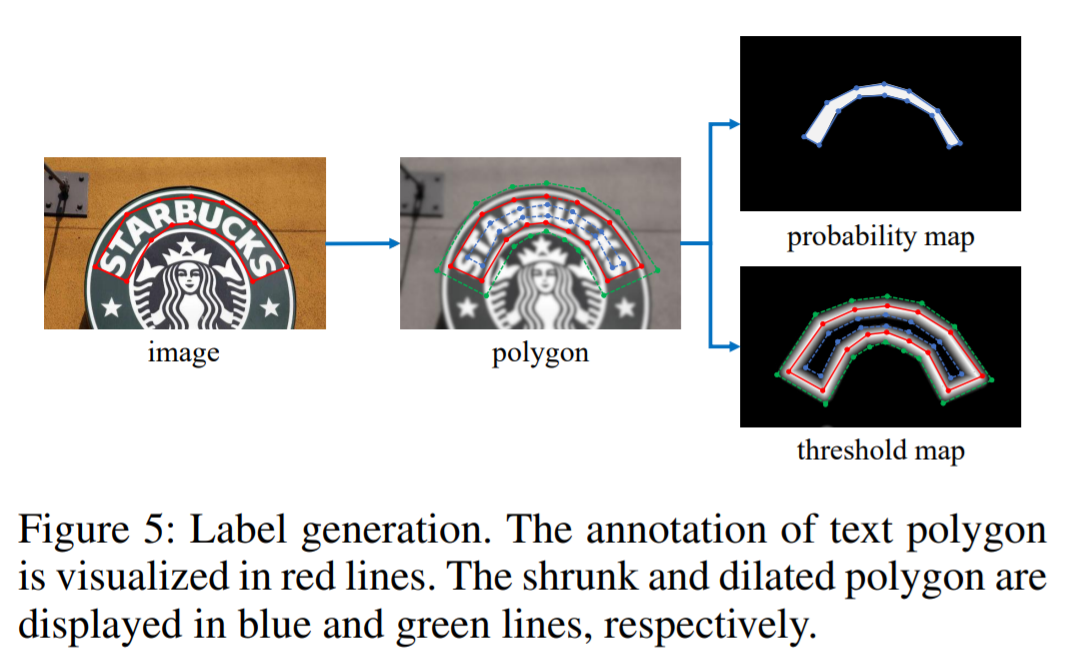
shrunk和dilated公式,r设置为0.4
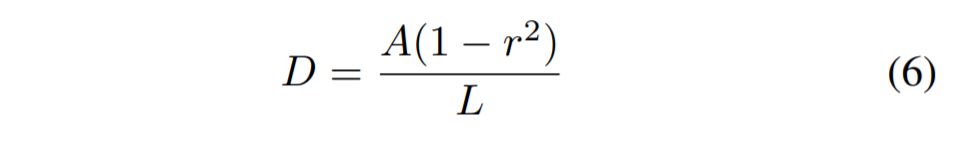
probability map:缩小 Gs
threshold map: 扩张 Gd
将Gs和Gd之间的间隔作为文本区域,threshold的label可以通过计算与原始多边形最近的部分的距离
1.4 optimizer
其中α=1.0,β=10

对于概率损失和二值损失都采用在线难例挖掘,loss采用BCELoss,正负比例1:3
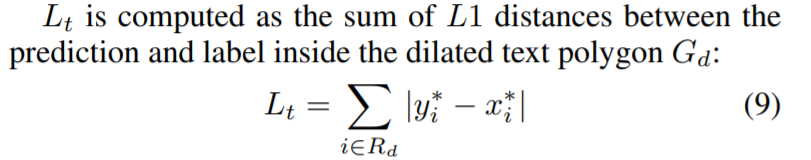
thresh损失采用的是L1 distance,其中Rd是膨胀多边形的所有点的索引,y*是阈值图的label
2. 推理阶段
首先使用固定的阈值(0.2)把概率图或者近似二进制图二值化得到二值图;
从二值图中获得连续的区域(缩小的文本区域);
使用维特比算法计算的偏移,将缩小的区域膨胀
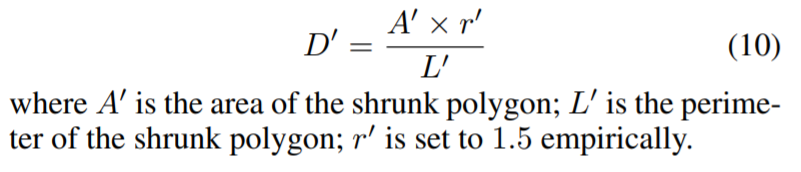
相关文章:
这篇关于Real-time Scene Text Detection with Differentiable Binarization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



