本文主要是介绍以商业视角解析数据驱动,神策 2022 数据驱动大会发布全新数字化闭环产品方案...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!



10 月 26 日,神策 2022 数据驱动大会在北京丽亭华苑酒店举办。大会以“用科学重塑营销”为主题,商业模式创新领域知名作家亚历山大·奥斯特瓦德(Alexander Osterwalder)、神策数据创始人 & CEO 桑文锋、神策数据联合创始人 & CTO 曹犟、小米集团互联网业务部副总经理 & 电视与视频业务部总经理王栋、无限极(中国)有限公司 DIT 副总裁杨俊等 50+ 知名专家发表主题演讲,共同分享并探讨科学方法在企业数字化营销场景中的价值释放。
本届大会以亚历山大·奥斯特瓦德(Alexander Osterwalder)的主题演讲《打造战无不胜的企业》拉开帷幕,桑文锋从商业视角阐述了“数据驱动为什么是有效的”,重新解读“商业模式画布 + 数据闭环方法论”;曹犟完整介绍了神策全新的数字化闭环产品方案。在 26 日下午场的金融专场,以及 27 日的零售专场、互联网专场、企业级专场,将由各行业嘉宾分享企业的实践案例。
追本溯源:数据驱动为什么是有效的
神策对商业本质的思考,源自对“数据驱动为什么是有效的”这一问题的探究。
神策的使命是帮助客户实现数据驱动。桑文锋介绍,成立七年来,我们一直在解答一个问题:数据驱动为什么是有效的?我们从不同视角进行本源探究,这确保了神策做事的底层逻辑的正确性。
在耳熟能详的楚汉争霸、草船借箭历史故事中,我们看到了数据思维的影子;科学方法的视角让我们更近一步,它主要包含:观察与统计、标准化与流程化、假设与检验,这极好地映射了神策所倡导的数据理念,如“数据源很重要”等。
然而究其根本,神策是要帮助客户实现商业价值,对企业商业模式的深入、透彻的认知,是神策真正给客户带来价值的前提。
亚历山大·奥斯特瓦德(Alexander Osterwalder)是《商业模式新生代》的作者,也是商业模式画布(Business Model Canvas)的创造者。受神策之邀,他在本届大会上对商业模式画布进行了全面解读,并与桑文锋就商业话题展开讨论。
深谈商业模式画布,“战无不胜”关键有三
