本文主要是介绍Learning to Collaborate: Multi-Scenario Ranking via Multi-Agent Reinforcement Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
总结
多场景(tb主搜、店铺搜)rank,每个场景1个actor。整体架构:2个communication component(lstm),1个critic,2个actor。用公共的critic来控制协调,用lstm来保证actor可以获取之前的trajectory来学习
细节
L2R:point-wise, pair-wise, list-wise
DDPG,actor-critic:actor: a t = μ ( s t ) a_t = \mu(s_t) at=μ(st),critic: Q ( s t , a t ) Q(s_t, a_t) Q(st,at)
DRQN,partially-observable,rnn对前面的obs编码,预测 Q ( h t − 1 , o t , a t ) Q(h_{t - 1}, o_t, a_t) Q(ht−1,ot,at)而不是 Q ( s t , a t ) Q(s_t, a_t) Q(st,at)
MARL:多个agent,同时take action。fully cooperation agents & fully competitive agents
整体架构
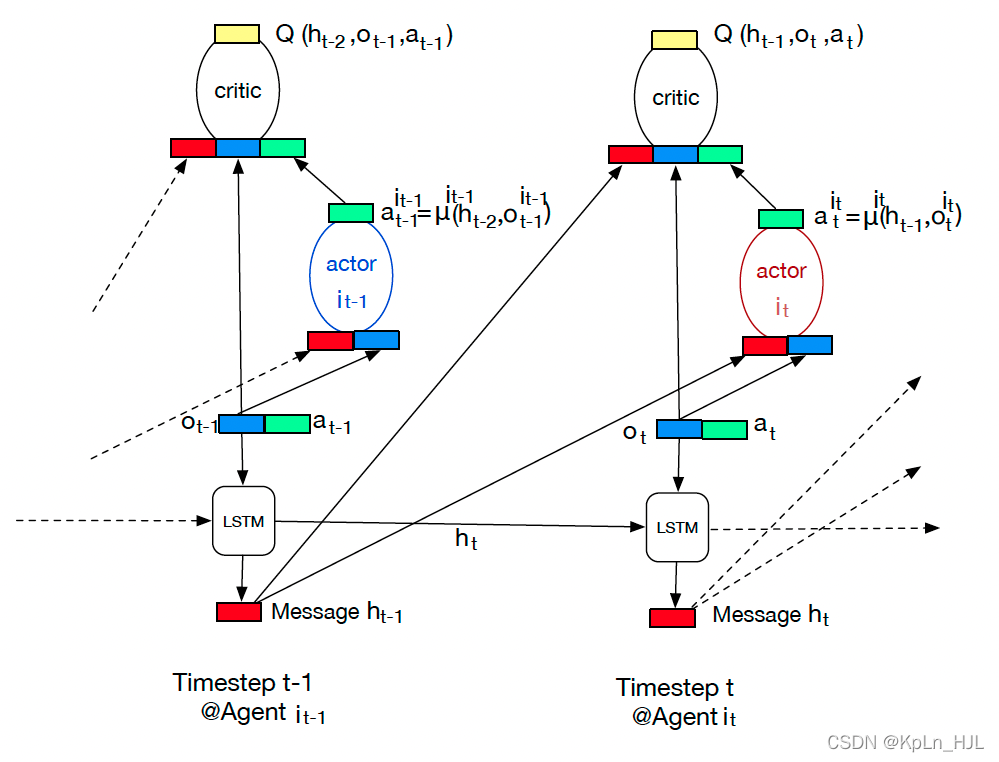
公用的critic,单独的actor,单独的communication component(lstm),lstm的 x t x_t xt是当前场景下的 [ o t , a t ] [o_t, a_t] [ot,at]
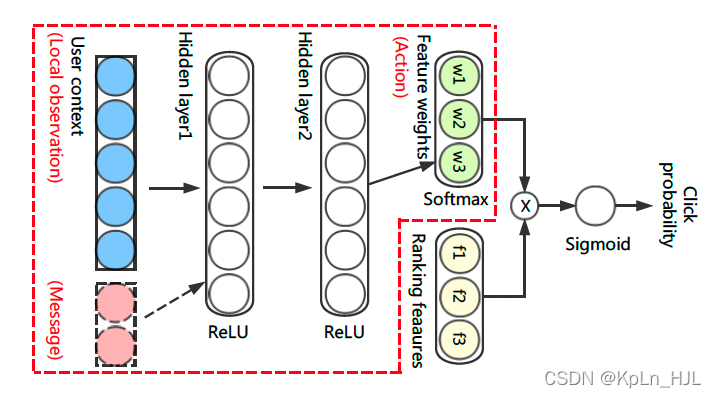
actor架构
实验
评估指标:GMV gap, G M V ( x ) − G M V ( y ) G M V ( y ) \frac{GMV(x) - GMV(y)}{GMV(y)} GMV(y)GMV(x)−GMV(y)
GMV/Gross Merchandise Volume,商品交易总额
这篇关于Learning to Collaborate: Multi-Scenario Ranking via Multi-Agent Reinforcement Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






