collaborate专题
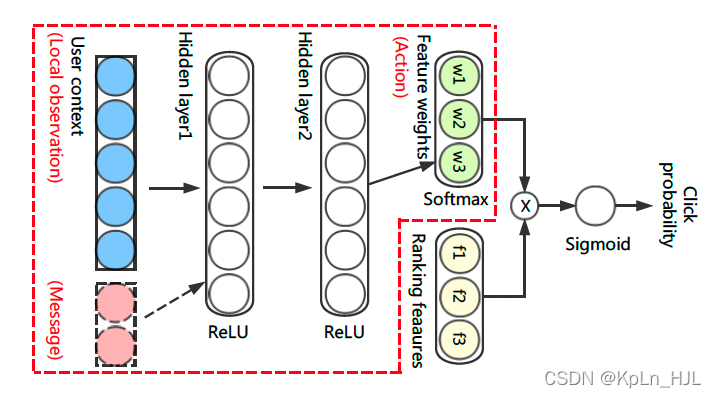
Learning to Collaborate: Multi-Scenario Ranking via Multi-Agent Reinforcement Learning
总结 多场景(tb主搜、店铺搜)rank,每个场景1个actor。整体架构:2个communication component(lstm),1个critic,2个actor。用公共的critic来控制协调,用lstm来保证actor可以获取之前的trajectory来学习 细节 L2R:point-wise, pair-wise, list-wise DDPG,actor-critic:ac