亚历山大·奥斯特瓦德(Alexander Osterwalder)认为,战无不胜的企业有三大特点:第一,不断地重塑自我,企业的产品、服务、客户关系、商业模式始终处于重塑中。第二,打造具有卓越竞争力的商业模式,而非仅聚焦在产品的打磨上。第三,不断打破行业界限。
在演讲中,他围绕企业的探索(Explore)和开拓(Exploit)、商业模式、创新文化三方面阐述了如何让企业“战无不胜”。
企业的探索和开拓,即企业的探索未来与经营当下。亚历山大·奥斯特瓦德(Alexander Osterwalder)认为,企业要同时兼顾两者:创业源于 idea,在明确了产品与服务、价值主张和可行的商业模式后,企业便开始着手未来扩展。整个过程是凌乱且非常具有挑战的,而商业模式画布能够很好地兼顾企业的探索和开拓。
他详解到,商业模式画布可以帮助企业评估和改进业务,并能够进行想法验证、推出或迭代新的业务。商业模式画布分为九大模块,包括前台(价值主张、客户关系、渠道通路、客户细分)、中台(重要伙伴、关键业务、核心资源)、底座(成本结构、收入来源)三部分,对这三部分不断的调整,可以改变商业模式。对此,他列举了国内外的大量实例。

针对企业的创新文化,亚历山大·奥斯特瓦德(Alexander Osterwalder)强调,新的商业模式总是存在一定风险性。他建议,当我们产生新的商业模式、新的产品与服务、新的价值主张等 idea 时,不应直接落地执行,而是要对 idea 进行低成本的反复验证和迭代,以达到最好的效果。在这一过程中,“企业掌握的数据越多,idea 正确的几率就越大,落地的风险就越小。”
商业视角下的数据闭环方法论
商业是一门技术。《技术的本质》一书中指出,新技术并非无中生有,而是从现存技术中组合出的一组新的要素,技术可以无限构成新的组合。商业亦是如此,由人、资源、环境等多种要素组合,从而实现价值创造。同时,当我们将“商业”视为“技术”时,企业则具备了升级与完善的可能性。
延续亚历山大·奥斯特瓦德(Alexander Osterwalder)对商业模式画布的讲解,桑文锋从“商业模式画布 + 数据闭环方法论”系统阐述了对“商业是一门技术”的认知。
桑文锋认为,目标客群和价值主张是商业模式画布的两个关键环节。目标客群和价值主张都可能处于动态变化中,企业在进行 PMF(Product Market Fit,产品市场匹配)的过程,也是价值主张与目标客群不断动态匹配的过程。
