本文主要是介绍es中相关性和相关性算分(explain,boosting),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过explain API查看TF-IDF得分:
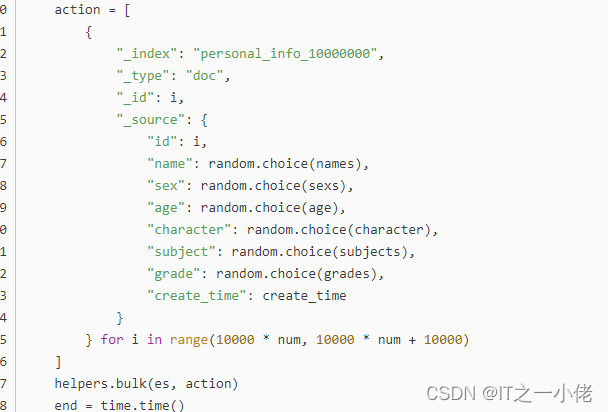
数据集:使用python生成大量数据写入es数据库并查询操作2_IT之一小佬的博客-CSDN博客_python helpers.bulk

在search查询中,explain默认是false。
当explain为false或者不写时,查询条件如下:
GET /personal_info_100000/_search
{"explain": false,"query": {"match": {"character": "学习"}}
}运行结果:
"hits" : {"total" : {"value" : 10000,"relation" : "gte"},"max_score" : 4.277235,"hits" : [{"_index" : "personal_info_100000","_type" : "doc","_id" : "15","_score" : 4.277235,"_source" : {"id" : 15,"name" : "刘一","sex" : "男","age" : 25,"character" : "肯学习,有问题不逃避,愿意虚心向他人学习","subject" : "生物","grade" : 69,"create_time" : "2022-11-01 21:44:12"}},{"_index" : "personal_info_100000","_type" : "doc","_id" : "29","_score" : 4.277235,"_source" : {"id" : 29,"name" : "刘一","sex" : "男","age" : 32,"character" : "肯学习,有问题不逃避,愿意虚心向他人学习","subject" : "英语","grade" : 85,"create_time" : "2022-11-01 21:44:12"}},
......当explain为true时,查询条件为:
GET /personal_info_100000/_search
{"explain": true,"query": {"match": {"character": "学习"}}
}运行结果:
"hits" : {"total" : {"value" : 10000,"relation" : "gte"},"max_score" : 4.277235,"hits" : [{"_shard" : "[personal_info_100000][0]","_node" : "9xCKv5RGRNecuoPworyaUg","_index" : "personal_info_100000","_type" : "doc","_id" : "15","_score" : 4.277235,"_source" : {"id" : 15,"name" : "刘一","sex" : "男","age" : 25,"character" : "肯学习,有问题不逃避,愿意虚心向他人学习","subject" : "生物","grade" : 69,"create_time" : "2022-11-01 21:44:12"},"_explanation" : {"value" : 4.277235,"description" : "sum of:","details" : [{"value" : 1.6575089,"description" : "weight(character:学 in 2) [PerFieldSimilarity], result of:","details" : [{"value" : 1.6575089,"description" : "score(freq=2.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 1.1837717,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 30612,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 100000,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.63645136,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 2.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 18.0,"description" : "dl, length of field","details" : [ ]},{"value" : 19.23022,"description" : "avgdl, average length of field","details" : [ ]}]}]}]},{"value" : 2.6197262,"description" : "weight(character:习 in 2) [PerFieldSimilarity], result of:","details" : [{"value" : 2.6197262,"description" : "score(freq=2.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 1.870975,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 15397,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 100000,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.63645136,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 2.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 18.0,"description" : "dl, length of field","details" : [ ]},{"value" : 19.23022,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}]}},{"_shard" : "[personal_info_100000][0]","_node" : "9xCKv5RGRNecuoPworyaUg","_index" : "personal_info_100000","_type" : "doc","_id" : "29","_score" : 4.277235,"_source" : {"id" : 29,"name" : "刘一","sex" : "男","age" : 32,"character" : "肯学习,有问题不逃避,愿意虚心向他人学习","subject" : "英语","grade" : 85,"create_time" : "2022-11-01 21:44:12"},"_explanation" : {"value" : 4.277235,"description" : "sum of:","details" : [{"value" : 1.6575089,"description" : "weight(character:学 in 15) [PerFieldSimilarity], result of:","details" : [{"value" : 1.6575089,"description" : "score(freq=2.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 1.1837717,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 30612,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 100000,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.63645136,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 2.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 18.0,"description" : "dl, length of field","details" : [ ]},{"value" : 19.23022,"description" : "avgdl, average length of field","details" : [ ]}]}]}]},{"value" : 2.6197262,"description" : "weight(character:习 in 15) [PerFieldSimilarity], result of:","details" : [{"value" : 2.6197262,"description" : "score(freq=2.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 1.870975,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 15397,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 100000,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.63645136,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 2.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 18.0,"description" : "dl, length of field","details" : [ ]},{"value" : 19.23022,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}]}},