企业的数字化转型,就是围绕 “价值主张”“目标客群”“价值传递方式”的转型,在转型的过程中不断产生新客群、新价值主张、新价值传递方式。值得强调的是,企业的商业模式需要进行度量与验证,因此两者都应该有相对清晰的定义。
神策为企业提供大数据分析和营销科技的产品与服务,于 2020 年正式发布数据闭环方法论 SDAF(Sense 感知—Decision 决策—Action 行动—Feedback 反馈)。在数字化时代,用户分析及用户运营是企业经营中的重要环节:用户分析能够帮助企业精确区分每一个客户所属的客群,并通过用户行为相关数据验证价值主张的有效性。而“数字化用户运营”,则能够帮助企业实现更精准的价值传递。
接下来,围绕用户分析及运营,桑文锋介绍了用户运营策略体系 LTVA,结合用户生命周期阶段和用户价值分层,介绍了用户经营策略落地的方法论体系。这集成了企业商业模式运作逻辑与数字化经营,让数据在企业数字化经营中的价值得以释放。
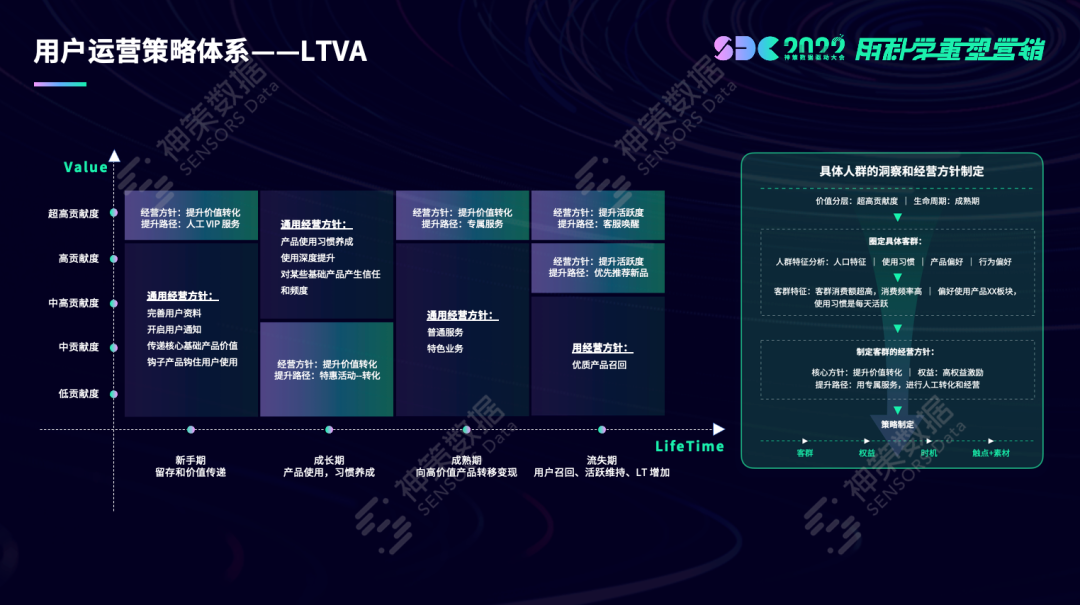
点击放大查看高清大图
神策产品体系演进:全新的数字化闭环产品方案
不止于用户分析,更聚焦用户运营。
在大会现场,曹犟基于 SDAF 数据闭环方法论,完整介绍了神策全新的数字化闭环产品方案。他分享了神策最新的产品认知:
分析,从用户到经营。神策帮助企业实现闭环,不能止于用户行为分析,需要更全面的经营分析。
营销,不止于系统。营销云不是单一的产品,客户的需求要通过平台化 + 生态合作的方式来解决。
围绕全新的数字化闭环产品方案,他从神策数据根基平台、神策分析云、神策营销云三方面展开分享。
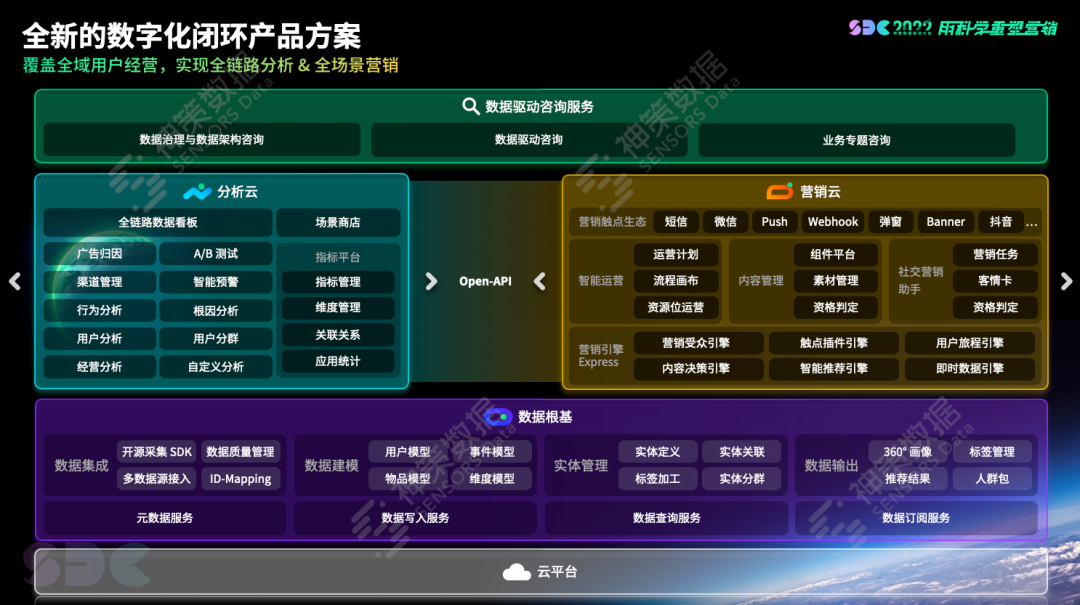
曹犟介绍,神策数界平台是底层数据根基,为神策分析云、神策营销云提供基础数据能力支持,打通企业整体数据,形成完整的数据资产,解决企业面临的数据孤岛问题:开发数据接入框架,有效、可靠地汇集数据,集中管理数据接入工作;进行数据模型再升级,完成事件以外明细模型的支持和多实体支持,并实现用户行为数据与业务经营数据的融合;搭建数据资产视图,通过多种业务视角管理数据资产;增强标签、分群等数据加工能力;提升平台化能力,推出标准 Open API,帮助企业搭建最符合自身业务的数字营销体系,赋能企业的用户经营生态。
在数据闭环方法论 SDAF 的应用中,只有用户行为分析是无法支撑企业完成闭环的,尤其当企业拥有众多业务系统时,闭环的关键在于多业务系统与用户的整体打通和全链路的联通分析。曹犟表示,基于该认知,神策在过去服务数千企业的经验基础上,不断升级、完善了全链路经营分析闭环,持续扩大神策分析云能力矩阵,不仅包括公私域流量的打通,还包括用户分析能力的增强、经营分析、指标平台、科学实验等的升级。
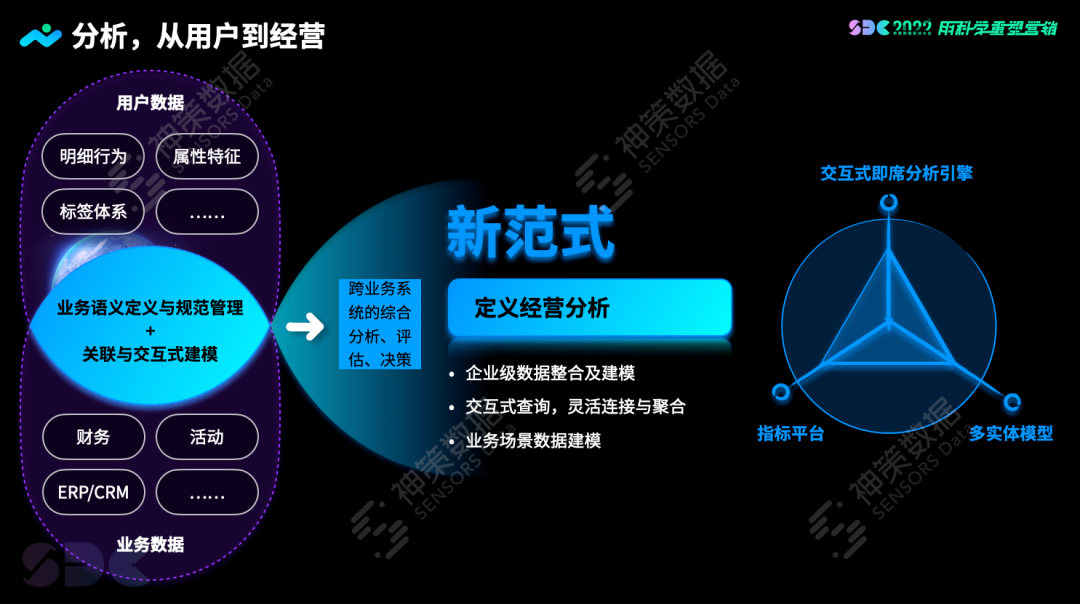
神策重新了定义经营分析。曹犟表示,经营分析后链路场景较复杂,将数据模型进化成多实体模型,发挥强大的查询引擎 + 自定义业务分析 + 复用用户行为分析模型的组合能力,基于最细粒度数据进行 adhoc 查询,可满足企业探索性质的查数需求。
“营销云是一个业务系统,需要贴合客户的实际业务场景,以平台化 + 分层设计撬动场景发挥价值主张。”他讲到,神策营销引擎 Express 经过一年的打磨和沉淀已经完成了再次升级,基于各个行业的丰富营销场景抽象出六大能力,覆盖营销场景建设中最底层、最通用的环节和要素,并对外提供 Open API,依托强大的平台化能力和三方共建的开放生态,与业内优质合作伙伴一起给客户创造价值。
然后,他从 SCMS、SCRM、SLink 三个场景讲述了神策营销应用的优秀实践,进一步强调了“营销,不止于系统”这一观点。
演讲最后,曹犟分享了神策数据的技术演进与贡献:践行积极回馈开源社区的承诺;迭代混合部署能力,满足统一运维、复用平台、节约资源三大诉求;通过 5 层透明存储与加密解决方案,在认证和权限体系基础之上,实现安全性和便利性较好的平衡;响应国家关键基础设施技术突破的号召,基于全栈信创技术行业解决方案,支持多种国产操作系统、多种国产 CPU 服务器,与各厂商和开源社区共同推动整个行业的信创成熟度。
大会现场正式公布了第六届“星斗奖”获奖名单,并举行颁奖典礼。以下为详细榜单:



下午,神策数据金融行业专场即将开启,明日(10 月 27 日)也会有零售、互联网和企业级三大线上专场同步直播,敬请关注!
✎✎✎
【更多内容】
神策 2022 数据驱动大会参会指南
立即下载!会前物料抢先下载
神策数据第六届“星斗奖”榜单公示
▼ 点击“阅读原文”,观看直播及回放
这篇关于以商业视角解析数据驱动,神策 2022 数据驱动大会发布全新数字化闭环产品方案...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