......使用Kabana批量插入几条数据:
PUT /test_score/_bulk
{"index": {"_id": 1}}
{"content": "we use Elasticsearch to power the search"}
{"index": {"_id": 2}}
{"content": "we like elasticsearch"}
{"index": {"_id": 3}}
{"content": "Thre scoring of documents is caculated by the scoring formula"}
{"index": {"_id": 4}}
{"content": "you know ,for search"}当explain为false或者不写时,查询条件如下:
GET /test_score/_search
{"explain": false,"query": {"match": {"content": "elasticsearch"}}
}运行结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.8713851,"hits" : [{"_index" : "test_score","_type" : "_doc","_id" : "2","_score" : 0.8713851,"_source" : {"content" : "we like elasticsearch"}},{"_index" : "test_score","_type" : "_doc","_id" : "1","_score" : 0.6489038,"_source" : {"content" : "we use Elasticsearch to power the search"}}]}
}
当explain为true时,查询条件为:
GET /test_score/_search
{"explain": true,"query": {"match": {"content": "elasticsearch"}}
}运行结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.8713851,"hits" : [{"_shard" : "[test_score][0]","_node" : "9xCKv5RGRNecuoPworyaUg","_index" : "test_score","_type" : "_doc","_id" : "2","_score" : 0.8713851,"_source" : {"content" : "we like elasticsearch"},"_explanation" : {"value" : 0.8713851,"description" : "weight(content:elasticsearch in 1) [PerFieldSimilarity], result of:","details" : [{"value" : 0.8713851,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.6931472,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 4,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.5714286,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 3.0,"description" : "dl, length of field","details" : [ ]},{"value" : 6.0,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}},{"_shard" : "[test_score][0]","_node" : "9xCKv5RGRNecuoPworyaUg","_index" : "test_score","_type" : "_doc","_id" : "1","_score" : 0.6489038,"_source" : {"content" : "we use Elasticsearch to power the search"},"_explanation" : {"value" : 0.6489038,"description" : "weight(content:elasticsearch in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.6489038,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.6931472,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 4,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.42553192,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 7.0,"description" : "dl, length of field","details" : [ ]},{"value" : 6.0,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}}]}
}
Boosting Relevance 计算相关性
Boosting是控制相关度的一种手段。参数boost的含义:
- 当boost > 1时,打分的相关度相对性提升
- 当0 < boost <1时,打分的权重相对性降低
- 当boost <0时,贡献负分
返回匹配positive查询的文档并降低匹配negative查询的文档相似度分。这样就可以在不排除某些文档的前提下对文档进行查询,搜索结果中存在只不过相似度分数相比正常匹配的要低.
应用场景:希望包含了某项内容的结果不是不出现,而是排序靠后。
查询条件1,negative_boost为0.2:
GET /test_score/_search
{"query": {"boosting": {"positive": {"term": {"content": {"value": "elasticsearch"}}},"negative": {"term": {"content": {"value": "like"}}},"negative_boost": 0.2}}
}运行结果:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.6489038,"hits" : [{"_index" : "test_score","_type" : "_doc","_id" : "1","_score" : 0.6489038,"_source" : {"content" : "we use Elasticsearch to power the search"}},{"_index" : "test_score","_type" : "_doc","_id" : "2","_score" : 0.17427702,"_source" : {"content" : "we like elasticsearch"}}]}
}
查询条件1,negative_boost为0.8:
GET /test_score/_search
{"query": {"boosting": {"positive": {"term": {"content": {"value": "elasticsearch"}}},"negative": {"term": {"content": {"value": "like"}}},"negative_boost": 0.8}}
}运行结果:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.6971081,"hits" : [{"_index" : "test_score","_type" : "_doc","_id" : "2","_score" : 0.6971081,"_source" : {"content" : "we like elasticsearch"}},{"_index" : "test_score","_type" : "_doc","_id" : "1","_score" : 0.6489038,"_source" : {"content" : "we use Elasticsearch to power the search"}}]}
}
这篇关于es中相关性和相关性算分(explain,boosting)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









